Integration & Automation
Prepare for faster disaster recovery: Deploy an Amazon Aurora global database with Terraform (Part 1)
Applications with a global footprint need to withstand infrastructure failures across large areas. If your widely used application becomes unavailable for a long time, your company may experience revenue loss, user dissatisfaction, customer attrition, and loss of a competitive edge.
Traditionally, businesses have had to incur considerable engineering effort and cost to design applications that operate continuously or to recover quickly if there’s a disaster.
Today, Amazon Aurora Global Database is available for globally distributed applications with a single Aurora database spanning multiple AWS Regions. An Aurora global database replicates your data with no impact on database performance, enables local reads with low latency in each Region, and can provide disaster recovery from Region-wide outages with low recovery time objective (RTO) and recovery point objective (RPO).
It can be time-consuming and error-prone, though, to provision and manage a multi-Region AWS infrastructure manually. You must set up the secondary Region to be identical to the primary Region. The Regions must have the same network topology, IAM roles, database parameters, monitoring, backup configuration, and integration with other AWS services. After you do all this, you can promote the secondary Region to take over the read and write workload if there is a failure in the primary Region. But any inconsistencies introduced during manual setup can lead to performance issues, workload incompatibilities, and other anomalous behavior when you switch from your primary Region.
In this post, I walk through deploying an Aurora global database automatically using the Terraform Amazon Aurora module.* This module was published by the AWS Infrastructure and Automation team, which develops automated reference deployments known as AWS Quick Starts. The Terraform Amazon Aurora module provisions and manages an Aurora global database across multiple AWS Regions in a repeatable and predictable manner.
For those of you who already have an Aurora global database cluster that was deployed manually, I also discuss how to transition the management of your cluster to this Terraform module. When you make this transition, the primary and secondary Regions get in sync if they weren’t, and then they stay in sync automatically as you make changes in the future.
In Part 2 of this post (Disaster recovery: 3 failover scenarios for your Amazon Aurora global database with Terraform), I walk through managing an Aurora global database after a failover event using this Terraform module.
* The Terraform Amazon Aurora module is in alpha state and will undergo significant changes. As of this writing, this module uses mainly the primary AWS provider. It’s expected to change to use the Terraform AWS Cloud Control Provider.
| About this blog post | |
| Time to read | ~10 min. |
| Time to complete | ~60 min. (including deployment) |
| Cost to complete | ~$2 |
| Learning level | Advanced (300) |
| AWS services | Amazon Aurora Global Database
Amazon CloudWatch AWS Key Management Service (AWS KMS) |
Architecture overview
The following diagram shows the architecture that you will set up in this walkthrough.
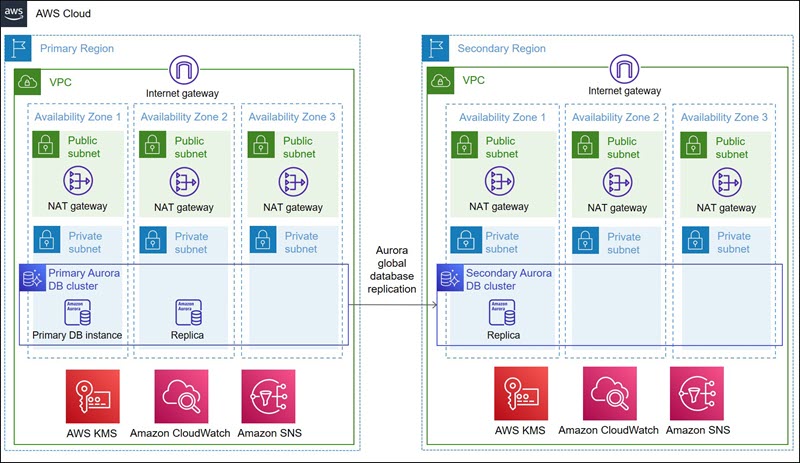
The Terraform Amazon Aurora module provisions and configures the network infrastructure and all the components shown in the diagram, including the following:
- A highly available architecture that spans two AWS Regions and, within each Region, three Availability Zones.
- Within each Region, a virtual private cloud (VPC) that’s configured with public and private subnets, according to AWS best practices, to provide you with your own virtual network on AWS.
- In the public subnets, managed network address translation (NAT) gateways to allow outbound internet access for resources in the private subnets.
- In the private subnets, an Aurora global database (DB) cluster in a security group spanning both AWS Regions. The primary Aurora DB cluster is set up with a primary DB instance and an Aurora replica in the primary AWS Region. The secondary Aurora DB cluster is set up with one Aurora replica in the secondary AWS Region.
- Customer managed keys that are generated using AWS Key Management Service (AWS KMS) to enable encryption at rest for the Aurora DB cluster.
- Amazon CloudWatch alarms to monitor key CloudWatch metrics, such as CPUUtilization, FreeableMemory, FreeLocalStorage, and send notifications using Amazon Simple Notification Service (Amazon SNS).
- Amazon Relational Database Service (Amazon RDS) event notification for the Aurora DB cluster to send notifications using Amazon SNS when an important event such as failover or failure is generated.
- Custom Aurora DB cluster parameter groups and DB parameter groups with some frequently used configuration parameters.
The Terraform Amazon Aurora module provides two deployment options:
- Deploy an Aurora global database into new VPCs. This option builds a new AWS environment consisting of the VPCs, subnets, NAT gateways, security groups, and other infrastructure components across two AWS Regions. It then deploys an Aurora global database in these new VPCs.
- Deploy an Aurora global database into existing VPCs. This option deploys an Aurora global database in your existing AWS infrastructure across two Regions. To use this option, your VPCs need to have at least three private subnets in different Availability Zones. You supply the private subnet IDs for your primary and secondary AWS Regions directly to your Aurora Terraform child module.
This blog post walks you through the procedure to deploy an Aurora global database into new VPCs. Some of the AWS resources deployed by the module incur costs for as long as they are in use.
Prerequisites
This blog post assumes that you’re familiar with Terraform, GitHub, and Git commands.
For this walkthrough, you need the following:
- An AWS account. If you don’t have an account, sign up for one at http://thinkwithwp.com.
- A Terraform Cloud account. If you don’t have an account, sign up for a free tier at https://www.terraform.io/cloud.
One-time setup
A Terraform Cloud workspace contains everything Terraform needs to manage a given infrastructure collection, including configuration, state files, variable values, credential, and secrets. Separate workspaces in Terraform Cloud function as separate working directories when working with Terraform locally.
Perform the following one-time setup to set up a Terraform workspace so that you can later deploy the Terraform Amazon Aurora module.
- Create a Terraform organization, which is a shared space for teams to collaborate in Terraform Cloud.
- Install Terraform on your workstation.
- Configure Terraform Cloud API access on your workstation by running
terraform loginin the terminal window. - Install and configure AWS Command Line Interface (AWS CLI) on your workstation.
- Install git on your workstation.
- Clone the aws-ia/terraform-aws-rds-aurora repository to your workstation by running the following command in your terminal window.
This command creates a directory named terraform-aws-rds-aurora under your current directory, referred to as <TF_STAGING_DIR> in this blog post.
- Set up a Terraform workspace by running the following commands in your terminal window.
Walkthrough: Deploy an Aurora global database using Terraform
- Decide which Aurora DB engine you want to use and in which AWS Regions. Support for this feature varies by Aurora database engine and version. For the complete list of supported features, see Aurora global databases.
- Open the
<TF_STAGING_DIR>/terraform-aws-rds-aurora/deploy/variables.tffile, and review the Terraform variables and their default values. By default, the Terraform Amazon Aurora module deploys an unencrypted Aurora PostgreSQL-compatible provisioned cluster in a single Region. - Override the default values by creating a file with the extension
.auto.tfvarsin the<TF_STAGING_DIR>/terraform-aws-rds-aurora/deploy/directory and specifying the variable values. For this blog post, you would create the file<TF_STAGING_DIR>/terraform-aws-rds-aurora/deploy/terraform.auto.tfvarsas follows:
These variables create an encrypted Aurora PostgreSQL-compatible global database with two instances in the primary Region (us-east-2 by default) and one instance in the secondary Region (us-west-2 by default). If you want to set up two instances in the secondary Region similar to the primary Region, you can append secondary_instance_count = 2 to your file.
- Create VPCs, and deploy the Terraform Amazon Aurora module by running the following commands in your terminal window:
It takes about 35 minutes for Terraform to create all the AWS resources across the two AWS Regions. After the command completes, you see output similar to the following:

- Sign in to the AWS Management Console, and open the Amazon RDS console. Choose Databases in the left navigation bar. Verify that an Aurora global database is set up with a primary cluster running in us-east-2 and a secondary cluster running in us-west-2, as shown here:

Transition the management of an Aurora global database to Terraform
If you already have an Aurora global database cluster that was deployed manually, you may want to transition the management of your cluster to Terraform. When you make this transition, you check whether the secondary Region is set up to be identical to the primary Region, and you remediate any inconsistencies by pushing the required updates to make the Regions identical. Then, as you make changes in the future, Terraform automatically applies your changes consistently across AWS Regions to keep the Regions in sync.
You have two options for transitioning your Aurora global database’s management to Terraform: do it slowly or all at the same time.
Option 1: Transition slowly
With the slow-transition option, you can manage your Aurora global database using Terraform without incurring downtime for the transition.
The Terraform Amazon Aurora module creates several AWS resources. Follow the process for importing Terraform resources to import your AWS resources to Terraform state for all the resource configurations specified in the Terraform Amazon Aurora module.
Option 2: Transition all at the same time
Transitioning all at the same time requires some downtime for your application.
- Take a maintenance window for your application, shut down all writes to your Aurora global database, and create a DB cluster snapshot.
- Deploy a new Aurora global database cluster using the Terraform Amazon Aurora module. Specify the snapshot name or ARN using the
snapshot_identifierTerraform variable. This restores your Aurora cluster snapshot while creating a new Aurora global database cluster. - Point your application to this new cluster.
- (Optional) Delete the old Aurora global database cluster.
Cleanup
Some of the AWS resources created by the Terraform Amazon Aurora module incur costs as long as they are in use. When you no longer need the resources, clean them up as follows.
- Delete the Aurora global database cluster along with the VPCs by running the following commands in your terminal window:
The deletion of AWS KMS resources fails with the following error:

You get this error because the prevent_destroy lifecycle policy is specified for these AWS KMS resources in the Aurora Terraform configuration file. All the backups for an encrypted Aurora cluster are also encrypted using the same AWS KMS key. So in a production environment, retain these AWS KMS keys even after deleting the DB cluster. Then you can restore the encrypted backups if needed in the future.
- Delete these AWS KMS resources in the Terraform state to make Terraform “forget” these objects. Do this by running the following commands in your terminal window.
- Run
terraform destroy --auto-approveagain. This command deletes all the AWS resources set up by the Terraform Amazon Aurora module.
Conclusion
In this post, I walked through using the Terraform Amazon Aurora module to automate the deployment of an Aurora global database across multiple AWS Regions. I also explained how and why you might transition the management of an existing Aurora global database to this Terraform module. By using infrastructure-as-code software, such as Terraform, you save time in your AWS deployments, and the resources across multiple AWS Regions are set up consistently, in a repeatable and predictable manner. If there’s a Region-wide outage, your secondary AWS Region can take over the read and write workload when you switch from your primary Region. This architecture can provide disaster recovery from Region-wide outages with low RTO and RPO.
In Part 2 of this post (Disaster recovery: 3 failover scenarios for your Amazon Aurora global database with Terraform), I walk through managing an Aurora global database after a failover event using the Terraform Amazon Aurora module.
I encourage you to go through the paper Disaster Recovery of Workloads on AWS: Recovery in the Cloud and review the resources mentioned in the Further reading section to learn more about planning and testing best practices related to disaster recovery for any workload deployed on AWS.
If you have comments or questions about this blog post, use the following comments section. To submit bug fixes or request enhancements, open a pull request or an issue in the Terraform Amazon Aurora module GitHub repository.
About the author

Arabinda Pani
Arabinda, a principal partner solutions architect specializing in databases at AWS, brings years of experience from the field in managing, migrating, and innovating databases and data platforms at scale. In his role, Arabinda works with AWS Partners to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.