亚马逊AWS官方博客
3M Health Information Systems 如何使用 Amazon Redshift 构建医疗保健数据报告工具
3M Health Information Systems (HIS) 是 3M Health Care 的一个业务单位,它与提供商、付款人和政府机构合作预测和引领不断变化的医疗保健领域。3M 提供医疗保健绩效测量和管理解决方案、分析和战略服务,帮助客户从基于数量的医疗保健转向基于价值的医疗保健,从而节省了数百万美元、提高了提供商绩效和保健质量。3M 的创新软件旨在提高计算机辅助编码、临床文档改进、性能监控、质量结果报告和术语管理的水平。
3M HIS 正在进行一项计划,以将安装在本地或其他云托管提供商处的应用程序迁移到 Amazon Web Services (AWS) 中。3M HIS 已开始迁移到 AWS 中,以利用计算、存储和网络弹性。我们希望建立在一个坚实的基础上,从而帮助我们把更多的精力放在为客户创造价值上,同时也能进行扩展,以支持我们在未来几年预期的业务增长。3M HIS 已经为很多客户处理本质上很复杂的医疗保健数据,需要进行很多复杂的转换才能将数据转换为对分析或机器学习有用的格式。
在审核了很多解决方案后,3M HIS 选择 Amazon Redshift 作为其数据仓库解决方案。我们认为 Amazon Redshift 满足我们的需求;它是一个快速、完全托管的、PB 级数据仓库解决方案,它使用列存储最大限度地减少 I/O、提供较高的数据压缩率并提供快速的性能。我们在开发环境中快速建立集群、构建维度模型、加载数据,并使其能够用于用户数据的基准测试和测试。我们使用提取、转换、加载 (ETL) 工具处理并将各个来源的数据加载到 Amazon Redshift 中。
3M 传统实现
3M HIS 通过此数据仓库处理大量数据。我们从客户处提取医疗保健数据,这些数据表现为数百万程序代码、诊断代码及每个代码的所有相关元数据。传统过程每两周将此数据加载到数据仓库中一次。
对于报告,我们每周发布 1000 多位客户的 25 份静态报告和 6 份静态 HTML 报告。为了提供商业智能报告,我们在传统的关系数据库上构建了供分析用的多维数据集,并提供了这些多维数据集的报告。
随着要处理的数据量不断增加,满足 SLA 的要求是一项挑战。是时候用可根据要处理和执行的数据自动扩展的现代架构和工具来替代我们的 SQL 数据库了。
3M 如何用 Amazon Redshift 实现数据仓库的现代化
选择新解决方案时,首先,我们必须确保我们能够近乎实时地加载数据。其次,我们必须确保解决方案可扩展,因为数据仓库中存储的数据量是现有解决方案的 10 倍。第三,解决方案需要能够在合理的时间内为大量查询提供报告,从而不影响全天候运行的 ETL 处理。最后,我们需要一个可以与完整解决方案所包含的其他分析服务相集成的经济高效的数据仓库。
我们评估了 Amazon Redshift 和 Snowflake 等数据仓库。我们最终选择 Amazon Redshift 是因为它符合前面的标准并且与我们对本地 AWS Managed Services 的偏好一致。而且,我们这么做也是因为 Amazon Redshift 是面向未来的解决方案,能够以经济上可持续的方式跟上业务的增长。
为了构建报告工具,我们将几 TB 的数据仓库迁移到 Amazon Redshift 中。通过 ETL 工作流程将数据处理到 Amazon S3 存储桶中,然后批量复制到 Amazon Redshift 中。AWS 提供的 GitHub 存储库是一系列脚本和实用程序,可帮助我们设置集群并获得 Amazon Redshift 的最佳性能。
我们在实现过程中学习到的重大经验教训
在初始开发期间,我们在将数据加载到 Amazon Redshift 表时遇到挑战,因为我们尝试将 Amazon RDS 暂存实例中的数据加载到 Amazon Redshift 中。进行一些研究后,我们发现,从 Amazon S3 存储桶中批量加载是将大量数据加载到 Amazon Redshift 表中的最佳实践。
第二个挑战是,Amazon Redshift VACUUM 和 ANALYZE 操作阻塞了我们的 ETL 管道,因为这些操作已经融入了 ETL 过程中。在 ETL 处理过程中,我们在 Amazon Redshift 表中执行了频繁的数据加载并执行了很多 DELETE 操作。这两个问题表示,必须频繁执行 VACUUM 和 ANALYZE 操作,导致表在操作持续时间内被锁定并与 ETL 过程发生冲突。在所有加载都完成后触发过程可帮助消除我们遇到的性能问题。VACUUM 和 ANALYZE 最近已实现了自动化,我们希望将来能够防止此类问题的发生。
最后一项挑战是找到一种方法来使用以前已存在于分析服务多维数据集层中的窗口功能,现在,Amazon Redshift 已实现该层的功能。然而,我们需要的大多数窗口功能内置在 Amazon Redshift 中,以便于轻松转换,从而将现有功能转移到 Amazon Redshift 中并提供相同结果。
在转移期间,我们使用 Amazon Redshift 的全面最佳实践指导和调整技术。我们发现,这些能帮助我们设置 Amazon Redshift 集群,以获得最大性能。
新实现的流程图
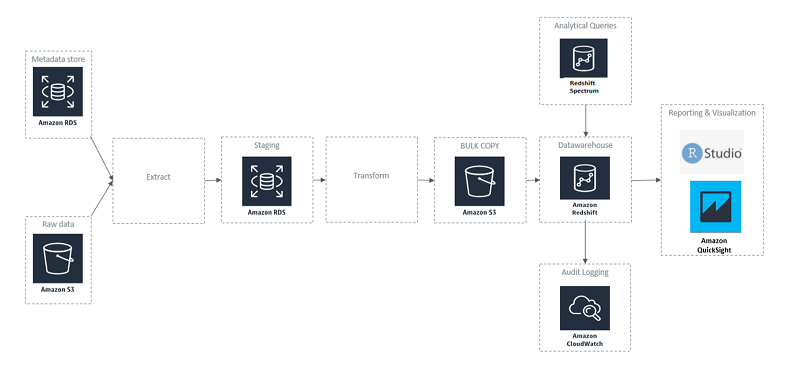
更新实现的优势
使用传统解决方案时,我们的实现变得越来越复杂,我们发现很难支持不断增长的新数据量,我们需要将这些数据合并到数据库中,然后进行近乎实时的报告。对数据执行的报告慢慢的偏离最初的 SLA 要求。使用 Amazon Redshift 时,我们只需要对解决方案进行较少的人工维护和输入便能解决这些问题。首先,它可能会使我们在较长时间内存储较大量的数据。其次,在需要时向集群中添加节点很简单,我们可以在几分钟内使用 Elastic Resize 功能完成。同样地,当成本敏感性成为问题时,我们可以缩减节点。第三,Amazon Redshift 对大型分组数据集的计算分析支持也优于以前的解决方案。通常,我们希望查看最近的数据与历史数据之间的比较。有时候,我们需要查看一年或两年以上的历史数据来排除季节性因素,我们发现,Amazon Redshift 解决方案对于这种类型的操作更加具有可扩展性。
小结
在 3M HIS,我们正在把医疗保健从治疗疾病的系统转换到从一开始就使用准确的健康和临床信息改善健康的系统。3M 拥有近 40 年的临床知识,包括数据管理和疾病分类学到报销和风险调整等,为我们的提供商和付款客户找到提高整个护理过程的结果的解决方案打开了大门。我们帮助客户确保准确而合规的报销,并利用由 AWS 提供支持的 3M 分析功能来改善健康系统和健康计划性能,同时降低成本。
关于作者
 Dhanraj Shriyan 是 3M Health Information Systems 的企业数据架构师,拥有芝加哥西北大学预测分析学硕士学位。他喜欢帮助客户探究他们的数据、提供有价值的见解,并根据客户的需求使用正确的数据库技术实现可扩展的解决方案。他拥有多年在云中和本地构建大型数据仓库商业智能解决方案的经验。目前,他正在 AWS 中探索图形技术和 Lake Formation 服务。
Dhanraj Shriyan 是 3M Health Information Systems 的企业数据架构师,拥有芝加哥西北大学预测分析学硕士学位。他喜欢帮助客户探究他们的数据、提供有价值的见解,并根据客户的需求使用正确的数据库技术实现可扩展的解决方案。他拥有多年在云中和本地构建大型数据仓库商业智能解决方案的经验。目前,他正在 AWS 中探索图形技术和 Lake Formation 服务。