亚马逊AWS官方博客
在 AWS 上使用 GraphQL 实现 API 现代化时的考虑事项
GraphQL 的工作原理
想象一下,您使用 GraphQL 为电子商务应用程序实施一个 API 前端。如图 1 所示,您的电子商务系统后端中有各种不同的服务,可以通过不同的技术进行访问。例如,用户资料数据存储在高度可扩展的 NoSQL 表中。可以通过 REST API 来访问订单。当前库存信息可通过 AWS Lambda 函数进行检查,而定价信息位于 SQL 数据库中。

图 1.GraphQL 的工作原理
如果不使用 GraphQL,客户端应用程序必须对每项服务单独进行多次调用。由于每项服务都通过不同的 API 端点公开,因此从客户端访问数据的复杂性会显著地提升。为了获取数据,您必须执行多次调用。在一些情况下,您可能会过度提取 数据,因为数据来源会发送整个有效负载,包括您可能不需要的数据。在其他一些情况下,您可能对数据的提取量不足,因为单个数据来源无法提供所需的全部数据。
GraphQL API 将来自所有这些不同服务的数据组合成单一有效负载,该有效负载由客户端根据其需求进行定义。例如,智能手机的屏幕比桌面应用程序小。智能手机应用程序需要的数据可能较少。数据会自动从多个数据来源中检索。客户端只看到一个构造好的有效负载。此有效负载可能从 Amazon DynamoDB 接收用户资料数据,或者从 Amazon API Gateway 接收订单详情。此外,它可能涉及在特定字段中注入来自 AWS Lambda 和 Amazon Aurora 的供货情况和价格数据。
通过使用 GraphQL 对前端 API 进行现代化改造,您可以更快地构建应用程序,因为您的前端开发人员不需要等待后端服务团队为集成而创建新 API。GraphQL 使用单个 API 与来自多个数据来源的数据进行交互,简化了数据访问。这减少了 API 请求的数量和网络流量,提高了应用程序性能。此外,GraphQL 订阅支持在后端与客户端之间进行双向通信。它还支持将数据更新实时发布到订阅客户端。利用更新体育赛事比分、竞价状态等用例,您可以创建有吸引力的实时应用程序。
在 AWS 上运行 GraphQL 的选项
有两个主要选项可以实现在 AWS 上运行 GraphQL,一种是使用 AWS AppSync 在 AWS 上完全托管,另一种是自我管理型 GraphQL。
I.使用 AWS AppSync 进行完全托管
运行 GraphQL 的最简单直接的方法是使用 AWS AppSync,这是一项完全托管的服务。AWS AppSync 负责处理安全地连接 Amazon DynamoDB 等数据来源以及开发 GraphQL API 这样的繁重工作。您可以选择用于实施常见 GraphQL API 模式的代码模板,针对这些数据来源编写业务逻辑。您的 API 还可以与其他 AWS AppSync 功能(例如缓存)进行交互,以提高性能。可使用订阅来支持实时更新,并使用客户端数据存储使离线设备保持同步。AWS AppSync 将自动扩展,以支持各种 API 请求负载。您可以在 AWS AppSync 功能页面中找到更多详细信息。

图 2.电子商务系统实施中的 AWS AppSync
让我们仔细了解一下在电子商务系统中使用 AWS AppSync 的此 GraphQL 实施。在图 2 中,已经创建了一个架构,用于定义所需 GraphQL API 的类型和功能。可以将架构绑定到解析程序函数。可以创建架构来镜像现有数据来源,也可以使用 AWS AppSync 根据架构定义自动创建表。您还可以使用 GraphQL 功能实现数据发现,而无需查看后端数据来源。
建立架构定义后,可以为 AWS AppSync 客户端配置操作请求,例如查询操作。客户端向 GraphQL 代理提交操作请求以及身份上下文和凭证。GraphQL 代理将此请求传递给解析程序,而解析程序会映射和发起针对预配置的 AWS 数据服务的请求有效负载。这些数据服务可以是用于用户资料的 Amazon DynamoDB 表、用于库存服务的 AWS Lambda 函数,等等。解析程序在单个 API 调用中,发起对其中一个服务或所有服务的调用。这样可以最大限度地减少 CPU 周期和网络带宽需求。接下来,解析程序将响应返回给客户端。此外,客户端应用程序可以根据需要更改代码中的数据要求。AWS AppSync GraphQL API 将相应地动态映射数据请求,从而加快原型设计和开发速度。
II.自我管理的 GraphQL
如果您希望灵活地选择特定的开源项目,则可以选择运行自己的 GraphQL API 层。Apollo、graphql-ruby、Juniper、gqlgen 和 Lacinia 是一些流行的 GraphQL 实施。您可以利用 AWS Lambda 或 Amazon Elastic Container Service(ECS)和 Amazon Elastic Kubernetes Services(EKS)等容器服务来运行 GraphQL 开源实施。这使您能够精细地调整 API 的运营特征。
在 AWS Lambda 上运行 GraphQL API 层时,您可以利用自动扩缩功能的无服务器优势,只按实际用量付费,且不必管理服务器。您可以使用 Amazon ECS、EKS 或 AWS Lambda 创建私有 GraphQL API,该 API 只能从您的 Amazon Virtual Private Cloud(Amazon VPC)进行访问。通过 Apollo GraphQL 开源实施,您可以创建一个联合身份 GraphQL,这允许您将来自多个微服务的 GraphQL API 组合成单个 API,如图 3 所示。Apollo GraphQL Federation with AWS AppSync(Apollo GraphQL Federation 与 AWS AppSync 结合使用)博文展示了如何将 AWS AppSync API 与 Apollo Federation 网关集成的具体示例。它使用符合规范的查询和指令。
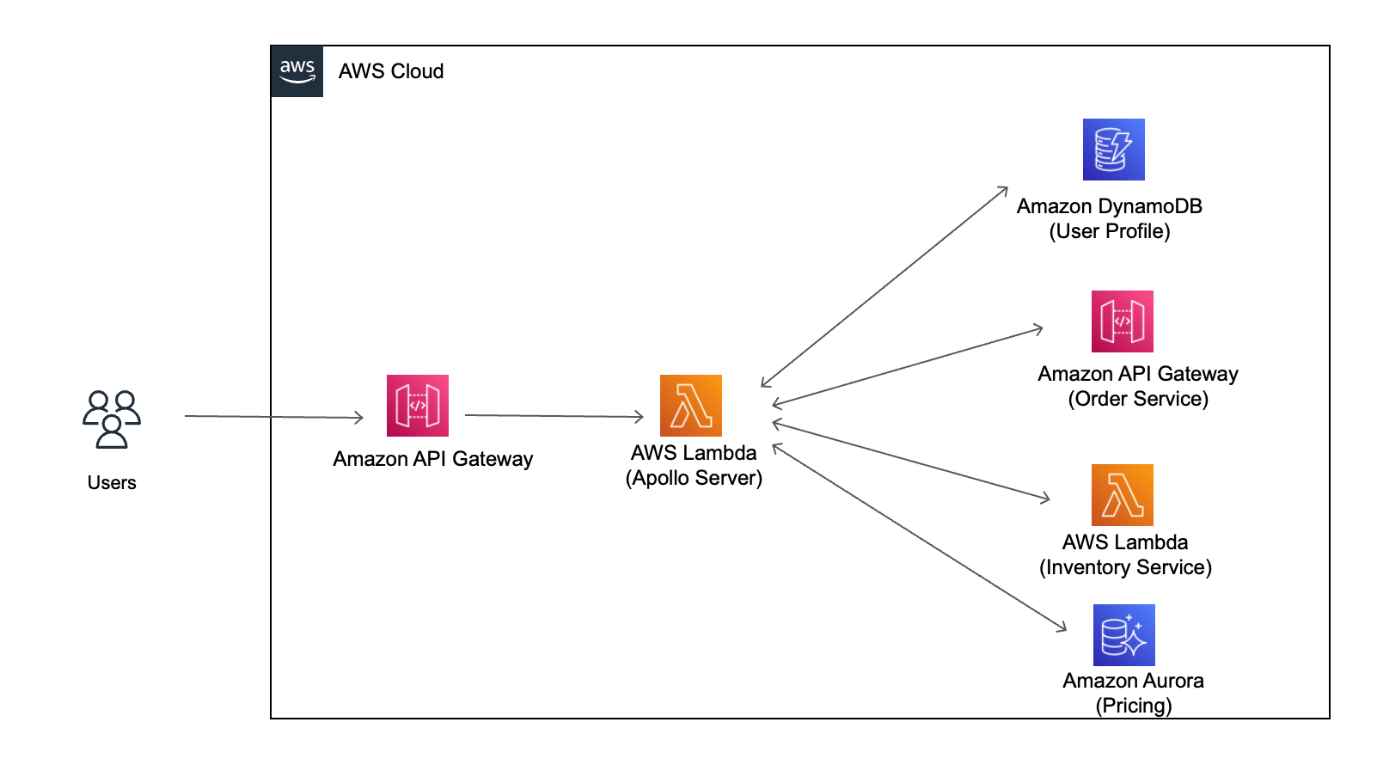
图 3.AWS Lambda 上的 Apollo GraphQL 实施
选择自我管理的 GraphQL 实施时,需要花费时间来编写非业务逻辑代码以连接数据来源。您必须实施授权和身份验证,并集成其他常用功能。这可以是用于提高性能的缓存、用于支持实时更新的订阅以及用于使离线设备保持同步的客户端数据存储。由于这些职责,您得减少专注于应用程序业务逻辑的时间。
同样,开源 GraphQL 实施的后端开发团队和 API 操作员必须预置并维护他们自己的 GraphQL 服务器。请记住,即使使用无服务器模型,API 开发人员和操作员仍需要负责对 API 平台服务进行监控、性能优化和故障排除。
结论
使用 GraphQL 对 API 进行现代化,使得您的前端应用程序能够通过一个 API 调用,从多个数据来源仅提取所需的数据。您可以更快地构建现代化的移动和 Web 应用程序,因为 GraphQL 简化了 API 管理工作。您可以灵活地在 AWS Lambda、Amazon ECS 和 Amazon EKS 上运行最符合自己需求的开源 GraphQL 实施。借助 AWS AppSync,您可以快速设置 GraphQL,并通过减少非业务 API 逻辑代码量来加快开发速度。
延伸阅读: