很多企业为满足传统大数据分析T+1的批处理或是实时性的流处理业务场景,往往会选择主流大数据框架Apache Spark结合Amazon Glue和这种完全托管的,无服务器的ETL服务或者Amazon EMR托管大数据平台在亚马逊云上搭建数据湖,但由于目前没有原生基于Amazon Glue实现数据血缘的功能,很多客户需要自己开发或者使用Atlas,但目前Atlas对Spark支持很有限,比如最高只支持到2.4版本,也不支持字段级别的血缘,我们迫切需要找到更优的血缘方案解决Atlas目前的问题。
而针对以上场景,我们会在这篇博客中给出一个开源的解决方案Spline。对比其它开源数据血缘方案,Spline支持Glue和EMR代码级别的血缘包括DataFrame API和SparkSQL, 可以做到从整个数据链路实时捕获追踪血缘。另外Spline还包括支持字段血缘,可以可视化向上向下溯源, 支持Spark Structured Streaming结合最受欢迎的开源数据湖框架如Hudi和Delta Lake,提供统一流批的血缘,同时Spline提供Producer & Consumer API,方便第三方集成和以API形式的二次开发。
本文会带您一步一步地在AWS上部署Spline,提供在Glue和EMR中实现Spark代码级别的血缘,并且结合开源数据湖架构Hudi和Delta Lake来提供批流入湖实例,本文会重点介绍如何使用Spline来捕获,关于使用Glue和EMR的资料相对丰富,可以参考官方文档以及相关博客,本文不再重复。
1. 什么是数据血缘
数据血缘(Data Lineage)又叫做数据起源(Data Provenance) 或者数据家谱(Data Pedigree)。其通常被定义为一种生命周期,主要包含数据的来源以及数据随时间移动的位置。数据血缘是数据治理的最重要组成部分之一,虽然数据目录提供了元数据管理特性和搜索功能,但数据血缘通过更详细地捕捉数据源之间的关系、数据来源以及数据转换和聚合的方式,揭示了数据的生命周期,旨在显示从开始到结束的完整的数据流。数据血缘是理解、记录和可视化数据的过程,因为它从数据源流向消费。这包括数据在整个过程中所经历的所有转换:数据是如何转换的,发生了什么变化,以及为什么发生了变化。有助于数据工程师查看和跟踪数据流,并理解特定指标和数据集的质量以及来源,了解数据集之间的依赖关系,当出现问题时,更好的评估对数据链路的影响并快速定位问题以及修复。
1.1 数据血缘的应用场景
在数据的处理过程中,从数据源头到最终的消费数据,每个环节都可能会导致我们出现数据质量的问题。比如我们数据源本身数据质量不高,在后续的处理环节中如果没有进行数据质量的检测和处理,那么这个数据信息最终流转到我们的目标表,它的数据质量也是有问题的。也有可能在某个环节的数据处理中,我们对数据进行了一些不恰当的处理,导致后续环节的数据质量变得糟糕。因此,对于数据的血缘关系,我们要确保每个环节都要注意数据质量的检测和处理,那么我们后续数据才会有优良的基因,即有很高的数据质量。
数据血缘队对整个数据上下游的用户有不同视角,例如数据工程师和ETL开发人员一般需要验证、自信地处理原始数据包括data cleaning, de-duplicate, data masking, upsert,sorting, aggregation等等操作,识别上游依赖项和下游使用,提高数据质量,评估对服务影响,提高 Data Pipeline SLA和优化调度。对于业务用户和数据平台运维管理部门,他们更关心如何为数据湖消费者建立对数据的信任和透明度, 为数据治理和监管部门提供审计跟踪,如何理解捕获数据源之间的关系,数据经过了哪些关键环节,每个环节是有谁来负责,如何运维排错和故障溯源,如何保证数据安全性和合规性。
2. 什么是Spline
Spline 即 Spark Lineage,是一个专注Spark的数据血缘追踪工具,spline的目标是创建一种简单且高效的方法捕获Spark血缘,同时提供API,方便第三方去扩展和开发。
spline在架构上可以分为四部分
- Spline Server
- Spline Agent
- ArangoDB
- Spline UI
spline server 是 spline的核心。它通过 producer api 接收来自agent的血缘数据,并将其存储在 ArangoDB 中。另一方面,它为读取和查询血缘数据提供了 Consumer API。消费者 API 由spline UI 使用,但也可以由第三方应用程序使用。
spline agent 从数据转换管道中捕获沿血缘和元数据,并通过使用 HTTP API (称为 Producer API) ,以标准格式将其发送到spline server,最终血缘数据被处理并以图的形式存储,并且可以通过另一个 REST API (称为 Consumer API)访问。
ArangoDB 是一个原生多模型数据库,兼有key/value键/值对、graph图和document文档数据模型,提供了涵盖三种数据模型的统一的数据库查询语言,并允许在单个查询中混合使用三种模型。基于其本地集成多模型特性,您可以搭建高性能程序,并且这三种数据模型均支持水平扩展。
Spline UI 是可视化渲染数据血缘的endpoint,可以按application绘制作业的表血缘,字段血缘,以及每一个stage的输入输出schema。

3. Spline 部署
我们采用在EC2上以docker compose的方式容器化部署Spline,需提前安装好Docker和Compose。也可以参考在亚马逊云上部署Spline的详细例子:https://github.com/AbsaOSS/spline-getting-started/tree/main/spline-on-AWS-demo-setup
wget https://raw.githubusercontent.com/AbsaOSS/spline-getting-started/main/docker/docker-compose.yml
wget https://raw.githubusercontent.com/AbsaOSS/spline-getting-started/main/docker/.env
sudo docker-compose up
修改.env确保同VPC内可以访问, 拉起4个组件,分别是Spline UI,图数据库arangoDB,以及Spline server,Agent,其中agent会执行多个测试脚本,结果写入Spline Server

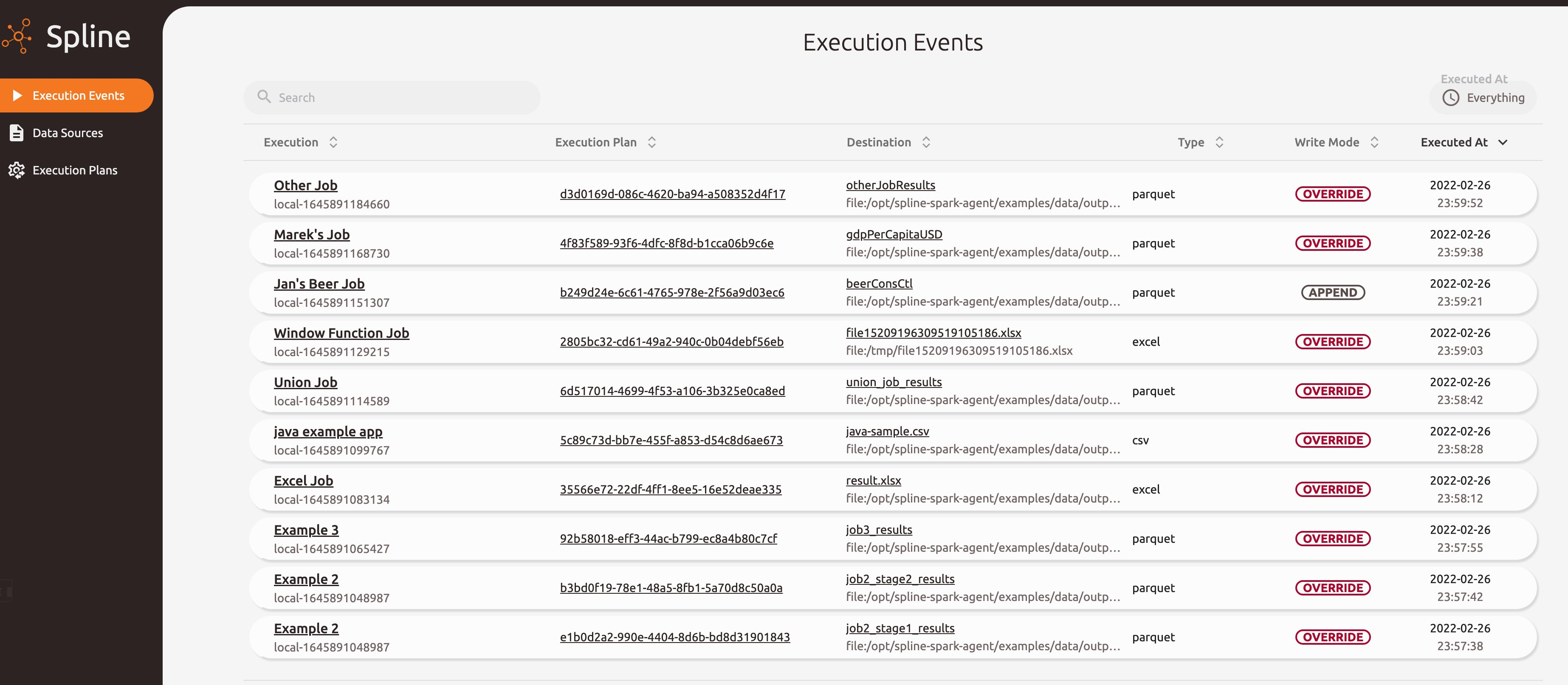
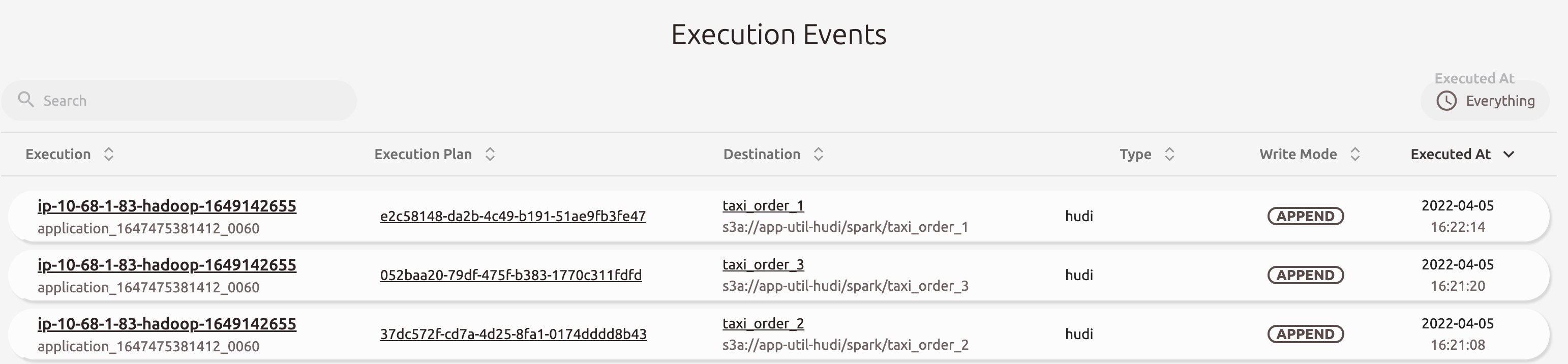
启动后进入spline UI查看,我们看到Spline分为Execution Events,Data Sources,Execution Plans几个部分

点击一个测试生成的Execution event,首先显示的是表血缘

点击链接Table的job查看每一步stage的输入输出

点击任意schema中的字段,显示该字段的上下游字段血缘

Spline捕获血缘的内容还是很充分的,接下来我们在Glue中使用spline尝试血缘捕获
4. 动手实验
4.1 Spline 与 Glue Studio的集成
AWS Glue Studio 是一个新图形界面,可以方便地在 AWS Glue 中创建、运行和监控ETL任务。数据人员可以直观地编写数据转换工作流,并在 AWS Glue 的基于 Apache Spark 的无服务器 ETL 引擎上顺畅运行。您可以在任务的每个步骤中检查架构和数据结果。
4.1.1 首先在Glue studio中通过图形化界面托拉拽一个DAG来建一个ETL Job

4.1.2 然后只需点击Job details,添加Dependent JARS path, 加入我们的Spline Agent Jar文件
s3://aws-virginia-spline-only-jar/za.co.absa.spline.agent.spark_spark-3.1-spline-agent-bundle_2.12-0.6.2.jar

4.1.3 在Advanced properties 添加 Job parameters来制定spline相关参数。
|
Key |
Value |
| 1 |
–conf |
spark.spline.producer.url=http://{Spline_server_IP}:48080/producer –conf spark.spline.mode=REQUIRED —conf spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener |
| 2 |
–enable-glue-datacatalog |
|

4.1.4 点击Save,然后点击Run。 作业执行面成功后我们可以看到血缘被Spline成功捕获
spline event页面

可以看到完美捕获血缘

4.2 Spline 与 SparkSQL on Glue的集成
另外,我也可以通过Glue来创建一个以SparkSQL为主的Job
4.2.1 进入Amazon Glue, 首先在数据库里新建一个数仓 prd_dw

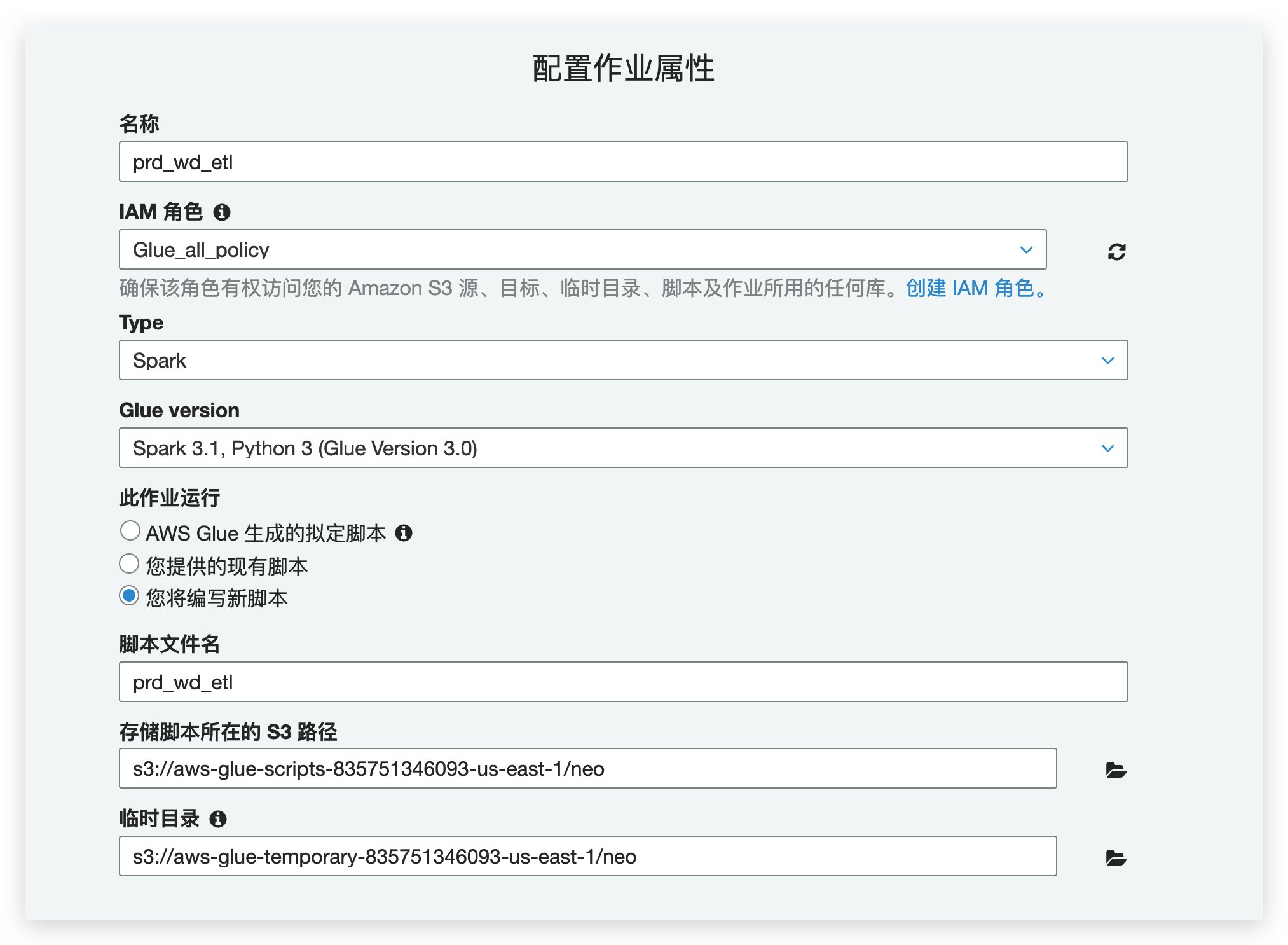
4.2.2 点击作业,然后添加作业
本例我们采用将配置写在代码中来实现血缘捕获

4.2.3,在从属JAR路径选添加jars path

import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql import SparkSession
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
sc.setSystemProperty('spline.mode','REQUIRED')
sc.setSystemProperty('spline.producer.url','http://{Spline_server_IP}:48080/producer')
glueContext = GlueContext(sc)
spark = glueContext.spark_session
spark.conf.set("spark.sql.debug.maxToStringFields",2000)
sc._jvm.za.co.absa.spline.harvester.SparkLineageInitializer.enableLineageTracking(spark._jsparkSession)
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# 以上通用
# src->ods
df=spark.sql("select * from s3.aws_virginia_spline_test_data")
df.write\
.format('parquet')\
.mode('overwrite')\
.option('path','s3://neo-aws-ohio-emr-task-abc/ods_order_a')\
.saveAsTable('prd_dw.ods_order_a')
# ods->dwd
df=spark.sql("select * from prd_dw.ods_order_a where caseid>10009")
df.write\
.format('parquet')\
.mode('overwrite')\
.option('path','s3://neo-aws-ohio-emr-task-abc/dwd_order_a')\
.saveAsTable('prd_dw.dwd_order_a')
# dwd->ads
df=spark.sql("select caseid, count(dAge) as num from prd_dw.dwd_order_a group by caseid")
df.write\
.format('parquet')\
.mode('overwrite')\
.option('path','s3://neo-aws-ohio-emr-task-abc/ads_order_a')\
.saveAsTable('prd_dw.ads_order_a')
job.commit()
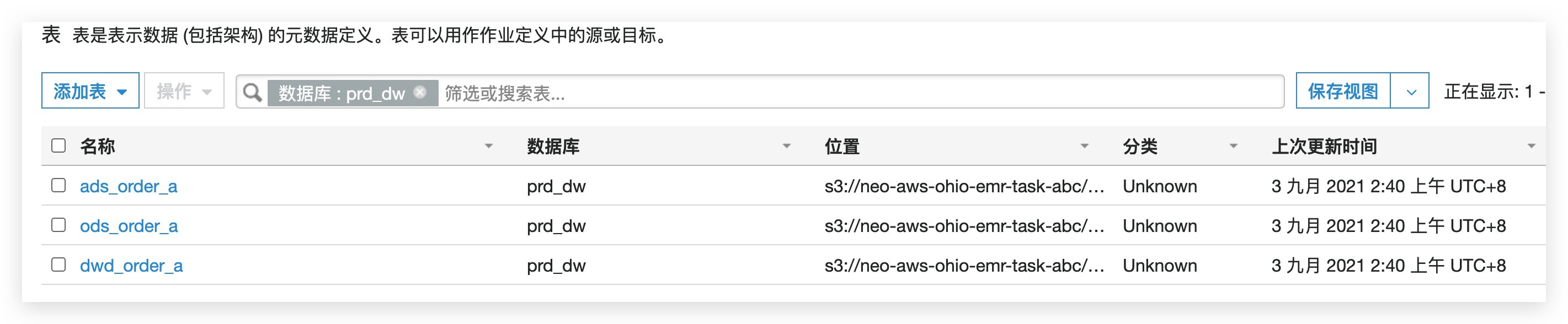
查看glue catalog


我们通过Spline UI界面查看到血缘被捕获成功
4.2.4 查看spline UI 血缘

执行DAG

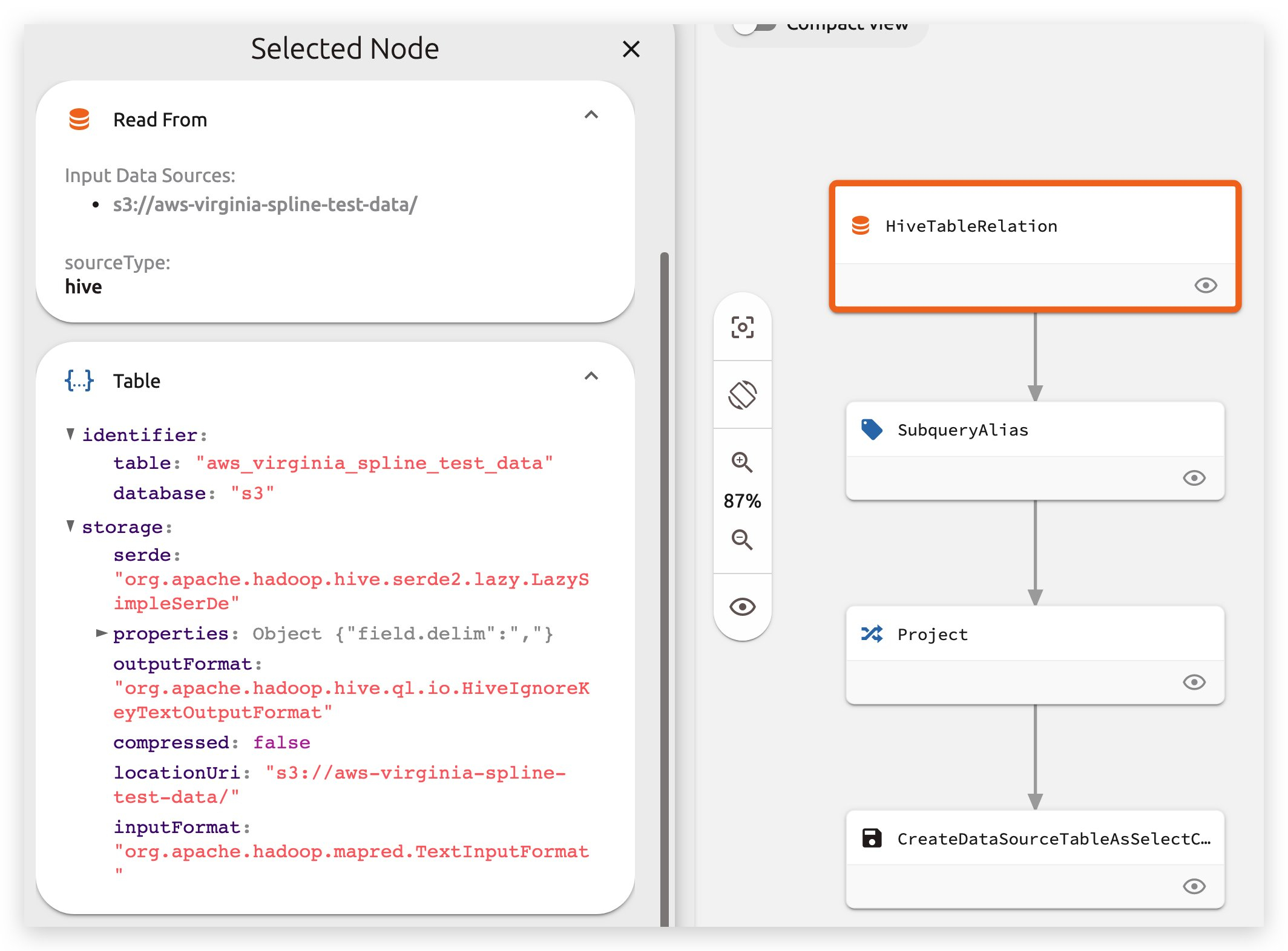
表血缘


字段血缘和每步的schema

4.3 Spline收集Spark Structured Streaming+Delta Lake on Glue的血缘

针对准实时的场景下使用开源Delta Lake结合Amazon Glue的无服务器数据湖架构在企业客户里使用越来越普遍,本例尝试使用spline来统一Delta数据湖中的流和批的血缘。如下图,spline的会通过Agent从数据转换管道ETL工作流中捕获沿血缘,并通过使用 HTTP API (称为 Producer API) ,以标准格式将其发送到spline server,最后Consumer API读取和查询血缘数据。
架构上第一个Job负责从MSK读取原始数据并且把数据以Delta的格式写入原始数据层(raw layer),同时我们会按processing time以年, 月, 天, 小时来分区。数据在进入这一层前没有做数据清洗和处理,并允许重复订单数据,第二个Job从原始数据层读取数据,然后进行数据清洗,实现upsert逻辑然后写入处理层(processed layer)的ODS表供下游消费端查询,这一层类似ODS层, 可以做数据清洗和去重等业务逻辑。同时,我们使用 Spark原生的Run Once trigger特性实现一次性的流式处理,然后停止集群,避免了24*7运行成本。本篇博客主要以第一个红色画框的Job为例子。
4.3.1 新建第一个Job

注意运行程序需要使用到Delta和Spline的两个Jar包。然后向下滚动进入到“安全配置、脚本库和作业参数(可选)”环节,在”Python 库路径”和“从属 JAR 路径”的输入框中分别将前面上传到桶里的两个依赖Jar包的S3路径粘贴进去。如下图所示:(记住,中间要使用逗号分隔)

接下来,在“作业参数”环节,添加三个作业参数。我们需要把 kafka的bootstrap_servers, topic和数据湖S3桶的名称以“作业参数”的形式传给示例程序,以便其可以拼接出Delta数据集的完整路径,这个值会在读写Delta数据集时使用,因为Delta数据集会被写到这个桶里。

以下是第一个Job的脚本示例, 注意目前只可以捕获在Structured Streaming以foreachBatch + DataFrame.write的方式捕获写入的血缘,对原生的writeStream的支持目前正在开发中,具体可以参考:https://github.com/AbsaOSS/spline-spark-agent/issues/41
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
# Import the packages
from delta import *
from pyspark.sql.session import SparkSession
from datetime import datetime
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType
from pyspark.sql.functions import col, from_json, lit
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'bucket_name', 'bootstrap_servers', 'topic'])
##conf 写code里
sc = SparkContext()
sc.setSystemProperty('spline.mode','REQUIRED')
sc.setSystemProperty('spline.producer.url','http://{Spline_server_IP}/producer')
spark = SparkSession.builder.getOrCreate()
spark.conf.set("spark.sql.debug.maxToStringFields",2000)
sc._jvm.za.co.absa.spline.harvester.SparkLineageInitializer.enableLineageTracking(spark._jsparkSession)
glueContext = GlueContext(sc)
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
data_bucket = args['bucket_name']
bootstrap_servers = args['bootstrap_servers']
topic = args['topic']
schema = StructType([ \
StructField("order_id", IntegerType(), True), \
StructField("order_owner", StringType(), True), \
StructField("order_value", IntegerType(), True), \
StructField("timestamp", TimestampType(), True), ])
def insertToDelta(microBatch, batchId):
date = datetime.today()
year = date.strftime("%y")
month = date.strftime("%m")
day = date.strftime("%d")
hour = date.strftime("%H")
if microBatch.count() > 0:
df = microBatch.withColumn("year", lit(year)).withColumn("month", lit(month)).withColumn("day", lit(day)).withColumn("hour", lit(hour))
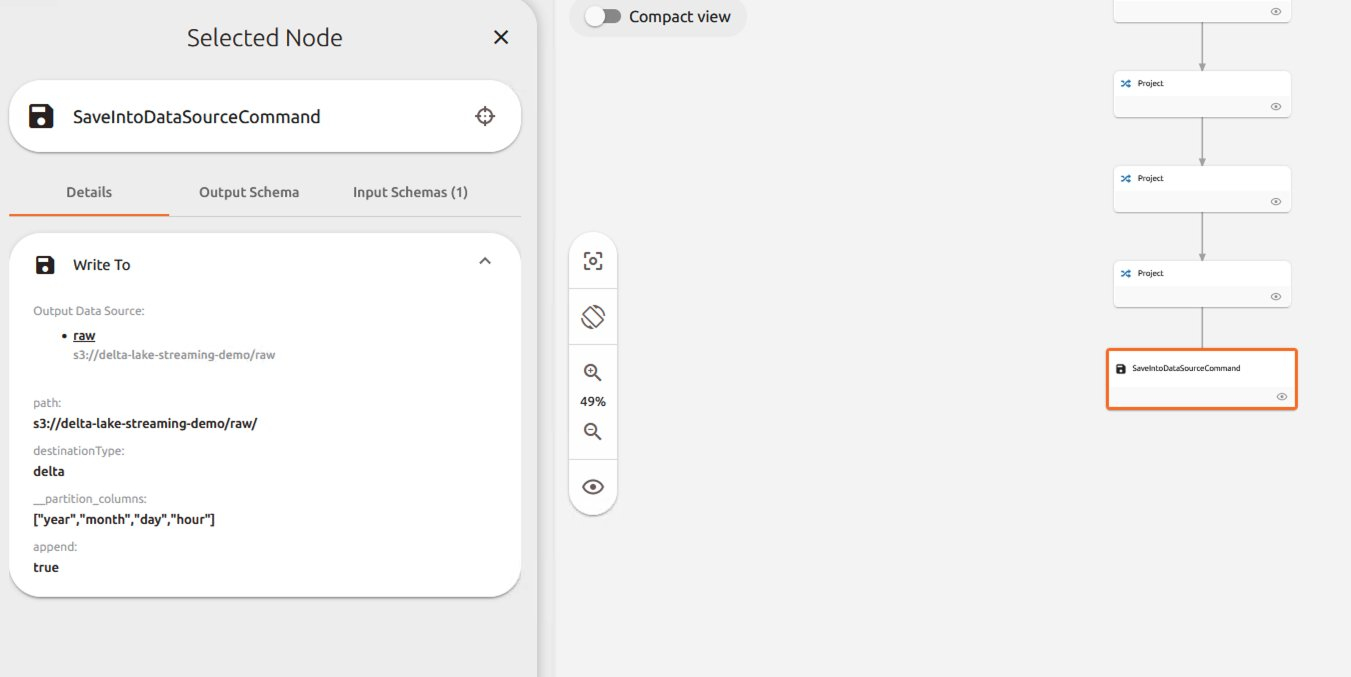
df.write.partitionBy("year", "month", "day", "hour").mode("append").format("delta").save(f"s3://{data_bucket}/raw/")
# Use IAM and SSL for data in transit
options = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "AWS_MSK_IAM",
"kafka.sasl.jaas.config": "software.amazon.msk.auth.iam.IAMLoginModule required;",
"kafka.sasl.client.callback.handler.class": "software.amazon.msk.auth.iam.IAMClientCallbackHandler"
}
# Read Source
df = spark \
.readStream \
.format("kafka") \
.options(**options) \
.option("kafka.bootstrap.servers", bootstrap_servers) \
.option("subscribe", topic) \
.option("startingOffsets", "earliest") \
.option("maxOffsetsPerTrigger", 1000) \
.load().select(col("value").cast("STRING"))
df2 = df.select(from_json("value", schema).alias("data")).select("data.*")
# Write data as a DELTA TABLE
df3 = df2.writeStream \
.foreachBatch(insertToDelta) \
.option("checkpointLocation", f"s3://{data_bucket}/checkpoint/") \
.trigger(processingTime="60 seconds") \
.start()
df3.awaitTermination()
job.commit()
4.3.2 查看spline UI 血缘
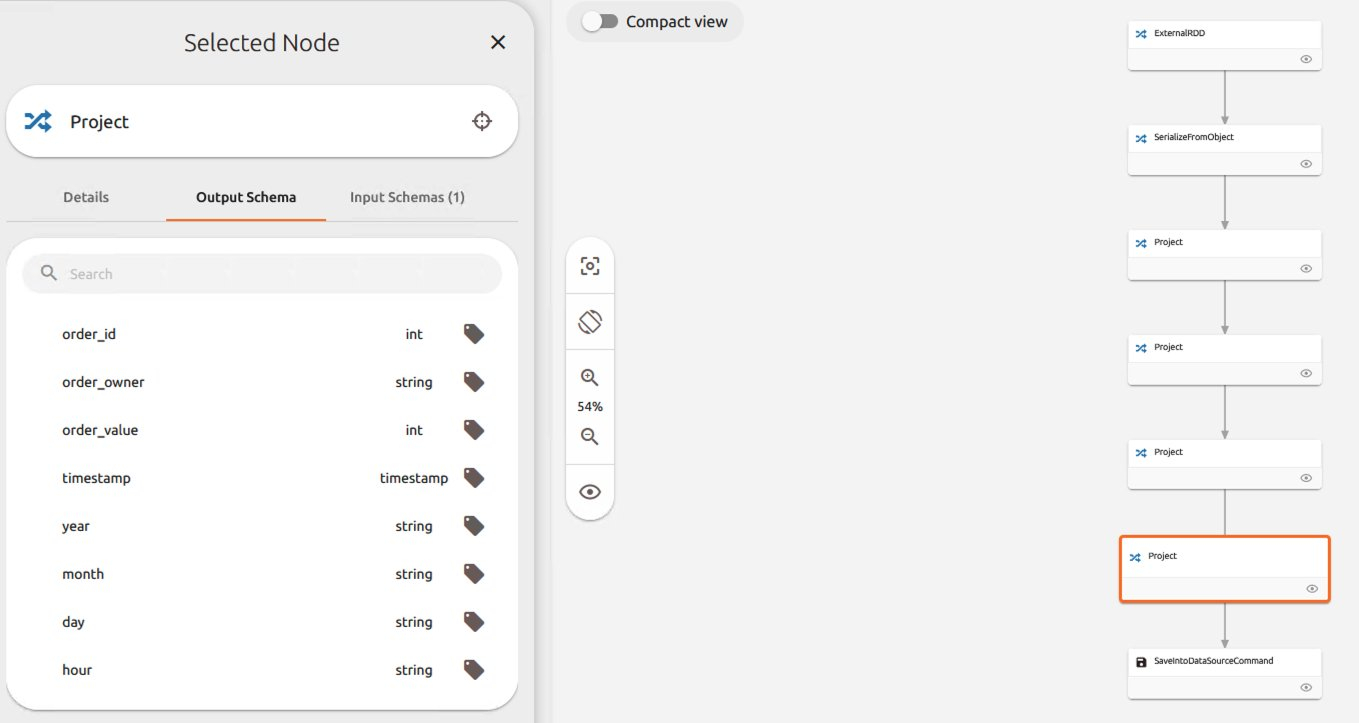
我们看到由于spline是by事件的记录血缘,因此可以看到每次触发写入都会产生一条血缘信息。我们看到捕获的Delta格式的记录。

执行Dag

表血缘

字段血缘和每步的schema


4.4 Spline收集Spark Structured Streaming+ Hudi on EMR的血缘
针对准实时的场景下,基于Hudi等的数据湖框架在企业中使用越来越普遍,本例尝试使用spline来统一数据湖中的流和批血缘

架构上,采用Kafka的connector作为RDS的CDC工具,同步数据湖中的多张表格,EMR.Spark 以 Structured Streaming 的方式消费 Kafka ,并将数据写入S3的Hudi-ODS表,并注册catalog。。
我们以pyspark的形式运行本例的结构流处理
启动pyspark,并带上spline的jar以及配置
SPARK_VERSION=3.1.2
SCALA_VERSION=2.12
HUDI_VERSION=0.10.0
alias nowts='date +"%s"'
pyspark \
--master yarn \
--deploy-mode client \
--name "`hostname`-`whoami`-`nowts`" \
--packages io.github.spark-redshift-community:spark-redshift_2.12:5.0.3,org.apache.spark:spark-sql-kafka-0-10_$SCALA_VERSION:$SPARK_VERSION,org.apache.hudi:hudi-spark3-bundle_$SCALA_VERSION:$HUDI_VERSION,org.apache.spark:spark-avro_$SCALA_VERSION:$SPARK_VERSION \
--jars s3://aws-virginia-spline-only-jar/za.co.absa.spline.agent.spark_spark-3.1-spline-agent-bundle_2.12-0.6.2.jar \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.sql.hive.convertMetastoreParquet=false' \
--conf 'spark.spline.producer.url=http://{Spline_server_IP}:48080/producer' \
--conf 'spark.spline.mode=REQUIRED' \
--conf 'spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener'
这里我们流式读取kafka多个topic,并自己推断schema且并行写入多张hudi表
from pyspark.sql.functions import explode;
from pyspark.sql.functions import split;
from pyspark.sql.functions import from_json;
spark.sql("SET spark.sql.streaming.metricsEnabled=true").show(10,False);
spark.sql("SET spark.sql.streaming.forceDeleteTempCheckpointLocation=true").show(10,False);
spark.conf.set("spark.sql.streaming.schemaInference",True)
import pyspark.sql.functions as fn;
from pyspark.sql.functions import col, struct, to_json
from pyspark.sql.types import StructType
from pyspark.sql.types import *
from concurrent.futures import ThreadPoolExecutor
import concurrent
KAFKA_BROKER="{KAFKA_ENDPOINT}"
# 定义流DF,读取多张表
kafkaDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", f"{KAFKA_BROKER}") \
.option("subscribePattern", "Aurora-8-unwarp-fix-v11-json.tesla.*") \
.option("startingOffsets", "earliest") \
.load()
import functools
def executor_run(table, batch_df):
tableName = table.split('.')[-1]
# basePath = "file:///tmp/hudi_trips_cow" # file
# basePath = "s3a://hudi/main/hudi_trips_cow_v1/" # lakeFS
# basePath = "s3a://aws-tools-kit/hudi_trips_cow_v1/" # minIO
basePath = f"s3a://app-util-hudi/spark/{tableName}" # S3
hudi_options = {
'hoodie.table.name': tableName,
'hoodie.datasource.write.table.name': tableName,
'hoodie.datasource.write.table.type': 'COPY_ON_WRITE',
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.recordkey.field': 'id',
'hoodie.datasource.write.partitionpath.field': 'age',
'hoodie.datasource.write.precombine.field': 'eventTS',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.bulkinsert.shuffle.parallelism': 2,
'hoodie.delete.shuffle.parallelism': 2,
'hoodie.datasource.hive_sync.mode': 'hms',
'hoodie.datasource.hive_sync.auto_create_database': True,
'hoodie.datasource.hive_sync.database': 'lake-hudi',
'hoodie.datasource.hive_sync.table': tableName,
'hoodie.datasource.hive_sync.partition_fields': 'age',
'hoodie.datasource.hive_sync.partition_extractor_class': "org.apache.hudi.hive.MultiPartKeysValueExtractor",
'hoodie.datasource.write.payload.class': 'org.apache.hudi.common.model.DefaultHoodieRecordPayload',
'hoodie.datasource.hive_sync.enable': "true",
}
one_batch_df = batch_df.filter(batch_df.topic == table).withColumn("json", col("value").cast(StringType()) \
).select("json")
json_schema = spark.read.json(one_batch_df.select("json").rdd.map(lambda row: row.json)).schema
#print(json_schema)
df = one_batch_df.withColumn("jsonData", from_json("json", json_schema))
one_batch_df.show(3)
df.select("jsonData.*").write.format("hudi"). \
options(**hudi_options). \
mode("append"). \
save(basePath)
def df_2_hudi_multiple_table(batch_df, batch_id):
"""
同结构df写入hudi
"""
tableList = batch_df.select('topic').distinct().rdd.flatMap(lambda x: x).collect()
print(tableList)
fs = dict()
executor_run_partial = functools.partial(executor_run, batch_df=batch_df)
with ThreadPoolExecutor() as executor:
# for table in tableList:
# task = executor.submit(executor_run, table)
# fs[task] = table
futures = {executor.submit(executor_run_partial, table) for table in tableList}
for fut in concurrent.futures.as_completed(futures):
print(f"The outcome is {fut.result()}")
kafkaDF.writeStream\
.option("checkpointLocation", "/home/hadoop/checkpoint-all-multiple-2022-04-01-001/")\
.trigger(processingTime='60 seconds')\
.foreachBatch(df_2_hudi_multiple_table)\
.start().awaitTermination()

由于spline是by事件的记录血缘,因此可以看到每次触发写入都会产生一条血缘信息

可以看到从源Kafka到最终write to s3的每一步,Spline以node来表示每一次对数据集的转换操作(Transformation)

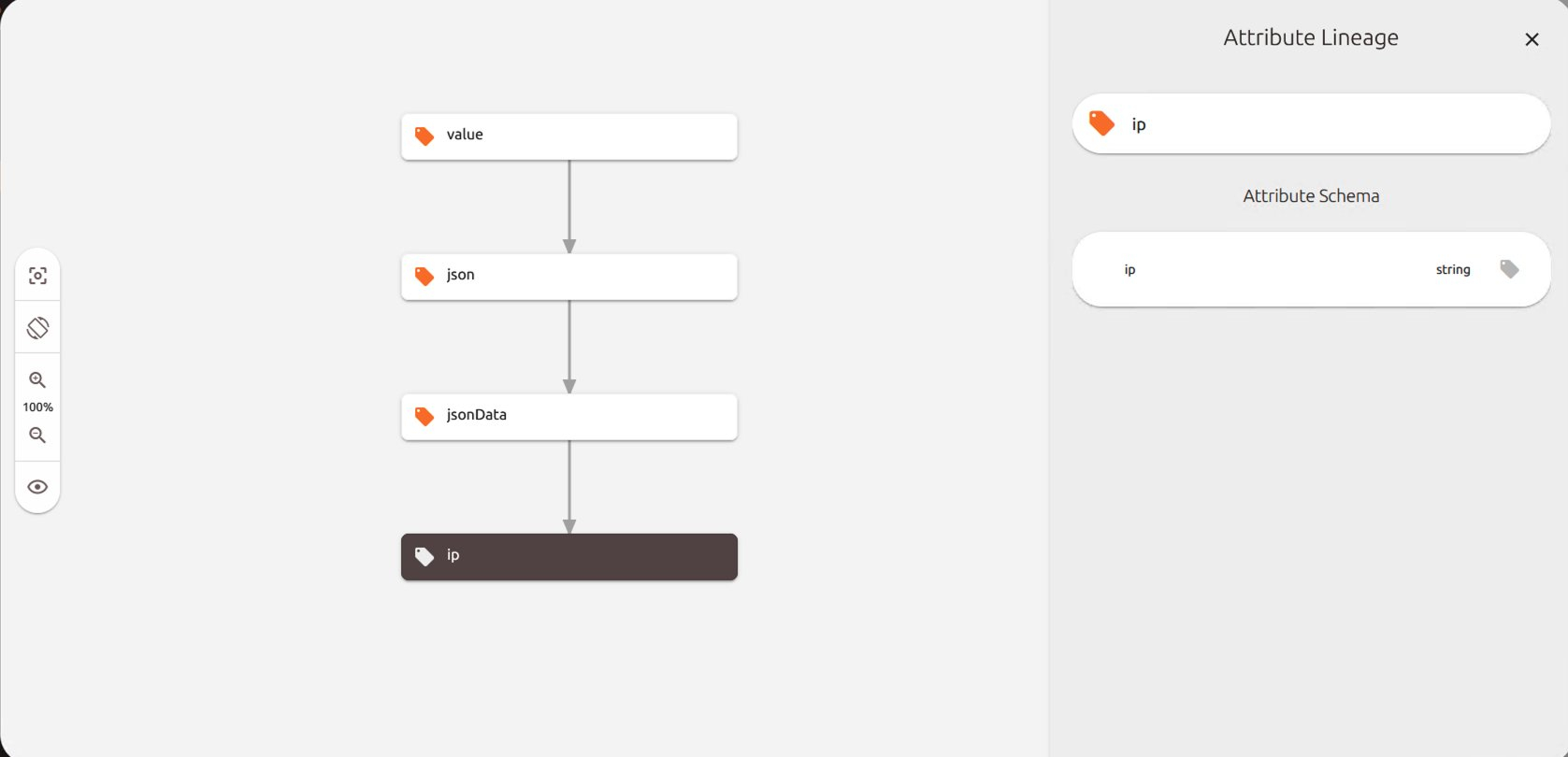
如果选择一个Node, 可以看到从上游到下游转换操作每一步的对字段血缘影响的可视化

点击一个Node, 可以看到其具体的转化操作

5. Spline血缘总结
1. Spline可以完全捕获以Glue, EMR来运行的Job, 并且支持Spark 3.0。
2. Spline可以在不侵入代码的情况下,增加spark作业血缘,极大的降低了老脚本添加血缘的成本。
3. Spline可以支持DataFrame API和SparkSQL的数据血缘,注意:非DataFrame操作的血缘不可捕获。
4. Spline支持Spark Structured Streaming,统一流批血缘。注意:目前只可以捕获在Structured Streaming以foreachBatch + DataFrame.write的方式写入的血缘,对原生的writeStream 的支持目前正在开发中。
5. SpineSpline支持所有JDBC方式的数据血缘捕获,也支持字段级别血缘与字段衍生的可视化,且对数据湖框架支持良好。
6. Spline提供了Producer & Consumer API,方便第三方集成和二次开发。
参考资料
https://absaoss.github.io/spline/
https://github.com/AbsaOSS/spline-getting-started/tree/main/spline-on-AWS-demo-setup
https://github.com/AbsaOSS/spline-spark-agent/tree/develop/examples
https://docs.delta.io/latest/quick-start.html
https://hudi.apache.org/docs/0.10.0/writing_data/
https://en.wikipedia.org/wiki/Data_lineage
https://thinkwithwp.com/blogs/big-data/making-etl-easier-with-aws-glue-studio/
本篇作者