亚马逊AWS官方博客
使用Amazon Web Services CDK,在云上构建DataOPS 平台
前言
这是系列文章的第二篇,在第一篇文章“另辟蹊径: 在云端使用SQL语言实现数据转化,测试和文档维护” 中介绍了做数据准备的ELT模式,以及如何利用DBT来帮助Data Analysts通过SQL做数据转化,测试和文档维护。 在这篇文章中,将以上一篇为基础,使用Amazon Web Services CDK构建一个Data OPS方案。
引子
在全球化经济放缓的背景下,传统企业面临着比以往更加激烈的市场竞争,企业进行数字化转型,也就变得越来越重要。
作为一名解决方案架构师,按我的理解,从技术角度去看,数字化转型的本质就是利用大数据的技术来提升企业的运营效率,从而使企业的各个部门,如客户成功、营销和财务部门,都能做出数据驱动的决策。在这个过程中,数据团队是关键推动者。 数据团队通常由Data Infra Engineer和Data Analysts等多个角色组成。
Data Infra Engineer和Data Analysts分工不同:
Data Infra Engineer团队负责创建和维护基础设施,比如数据仓库,数据湖的基础设施的维护,CICD Pipeline等;
Data Analysts拥有业务领域知识,负责为不同的Stakeholder(如营销和业务开发团队)的分析请求提供服务,从而使公司能够做出数据驱动的决策。
然而,IDC在2020年初的一份报告 中分析,传统的方式,Data Infra Engineer和Data Analysts在不同的孤岛上行动,成为了企业数字化转型的最大障碍。在这篇文章中,将向读者介绍如何通过CDK,使用Git, CodeBuild, Fargate, Airflow 等服务来构建一个DataOPS平台,从而打破Data Infra Engineer和Data Analysts之间的障碍,提高数据分析的效率。
DataOPS 平台参考架构
架构概述
本文提出了一个实现DataOPS平台的参考架构,有如下特点:
- Data Analysts可以利用他们的业务领域知识,使用他们擅长的语言(SQL)编写对应的代码,而不需要关系底层的Infra的问题;
- Data Analysts编写完代码之后,提交到Git仓库,可以自动触发CI的流程,变成可运行,可部署的状态,而不需要关系CI的流程,不需要关系底层的Infra;
- Data Analysts可以使用自身熟悉的软件(Airflow), 编写调度的DAG,在进行调度的时候,Airflow会自动的基于Serverless的Fargate执行任务,Infra会根据要执行的任务数量自动扩展,不需要Data Analysts干预;
- Data Infra Engineer可以使用Infra As Code的方式创建维护所有的Infra资源,包括CICD流程,ECR 仓库,Redshift集群,ECS 集群等, 而无需手工通过控制台进行操作。
架构图及流程说明
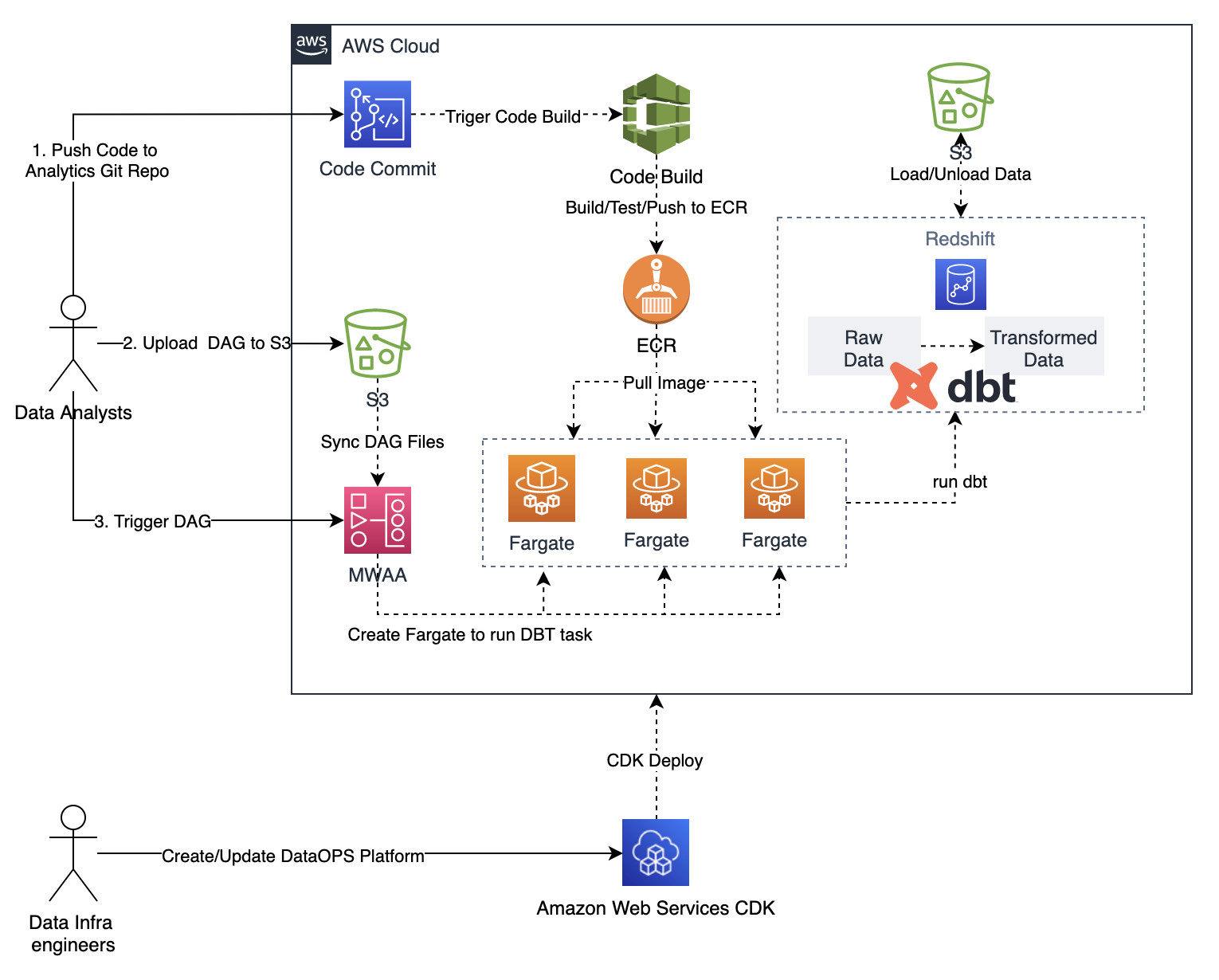
Data Infra Engineer
通过CDK 创建DataOPS 平台, 主要组件包括:
- Redshift 集群
- CodeCommit, CodeBuild,用于构建 Data Analysts 开发的DBT工程的持续集成流程
- ECR,用于存放管理Data Analysts 开发的DBT工程的Docker Image
- MWAA,用于供数据开发人员调度DBT任务的Airflow集群
- ECS Cluster, 用于运行DBT Task
Data Analysts
在Data Infra Engineer使用CDK创建好DataOPS平台之后,Data Analysts大致操作流程如下:
- Data Analysts使用SQL基于DBT框架编写代码,推送到GitCommit;
GitCommit 会自动触发CodeBuild,下载代码,进行编译,生成container 镜像,并推送到ECR仓库;
- Data Analysts,编写Airflow的DAG,并上传到S3;
- Data Analysts,在Airflow中管理触发DAG;
Airflow 会自动在ECS Cluster中创建Task,运行DBT任务。
使用Amazon Web Services CDK构建 Data OPS 方案
笔者也实现了上述架构,源代码在Github公开,供读者参考,其中:
- elt-dbt-redshift-demo-for-data-engineer 为Data Infra Engineer提供了参考实现;
- elt-dbt-redshift-demo-for-data-analysts 为Data Analysts提供了参考实现;
接下来详细演示如何在云上构建并使用DataOPS平台:
CDK 开发环境搭建
开发Amazon Web Services CDK需要先安装Amazon Web Services CDK CLI,利用 Amazon Web Services CDK CLI可以生成对应的CDK 的Project。
Amazon Web Services CDK CLI的安装依赖于Node.js, 所以在您的开发环境需要先安装node.js。node.js 的安装可参看官方教程: https://nodejs.org/en/download/package-manager/。
安装好 node.js 之后,可以直接使用 如下命令安装 Amazon Web Services CDK CLI:
npm install -g aws-cdk #安装cdk cli
cdk --version #查看版本
安装 CDK CLI后,需要通过Amazon Web Services configure 命令配置开发环境的用户权限,详情参考: https://docs.thinkwithwp.com/cli/latest/userguide/cli-configure-files.html
Data Infra Engineer 使用CDK 构建Data OPS 平台:
npm install -g yarn
npm install -g npx
git clone https://github.com/readybuilderone/elt-dbt-redshift-demo-for-data-engineer.git
cd elt-dbt-redshift-demo-for-data-engineer
npx projen
npx cdk bootstrap aws://<ACCOUNT-NUMBER>/<REGION> --profile <YOUR-PROFILE>
npx cdk deploy --profile <YOUR-PROFILE>
注意: 读者需要替换, , 为自己环境的值。
整个过程大约需要40分钟左右,运行完成之后,命令行会返回:
- 存放Airflow Dag的S3 Bucket的名称
- ECS Cluster的名称
- ECS Task Definition名称
- Redshift的所在的Subnet的ID
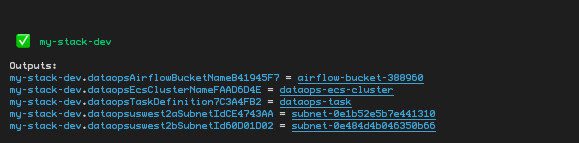
至此,Data Infra Engineer 已经使用CDK搭建完成Data OPS平台,读者可以登入到控制台进行相应验证。
Code Commit:
CDK 创建了一个空的CodeCommit,供Data Analysts使用;

Code Build
CDK创建了CodeBuild Project,会在Data Analysts提交代码到CodeCommit后,自动触发,打包成container image

ECR Repo
CDK创建了空的ECR Repo,用来存放CodeBuild生成的container image:

ECS Cluster
CDK 创建了ECS Cluster,和对应的Task用来运行dbt的container 任务:


MWAA
CDK 创建了MWAA,其中DAG为空:
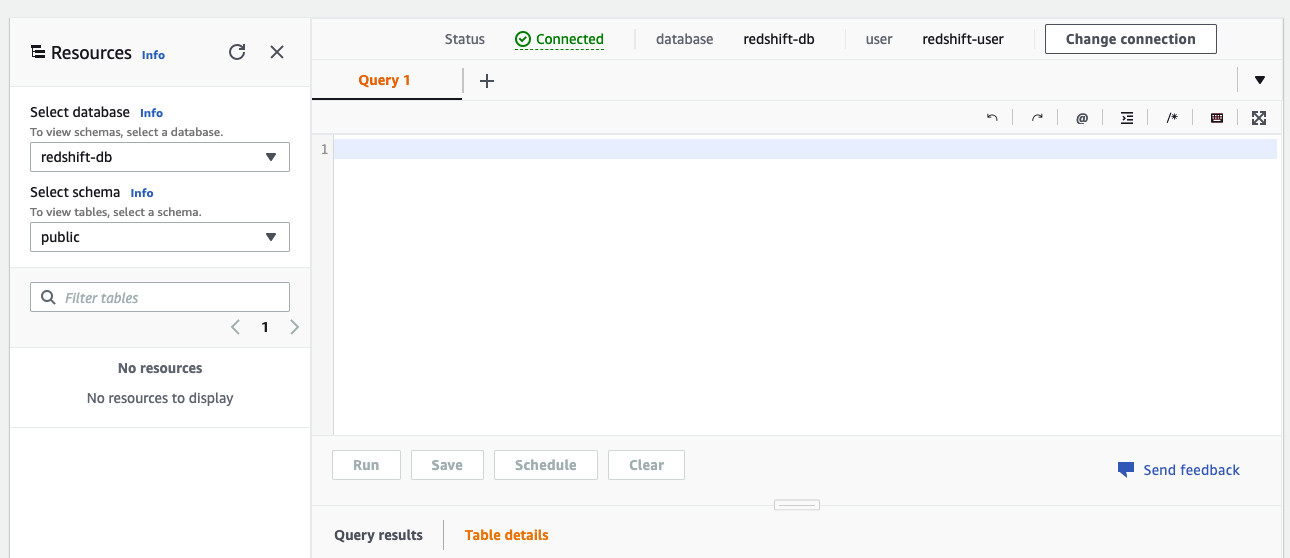
Redshift
CDK 创建了Redshift集群,但是public schema之下,并没有任何的table:
DataOPS 平台创建成功,接下来演示 Data Analysts的部分。
Data Analysts 利用Data OPS平台进行项目开发
推送代码到CodeCommit
Data Analysts 推送代码到CodeCommit之后,应该自动触发CodeBuild生成container image,推送到ECR。
Data Analysts使用的Sample代码托管在 Github,在配置好CodeCommit权限(如何配置可参考 官方文档)之后,可以采用如下命令推送到CodeCommit:
git clone https://github.com/readybuilderone/elt-dbt-redshift-demo-for-data-analysts.git
cd elt-dbt-redshift-demo-for-data-analysts
git remote -v
git remote add codecommit <YOUR-CODECOMMIT-SSH-ADDRESS>
git push codecommit

仔细观察下 elt-dbt-redshift-demo-for-data-analysts代码,可以发现Image内的是一个标准的DBT Project。
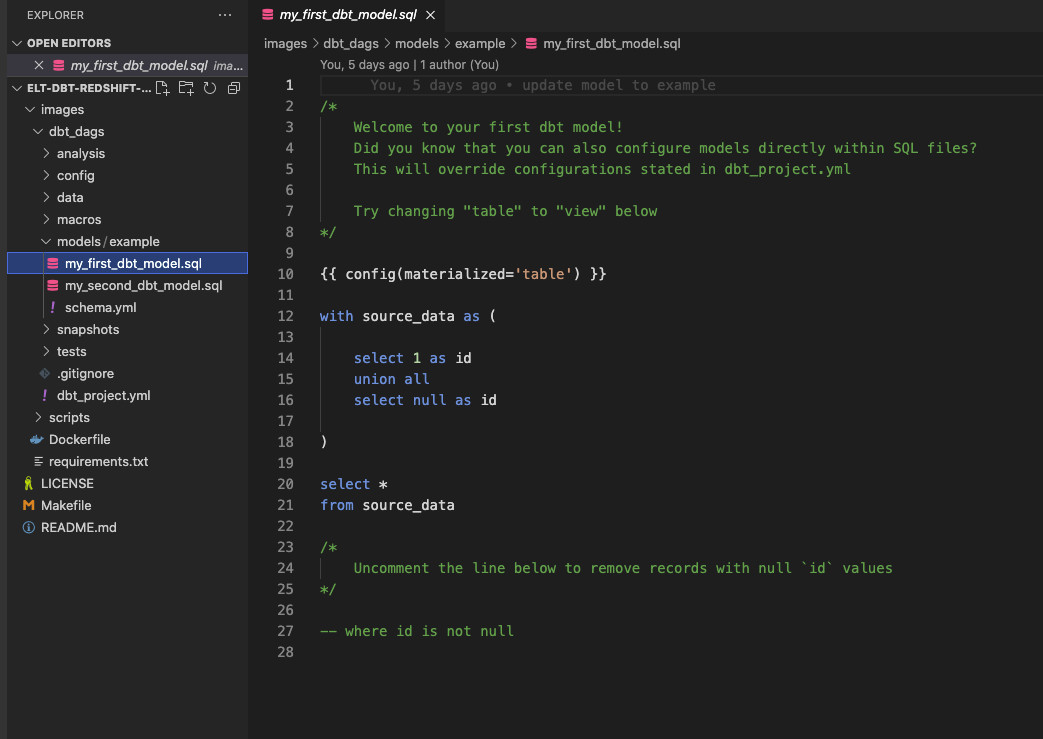
Data Analysts 不需要改变任何习惯,只需要开发对应的model,并推送到Git,就可以出发持续集成的流程。
想要了解DBT Project的读者可以参考上一篇文章: 另辟蹊径: 在云端使用SQL语言实现数据转化,测试和文档维护, 本篇文章目的在于演示DataOPS平台,就使用DBT的sample model,在空的Redshift中创建测试Table。
观察DataOPS过程
在push 之后,进入CodeCommit查看代码更新, 可以看到代码已经成功推送到CodeCommit:

进入CodeBuild查看,会发现已经自动构建container image,并推送到了ECR:
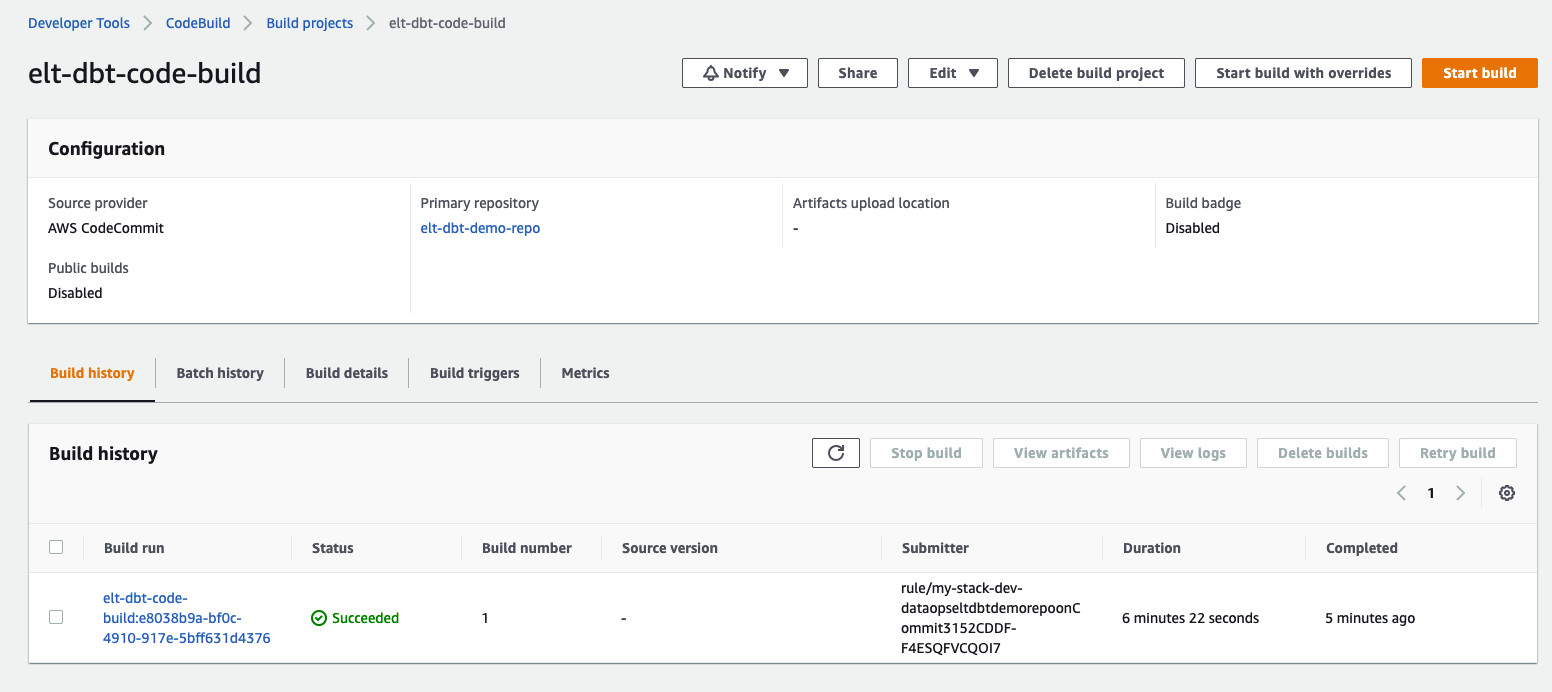
进入到ECR中查看,会发现刚刚构建的container image:
Data Analysts 构建Airflow DAG,触发DBT任务,使用Fargate运行DBT 任务
在完成上述步骤之后,Data Analysts可以使用自己熟悉的Airflow来调度DBT。
示例Airflow 的DAG如下:
注意: 读者需要替换 为自己环境的值(Data Infra Engineer 使用CDK 创建DataOPS平台时的返回值)
替换好之后,将elt-dbt.py 上传到Airflow的Bucket中(Bucket Name见 Data Infra Engineer 使用CDK 创建DataOPS平台时的返回值)。
aws s3 cp ./elt-dbt.py S3://<YOUR-BUCKET>/dags/ --profile <YOUR-PROFILE>

进入Airflow,稍等片刻,可以看到对应的DAG。

在Airflow中触发DAG

可以看到DAG已经被执行:
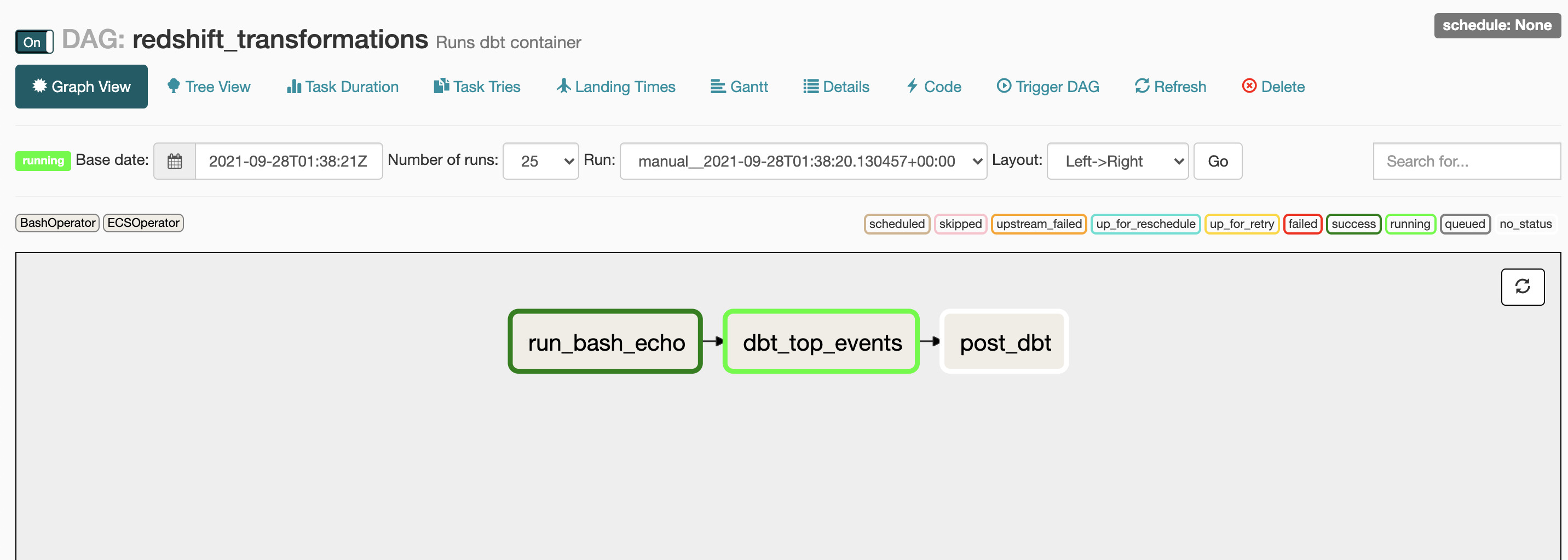
在运行 dbt_top_events 的阶段,进入ECS,可以看到dataops-task在运行:

在DAG执行完成之后,进入RedShift查看验证结果:
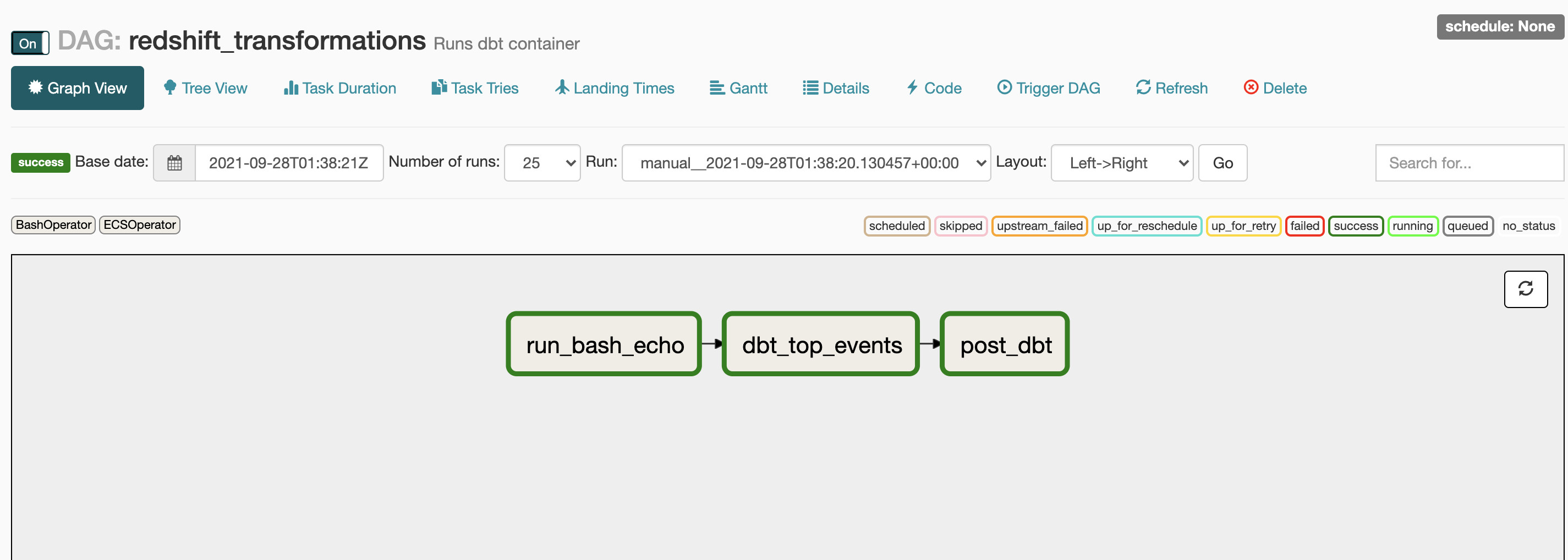
可以看到,my_fist_dbt_model 和 my_second_dbt_model 已经生成,DBT任务执行成功。

总结
在本篇文章中,提供了DataOPS的一个参考实现,Data Infra Engineer可以使用CDK 方便的创建维护Infra, Data Analysts基于这个平台,可以使用自己熟悉的语言和调度工具,进行开发。提交到Git之后,可以自动触发持续集成的后续任务,可以通过Airflow使用Fargate运行对应的任务,而不需要关心Infra层面的问题,希望这个方案可以帮助到读者。
补充说明:在MWAA还未提供的区域,比如cn-north-1 和 cn-northwest-1, 推荐读者可以尝试下这个基于Fargate的Airflow方案,已经封装成了CDK Library,只需要数行代码,就可以创建一个符合优良架构的Airflow集群。
参考文档
DBT Offical Doc
Amazon Web Services Blog: Build a DataOps platform to break silos between engineers and analysts
Amazon Web Services Workshop: CICD-Pipeline-With-CDK