亚马逊AWS官方博客
使用 Amazon FSx for Lustre 和 Amazon EFS 作数据源加快 Amazon Sagemaker 训练
Amazon SageMaker (以下简称SageMaker)是一项完全托管的机器学习服务,涵盖了数据标记,数据处理,模型训练,超参调优,模型部署, 持续模型监控等基本流程,也提供自动打标签,自动机器学习,监控模型训练等高阶功能。在 SageMaker 中训练模型一般使用Amazon Simple Storage Service (以下简称S3) 作为存储配合使用。事实上SageMaker做模型训练时已经支持多种数据源,比如 Amazon FSx for Lustre 和 Amazon Elastic File System (EFS) 。SageMaker通过直接读取存储在EFS或者FSx for Luster上的数据来加快训练模型时数据加载进度。
Amazon FSx for Luster是托管的高性能文件系统,针对诸如机器学习,分析和高性能计算等工作负载进行了优化,并且原生支持与S3集成,从而可以使用Lustre轻松处理S3中数据集。Amazon EFS为基于Linux的工作负载提供了一个简单,可扩展的弹性文件系统,旨在为数千个 Amazon EC2 实例提供大规模并行共享访问模式,也支持与AWS 服务和本地资源一起配合使用。
一般情况下,使用SageMaker做机器学习模型训练时需要提供S3存储桶的路径,用于存储训练数据以及输出模型。如果已经有历史数据位于文件系统比如EFS或者FSx for Luster,可以在SageMaker创建训练任务的时候直接定义EFS 或者FSx for Luster做数据源,同样的如果在数据预处理阶段需要在Sagemaker Jupyter Notebook上跟这部分数据交互,也可以直接将EFS挂载到Sagemaker Jupyter instance,然后以本地文件的方式访问。另一方面,在文件输入模式(File Mode)下将S3用作训练数据源时,必须在训练作业开始时将所有训练数据从S3下载到附加到训练实例的EBS卷中。分布式文件系统(例如适用于Luster的Amazon FSx或EFS)可以消除此下载步骤,从而加快了机器学习训练的整体速度。
本文将介绍使用Amazon EFS 或者 Amazon FSx for Luster 与 SaeMaker 配合使用的详细方法:
- S3 & EFS & Fsx 之间如何选择
- 将EFS文件系统挂载到Amazon SageMaker笔记本实例
- 将EFS 作为在 SageMaker 上训练机器学习模型的数据源
- 将Fsx 作为在 SageMaker 上训练机器学习模型的数据源
选择文件系统以在Amazon SageMaker上训练模型
SageMaker做模型训练时支持多种数据源,如下图所示。在考虑训练机器学习模型时数据应该放在哪种文件系统时,首先要考虑的是:训练数据现在位于何处?
如果您的训练数据已经在S3中并且不需要更快的训练时间,那么直接利用S3做SageMaker数据源而无需进行数据移动。但是如果您需要更快的启动和更短的训练时间,建议利用FSx for Luster文件系统,该文件系统原生支持与S3集成。FSx for Lustre 通过将S3数据高速提供给SageMaker来加快训练速度。第一次运行训练任务时,FSx for Luster会自动从S3复制数据,并将其提供给SageMaker。此外,同一FSx文件系统可用在SageMaker后续多次迭代训练任务,从而避免每次训练任务都从S3重复下载需要的对象。因此在针对同一组数据集需要执行多次训练任务的场景,FSx才具有明显优势。
如果您的训练数据已经在EFS文件系统中,则建议选择EFS作为数据源,无需数据移动即可直接启动训练任务,从而缩短了训练开始时间。通常数据科学家在EFS环境中可以方便的加入新数据以及尝试不同数据字段或标签组合,与同事共享数据,实现来快速迭代模型目的。例如,数据科学家可以使用Sagemaker Jupyter Notebook对训练集进行初始数据清洗,从SageMaker启动训练任务,然后使用他们的Notebook删除训练集中一列实现修改特征工程,再次重新启动训练任务,最后比较不同训练任务的结果模型对比实验效果。
场景1 – 将EFS文件系统挂载到Amazon SageMaker笔记本实例
在Sagemaker中以VPC模式启动的笔记本实例支持挂载EFS文件系统来扩展笔记本实例存储空间,直接使用已经挂载在现有EC2实例的EFS时可以实现快速访问在EFS上的历史数据。将EFS文件系统挂载到笔记本实例也可以实现在不同的笔记本实例之间共享数据或者代码,适用的场景比如快速从自建在EC2的jupyter notebook迁移到Sagemaker notebook,或者从Sagemaker notebook上访问位于EFS上的大型数据集。
启动SageMaker笔记本实例时默认配置为 5 GB 的EBS存储,需要处理较大数据集和文件可以选择存放在S3,针对延时敏感以及对灵活性要求高的场景也可以选择将EFS挂载到笔记本实例,文件系统相比S3可以提供更高的灵活性和更低的延时。下面我们将给大家演示如何将EFS文件系统挂载到Amazon SageMaker笔记本实例。
第一步:在SageMaker界面创建并启动笔记本实例,并添加到客户自定义VPC
- 基本设置:自定义笔记本实例名称,选择合适实例类型。
- 权限设置:使用默认的附加了
AmazonSageMakerFullAccess策略的权限。 - 笔记本实例默认在Amazon SageMaker管理的VPC中运行,创建时需要在 网络 部分手动选择 VPC 和 子网 来将该笔记本实例添加到自己的VPC中。建议选择 启用Internet 访问,关于Sagemaker 笔记本实例网络配置的更多信息可以参考 博客。

第二步:在EFS 控制页面获取IP和挂载点信息
- 在控制台打开EFS,进入指定文件系统的详细信息页面
- 在 网络 处找到该文件系统对应的ip地址

-
- 在网络处找到该文件系统的安全组,确认安全组是否允许NFS的流量,否则可能导致挂载失败

- 上面的网络配置信息也可通过AWS CLI获取,将target-id改为你自己EFS文件系统对应的值:
aws efs describe-mount-targets --mount-target-id fsmt-e4xxxx479
第三步:打开Sagemaker笔记本实例命令行窗口,通过mount 命令挂载efs文件系统:
- 先用命令行创建一个供挂载的文件夹
mkdir efs_data
- 执行以下命令将efs挂载到Sagemaker notebook
- 执行以下命令确认挂载成功:
df -h

第四步:通过生命周期配置做文件系统挂载的开机自启动
为了防止笔记本实例stop再start之后挂载失效,可以在笔记本实例生命周期配置中通过脚本实现开机自动挂载的效果。创建生命周期配置时脚本分为两部分,“启动笔记本”处添加的脚本会在笔记本实例每一次启动时自动执行,本次添加的命令就是mount操作。“创建笔记本”处添加的脚本是在创建新的实例时才会执行,所以命令为创建一个挂载点。创建新的笔记本实例时可以直接使用这个生命周期配置,可以省去上面的手动挂载流程。
- 在控制台创建生命周期配置,在 启动笔记本 配置处添加上一步b)脚本;

- 为了让这个生命周期配置在新创建笔记本时可以直接使用,在 创建笔记本 配置处添加上一步a)的脚本:

- 修改旧笔记本实例的生命周期配置
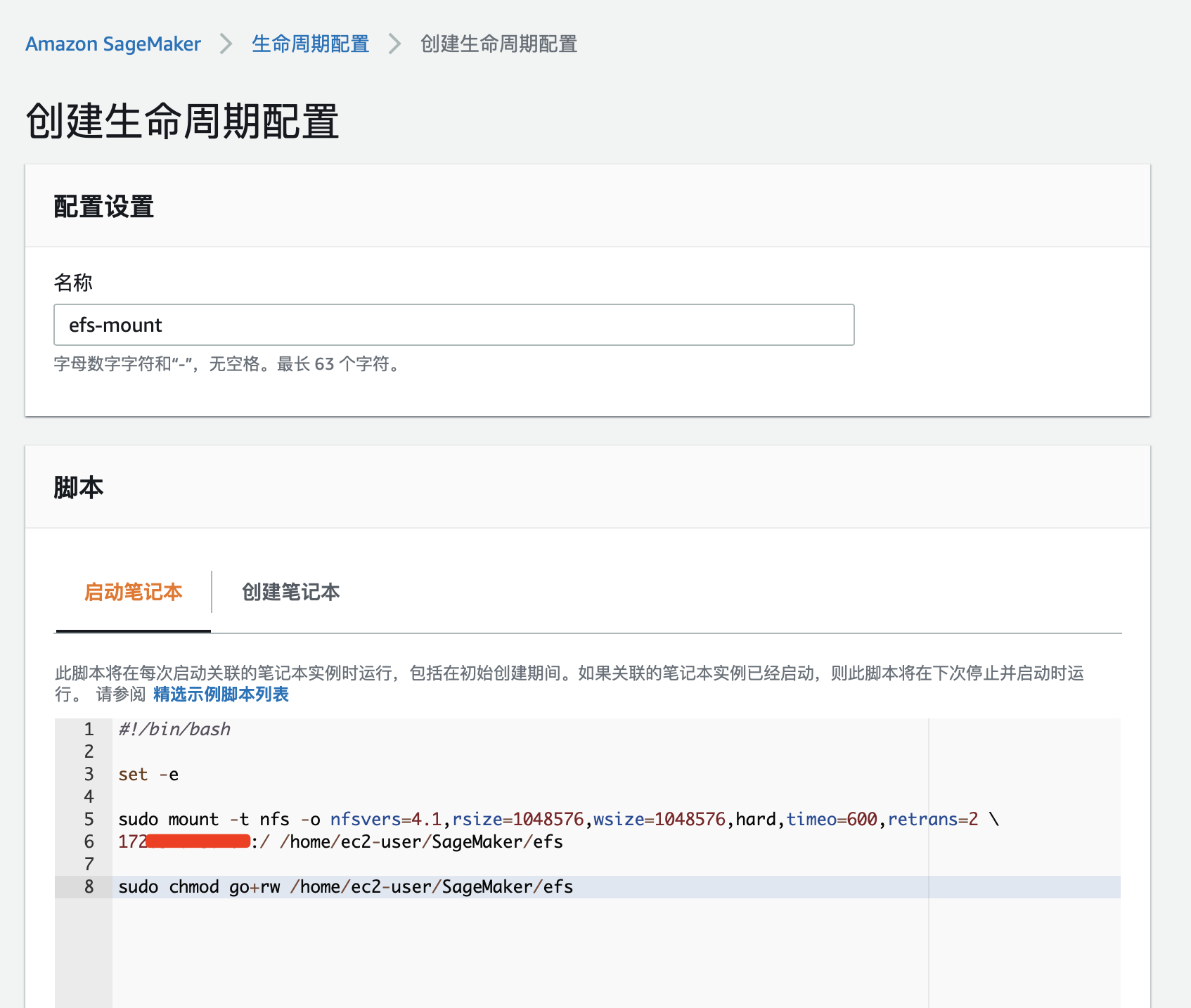

在笔记本实例命令行窗口中用mkdir 创建一个文件夹作为挂载点,然后在控制台操作 里面停止Sagemaker笔记本实例,等笔记本实例变成stop状态之后再修改 笔记本实例设置 里面的 生命周期配置 ,下拉选择上一步创建的生命周期配置的名称;

修改完毕之后在控制台点击笔记本实例 开始 ,笔记本实例启动时会自动执行 mount 完成挂载动作。在笔记本实例命令行窗口中用 df -h 命令查看挂载是否成功。
- 创建新笔记本实例时设置生命周期配置
在创建笔记本实例时,在笔记本实例设置 下面的 生命周期配置 选择已经创建的生命周期配置的名称。
笔记本实例启动时会先执行mkdir创建一个文件夹作为挂载点,再自动执行 mount 完成挂载动作。在笔记本实例命令行窗口中用 df -h 命令查看挂载是否成功。
场景2-将EFS 作为在 SageMaker 上训练机器学习模型的数据源
环境准备
假设训练数据集已经在EFS中,第一步确认数据所在的目录以及EFS所在的VPC和子网,后续会用到这些信息。第二步检查EFS安全组入站规则是否打开端口2049的NFS流量。
通过控制台定义训练任务
第一步:创建训练任务:控制台转到Amazon SageMaker界面,在左侧边栏打开“训练任务”页面,并点击“创建训练任务”。

第二步:定义训练任务:训练任务基本设置如作业名称,算法,实例资源根据实际场景自定义,其中几个需要注意的设置作如下说明,
- IAM 角色 : 在Sagemaker 默认创建role的权限基础上增加
ec2:describe vpcendpoint的权限。可以在之前通过Sagemaker创建的Role上编辑权限,也可以直接提前创建新的Role,这里直接选择就可以。具体步骤如下:
在IAM 界面 角色中 搜索默认的Sagemaker Role类似 AmazonSageMaker-ExecutionRole-20200xxxxx2799;

附加 EC2 : DescribeVpcEndpoints权限,如果对IAM不太熟悉可以直接附加 AmazonEC2FullAccess策略;

- 网络设置:提供关联的VPC子网,安全组需要指定EFS所在的VPC或者EFS可以访问到的VPC,已经允许安全组是否允许通过端口2049的NFS流量控制对文件系统中存储的训练数据集的访问

- 输入数据配置:选择文件系统作为数据源,设置类型为“EFS”并正确引用文件系统ID,路径和格式
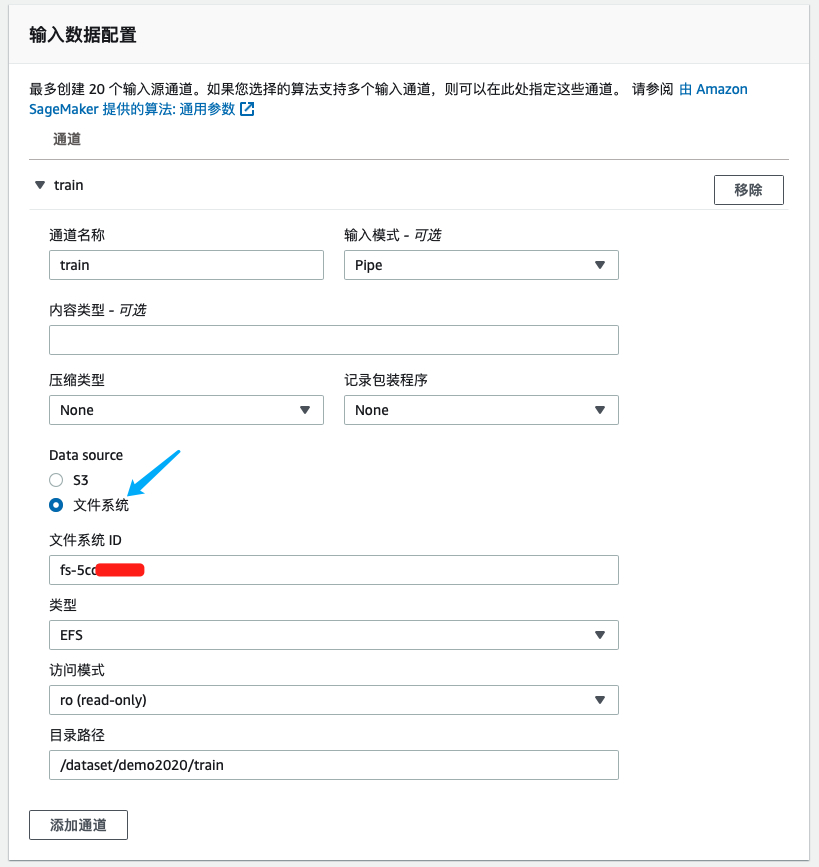
- 输出数据配置:输入s3路径作为checkpoint以及模型的保存路径
第三步:其余配置项保持默认,确认上诉配置无误之后点击“创建训练任务”,即启动本地训练任务。在控制台“训练任务”页面可以查看训练作业的状态,记录训练时间以观察使用文件系统数据源时的更快下载时间。
PS:目前中国区控制台还没有提供该选项,可以用下面方法通过笔记本实例创建训练任务。
通过笔记本实例创建训练任务
本次实验以图像分类算法为示例,完整的代码见Github。
第一步:定义输入数据,主要提供文件系统信息和路径。
第二步:定义训练任务,指定训练算法以及训练实例类型和使用的role等基本环境配置。
第三步:指定输入数据以及启动训练任务。
场景3 – 将Fsx 作为在 SageMaker 上训练机器学习模型的数据源
环境准备
假设目前数据位于S3存储桶中,需要创建FSx for Lustre 文件系统链接到存储桶,它会在第一次访问对象时自动将对象从S3复制到文件系统。同一个 FSx 文件系统还可用于多项 SageMaker 训练任务,省去多次重复下载训练数据集的时间。
如果您的数据已经位于在FSx for Lustre 文件系统,可以直接跳过第一步。
- 创建基于S3的Fsx:
- 在“网络和安全性”处设置VPC,子网组和安全组,并确认安全组入站规则是否允许了端口998的流量
- 在“数据存储库”处选择“ 从 S3导入数据”并指定S3训练数据所在的存储桶 和 路径

- 创建完成之后记录Fsx的ID 等基本信息,后续配置会用到
通过控制台定义训练任务
- 创建训练任务:控制台转到Amazon SageMaker界面,在左侧边栏打开“训练任务”页面,并点击“创建训练任务”。
- 定义训练任务:训练任务基本设置如作业名称,算法,实例资源根据实际场景自定义,其中几个需要注意的设置作如下说明,
- IAM 角色 : 在Sagemaker 默认创建role的权限基础上增加ec2:describe vpcendpoint的权限。具体步骤参照上一个章节的说明。
- 网络设置:提供训练任务和FSX可以访问到的VPC以及子网,此外,请确认安全组入站规则允许端口988的Lustre流量通过,即允许对文件系统中存储的训练数据集的访问。有关更多详细信息,请参阅Amazon FSx入门
- 输入数据配置:选择文件系统作为数据源,选择类型为“FSxLutre”并正确引用文件系统ID,路径和格式。

- 输出数据配置:输入s3路径作为checkpoint以及模型的保存路径
- 确认上诉配置无误之后点击“创建训练任务”,即启动本地训练任务

在控制台“训练任务”页面可以查看训练作业的状态,记录训练时间以观察使用文件系统数据源时的更快下载时间。
通过笔记本实例创建训练任务
笔记本实例中的代码与上一个章节中使用EFS时基本一致,主要注意修改file_system_type 为 ' FSxLutre ',完整的代码见Github。
PS:目前中国区还不支持用FSxLutre做为训练数据源
测试对比
为了更加直观的对比效果,在场景2下我们对比了用EFS和S3做数据源时下载数据所花时间的差异。训练数据集是开源的斯坦福大学提供的开源数据集”Cars”,包含 16,185 张 196 种汽车的图像,测试时随机选取了了80%的图片作为训练集。测试使用SageMaker 内置图像分类算法对比了文件模式下 RecordIO格式和图像内格式所花时间。使用RecordIO格式训练时我们使用im2rec脚本制作的训练集train.rec和validation.rec大约175M。图像格式下训练数据集约950M。多次实验之后取平均值对比图如下,看出s3做数据源时在data downloading 花的时间比EFS做数据源时多,另外因为RecordIO格式是多进程从S3读取数据所以花时间比较少,并且此次数据集规模比较小,对比EFS做训练数据源的训练任务来看数据下载节约时间不算明显,但在大数据集规模和超参调优多次训练时可以累积节省大量时间,并且数据已经在EFS时可以不用将数据转移到S3,也会节约一些上传的时间和步骤。

总结
Amazon SageMaker加入适用于Lustre的Amazon FSx和Amazon EFS作为训练机器学习模型的数据源,为您现在有了更大的灵活性来选择适合您使用场景的数据源。在此博客中,我们使用了文件系统数据源来训练机器学习模型,从而消除了数据下载步骤,缩短了训练开始时间。
参考
- Sagemaker文档:https://docs.thinkwithwp.com/zh_cn/sagemaker/latest/dg/whatis.html
- Sagemaker API 文档: https://docs.thinkwithwp.com/zh_cn/sagemaker/latest/APIReference/API_CreateTrainingJob.html
- EFS:https://docs.thinkwithwp.com/zh_cn/efs/latest/ug/whatisefs.html
- FSx:https://docs.thinkwithwp.com/zh_cn/fsx/latest/LustreGuide/what-is.html
- 使用文件系统做数据源训练线性学习器模型:https://github.com/awslabs/amazon-sagemaker-examples/blob/master/introduction_to_amazon_algorithms/linear_learner_mnist/linear_learner_mnist_with_file_system_data_source.ipynb
- sagemaker网络模式配置:https://thinkwithwp.com/cn/blogs/machine-learning/understanding-amazon-sagemaker-notebook-instance-networking-configurations-and-advanced-routing-options/