亚马逊AWS官方博客
在 Amazon EMR 上使用 Dr. Elephant 与 Sparklens 实现 Hadoop 与 Spark 性能调优
数据工程师与ETL开发人员通常会花费大量时间运行Apache Spark作业,并配合不同参数进行调优以评估作业的性能表现。这是一项困难且相当耗费心力的工作。Dr. Elephant与Sparklens能够监控工作负载并针对多项性能优化参数提供调整建议(包括执行节点、核心节点、Mapper/Reducer上的Driver Memory与Hive/Tez/MapReduce作业帮助大家优化Spark与Hive应用程序、数据倾斜配置等等)。Dr. Elephant能够收集各项作业指标、据此运行分析,并以简单方式提供优化建议,帮助用户轻松执行并采取纠正措施。同样的,Sparklens还能帮助用户快速了解Spark应用程序与计算资源的扩展能力限制,并提供明确定义的高效运行方式,帮助开发人员避免大量重复尝试、节约宝贵的计算资源与时间。
本文将向大家展示如何在Amazon EMR集群上安装Dr. Elephant与Sparklens,并运行相应工作负载以证明这些工具的功能。Amazon EMR是一项由AWS提供的托管Hadoop服务,以更轻松且更具成本效益的方式在AWS上运行Hadoop及其他多种开源框架。
下图所示,为本文解决方案的基本架构。数据工程师与ETL开发人员可以将作业提交至Amazon EMR集群,并根据Dr. Elephant与Sparklens工具的调优建议优化Spark应用程序与计算资源,借此获得更理想的性能表现与资源使用效率。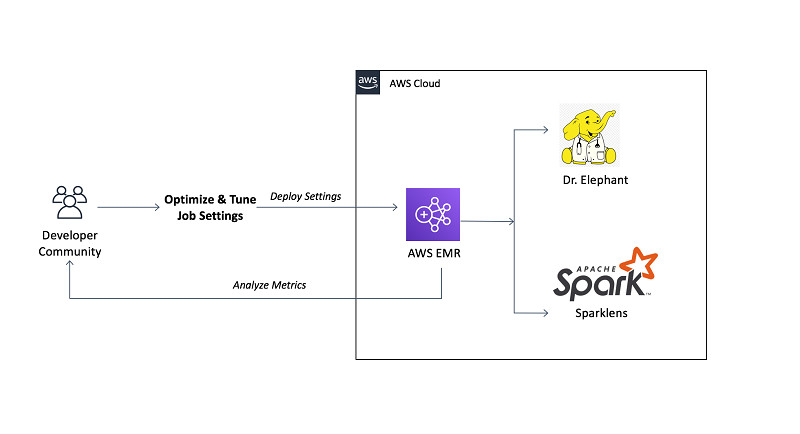
前提步骤
创建一个新的EMR集群
要使用Dr. Elephant或Sparklens配置EMR集群,我们首先需要启动一个具备必要容量的EMR集群。本文使用默认设置的10个r4.xlarge核心节点与1个r4.rxlarge主节点。
大家可以通过AWS管理控制台、AWS CloudFormation模板或者AWS CLI命令启动EMR集群。具体请使用以下CloudFormation Stack:
以下截屏所示,为利用CloudFormation stack启动的EMR集群的Summary摘要信息。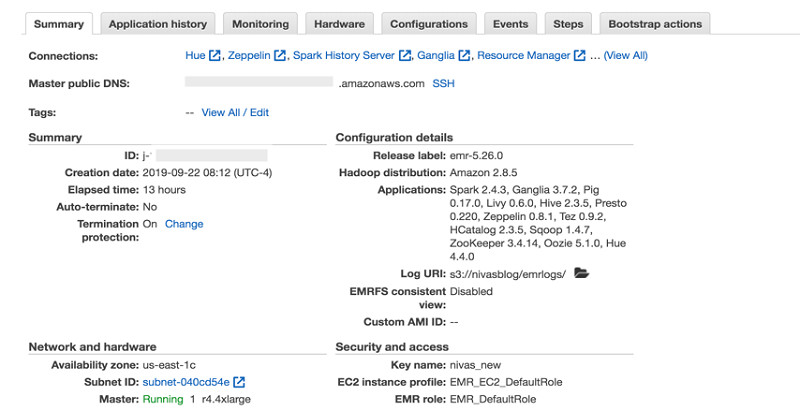
启用Dr. Elephant或Sparklens
如果大家已经运行有一套持久集群,则可使用以下步骤启用Dr. Elephant或Sparklens。详见以下代码:
aws emr add-steps --cluster-id j-XXXXXXXX --steps '[{"Args":["s3://aws-bigdata-blog/artifacts/aws-blog-hadoop-spark-performance-tuning/install-dr-elephant-emr5.sh"],"Type":"CUSTOM_JAR","ActionOnFailure":"CONTINUE","Jar":" s3://elasticmapreduce/libs/script-runner/script-runner.jar","Properties":"","Name":"Install Dr. Elephant and Sparklens"}

验证对Dr. Elephant portal及Sparklens设置的访问
要访问Dr. Elephant,请通过浏览器访问端口8087上的主节点地址:
https://<< DNS Name.compute-1.amazonaws.com>>:8087
注意:您需要使用动态或本地端口转发建立指向主节点的SSH隧道。
以下截屏所示,为Dr. Elephant仪表板中列出的、对EMR集群内所提交作业的最新分析结果。
要验证Sparklens,大家需要使用SSH接入主节点。关于更多详细信息,请参阅使用SSH接入主节点。
在控制台上运行以下命令:
cd /etc/spark/conf/
启动PySpark并检查已启用的设置,详见以下代码:
[hadoop@ip-172-31-20-142]$ pyspark
我们可以在代码当中看到以依赖项形式添加的qubole#sparklens一行。以下截屏所示,代表已经在EMR集群上启用了Sparklens:
Sparklens – 测试Spark工作负载
现在,我们可以在EMR集群上测试Spark工作负载,并通过Sparklens日志进行观察了。
本文将使用PySpark代码测试一个包含1000亿条记录的示例数据生成器,并观察Sparklens如何帮助优化并提供调优处理建议。请完成以下操作步骤:
- 将代码复制至EMR集群当中。
- 导航至
/home/hadoop/ - 通过
test-spark.py输入以下代码: - Run
spark-submit test-spark.py.
以下截屏所示,为Sparklens作业的提交信息:
以下截屏所示,为Sparklens收集到的应用程序任务指标:
以下截屏所示,为作业运行时长的时间指标:
以下截屏所示,为Sparklens关于应用程序作业提交时间优化提供的建议:
根据Sparklens提供的建议,当前应用资源下最短可能运行时间应为23秒,而默认设置的执行时间为50秒,计算时间浪费为76.15%,相当于计算周期的实际使用比例只有30.98%。
大家可以减少 spark-submit作业中的执行程序数与执行程序核心,并查看这一调整会给结果带来怎样的改变。
输入以下代码:
spark-submit --num-executors 1 --executor-cores 1 test-spark.py
以下截屏所示,为作业调优之后Sparklens作业中的应用指标: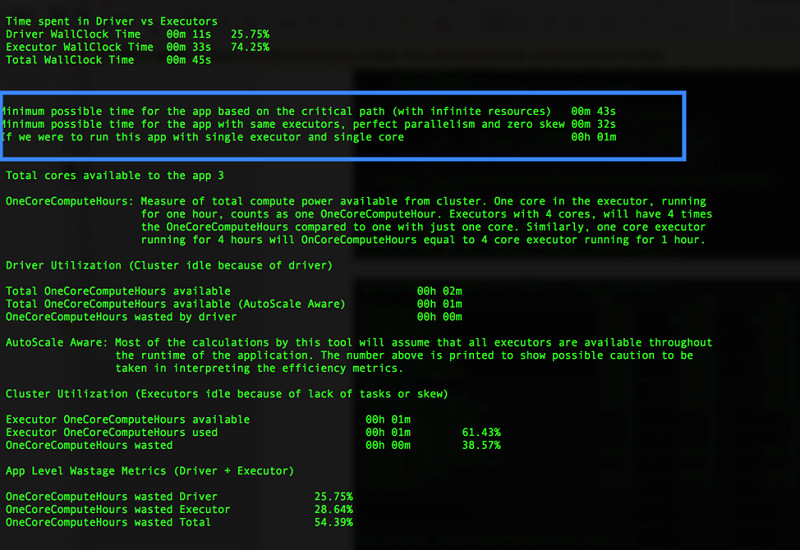
现在作业完成时间减少至45秒,且只需要1个执行节点与1个核心节点即可运行该作业。这有助于确定各个阶段(例如driver、skew或者lack of tasks)对Spark应用性能造成的实际影响,并提供关于这些阶段可能出现的问题的上下文信息。
本文使用三款原生支持应用(Scala、Java与Python)对之前提到的Pi估算示例进行测试。关于更多详细信息,请参阅编写一款Spark应用程序。要运行测试,请完成以下步骤:
- 输入以下代码:
- 将Spark示例代码复制至本地目录。
- 通过
spark-submit命令运行代码。参见以下代码:spark-submit test-spark2.py
以下截屏所示,为Sparklens作业的提交信息:
以下截屏所示,为Sparklens收集到的应用程序任务指标:
以下截屏所示,为Sparklens关于应用程序作业提交时间优化提供的建议:
以下截屏所示,为Sparklens集群计算利用率指标:
以下截屏所示,为Sparklens就集群内各核心计算节点实际资源利用率与预估利用率提出的建议:
在测试中,Sparklens的建议认为应用程序资源的最短可能运行时长为10秒,而默认设置的执行时间为14秒。默认设置的计算时间浪费比例达87.13%,相当于只有12.87%的计算时长得到实际使用。
在Spark应用程序的单次运行当中,Sparklens可以在给定任意数量执行节点的情况下估算您的应用程序性能,借此帮助您了解添加执行节点的投资回报率(ROI)。从内部来看,Sparklens还具有分析器的概念,分析器属于专门发送特殊事件的通用组件。关于分析器的更多详细信息,请参阅GitHub repo。
大家可以减少spark-submit作业中的执行节点与执行核心数量,并查看给运行结果带来的实际影响。具体请参见以下代码:
spark-submit --num-executors 2 --executor-cores 2 test-spark2.py
以下截屏所示,为Sparklens作业的提交信息:
以下截屏所示,为经过调优之后的Sparklens作业应用指标:
现在,作业完成时间被缩短至12秒,且作业只需要1个执行节点与相应计算核心即可完成。
Dr. Elephant测试Hive/MapReduce工作负载
我们可以在EMR集群当中测试各类场景,并通过Dr. Elephant Portal观察测试结果。
测试Hive负载与性能分析
大家可以通过Hive CLI控制台加载示例数据集,并查看工作负载的具体执行方式、获取性能优化建议。
本文将演示如何使用Hive分析存储在Amazon S3当中的Elastic Load Balancer访问日志。请完成以下操作步骤:
- 在Hive CLI上,输入以下代码:
以下截屏所示,为通过hive创建外部表:
- 运行一项简单的计数查询,并检查Dr. Elephant提供的建议。详见以下代码:

- 启动Dr. Elephant Portal。以下截屏所示,为Dr. Elephant的输出结果。其中Hive作业需要对Tez Mapper内存进行些许调整。

- 在应用指标高亮部分点击Tez Mapper Memory部分。以下截屏所示,为Dr. Elephant就Tez Mapper Memory过度分配问题提出的建议:

- 使用下调后的Mapper内存再次运行Hive查询,详见以下代码:
set hive.tez.container.size=1024;SELECT RequestIP, COUNT(RequestIP) FROM elb_logs WHERE BackendResponseCode<>200 GROUP BY RequestIP



以下截屏所示,为所提交作业的应用指标:
以下截屏所示,代表Dr. Elephant在查询中未发现其他错误/警告:
对map reduce作业进行调优
要对map reduce作业进行调优,请使用默认设置运行以下Pi代码示例:
hadoop-mapreduce-examples pi -D mapreduce.map.memory.mb=4096 -D mapreduce.reduce.memory.mb=4096 200 1000000
以下截屏所示,为所提交作业的应用指标:
以下截屏所示,为Dr. Elephant显示出的需要进行调整的Mapper时间、map内存以及reduce内存:
以下截屏所示,为Dr. Elephant对Mapper Memory提出的改进建议:
以下截屏所示,为Dr. Elephant对Reducer Memory提出的改进建议:
现在,我们可以将Mapper与Reducer内存设置为以下值:
set mapreduce.map.memory.mb=4096
set mapreduce.reduce.memory.mb=4096
我们也可以减少映射器数量,并增加各映射器的样本量,以获得相同的Pi结果。详见以下代码:
hadoop-mapreduce-examples pi -D mapreduce.map.memory.mb=4096 -D mapreduce.reduce.memory.mb=4096 100 2000000
以下截屏所示,为根据建议调优后的改进指标:
可以看到,这项作业的效率提升了50%,运行时间由约60秒缩短至38秒。
大家可以运行10个 mappers并获得更高的执行效率。详见以下代码:
hadoop-mapreduce-examples pi -D mapreduce.map.memory.mb=4096 -D mapreduce.reduce.memory.mb=4096 10 2000000
以下截屏所示,为采用Dr. Elephant调优建议之后的改进指标:
Dr. Elephant对Amazon EMR集群进行全面监控,并为Hive及Hadoop作业优化提供指导意见。
配置生产工作负载
要对Dr. Elephant工具进行调优,请导航至/mnt/dr-elephant-2.1.7/app-conf目录并据此编辑各配置文件。
例如,大家可以编写启发式代码,并将其插入Dr. Elephant工具以设置特定条件,根据任务数量与严重性做出调整,并随时调整集群容量中用于map或reduce的比例。大家还可以变更用于分析已完成作业的线程数量,或者在资源管理器中指定数据获取间隔。
以下截屏所示,为可根据需求做出进一步调优及定制的Dr. Elephant配置文件列表:
关于指标与配置的更多详细信息,请参考GitHub repo。
总结
本文介绍了如何在Amazon EMR集群上启动Dr. Elephant与Sparklens工具,以及如何尝试针对计算与内存密集型作业做出优化与性能调整。Dr. Elephant与Sparklens可以帮助大家提高数据集并行性与计算节点利用率,借此加快作业执行速度并提高内存管理效率。凭借工作负载调优与集群并行性控制,这两款工具还能帮助大家克服Spark与Hive作业处理中常见的各类挑战。