背景
在很多客户使用Amazon S3服务一段时间之后,都可能有成本优化方面的考量。一般在现实状况下,由于多年的数据堆积和后期系统开发等方面因素,并不能很准确定义出存储桶中的数据情况(比如某个文件夹下面有多少文件是30天以内需要访问的,多少文件是30天之外会访问的,多少文件是0KB的文件,多少文件是小于128KB的文件等)。在这种状况下进行S3费用优化,过程中可能会遇到很多问题,甚至不恰当的优化方式不但不会降低成本反而会导致费用的进一步增加。所以不能仅靠粗略估计,而是需要通过更细致的分析进行各种优化方式的优劣对比,找到最合适的优化方案。本文将带大家详细了解一下S3成本优化的最佳实践过程。
S3存储类型概要
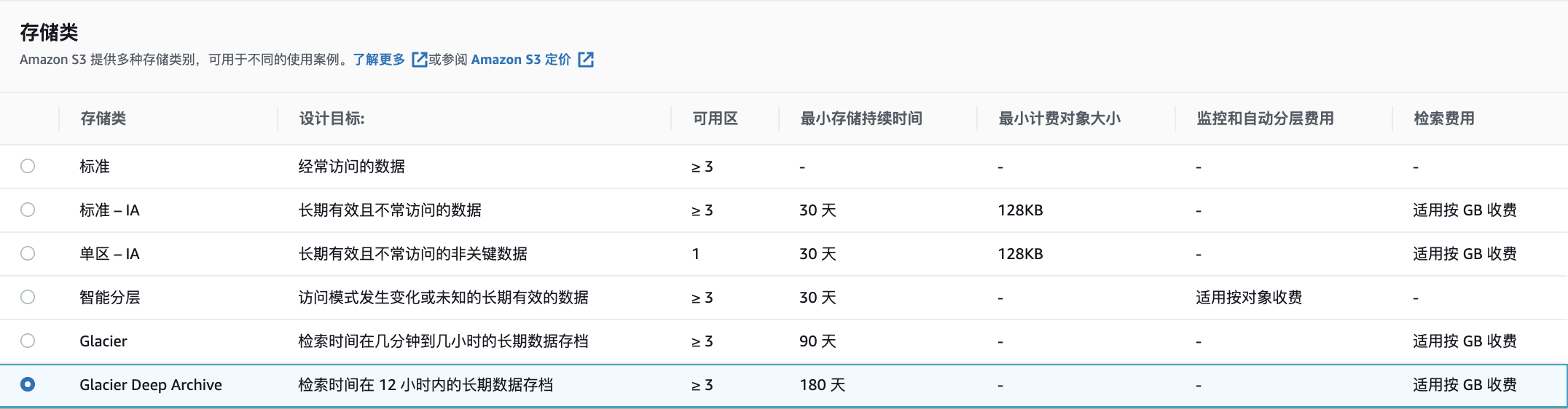
S3存储类型分为5种(低冗余存储官方已经不再建议使用,所以排除在外),分别是:1. S3标准2. S3智能分层3. S3-IA (包括one zone)4. S3 Glacier5. S3 Glacier Deep Archive 。 S3并不是只是简单的按照数据用量来收费,不同的类型有不同的价格,并且在数据使用费之外,还有其他费用,例如据请求费和检索费等。从1-5,数据存储费越来越便宜,但是请求和数据检索的费用却越来越贵。所以S3的使用总费用是数据存储费+请求检索费+数据传输费用+存储类型转换费。 下图以1000个文件,总大小1GB在美东1区佛吉尼亚北部的费用为例:

S3成本优化过程
下面我们开始讲解具体的操作步骤 (注意以下提到的内容不涉及到开启了版本控制的桶,对于开启了版本控制的桶虽然逻辑相同,但是一些查询方法会有差别,请酌情参考),以下价格全部以美东1 佛吉尼亚北部为例,具体价格可以参考以下页面:https://thinkwithwp.com/s3/pricing/
1.使用生命周期清理未完成的分段上传
分段上传文件,是指一些大文件上传的时候自动分成几个小分段,但是传输过程中某几个分段失败了,留下了其他的不完整文件分段。由于这部分文件是隐藏文件但是也占用空间,因而在做真正的优化之前,除非应用有特别需求,一般情况都建议把这部分文件从桶上删除掉。如果想了解一个桶上有多少multi-upload文件,可以使用CLI – aws s3api list-multipart-uploads –bucket my-bucket 进行查询,或者也可以联系AWS支持中心或您的专属TAM来获取这部分具体信息。对于一些客户,这部分文件的使用量可能达到一个桶的10%,比如20PB的S3桶,2PB都是不必要的未完成传输文件分段。 参考以下文档对整桶配置生命周期根据需要清理这些未完成文件分段,使用生命周期删除文件不会产生额外费用(但是对于Glacier/Glacier Deep Archive/IA有例外情况,详情请参考本系列的下一篇博客文章)
https://docs.thinkwithwp.com/zh_cn/AmazonS3/latest/dev/mpuoverview.html#mpu-abort-incomplete-mpu-lifecycle-config
2.开启S3清单
做任何S3成本优化之前,建议开启S3清单(inventory)功能,这样可以借助aws athena服务来查询s3 清单中的内容从而更准确地确认各种存储类型的文件列表以及文件数目等详细信息。
S3 清单价格: 每百万个所列对象 0.0025 USD – 一个桶如果有10亿文件数的话,开一次清单收费2.5$
Athena 查询费用:每 TB 扫描数据 5.00 USD – 一个桶如果有10亿文件数的话,大概清单文件为30-40GB,查询1次价格为0.2$.
可以看到使用这两个功能的价格跟节省成本比较几乎可以忽略不计
请注意,请开启S3清单功能的时候选择CSV格式并且选择每周刷新数据,这样可以减少生成的文件数量,便于查询。
如何开启S3清单: S3 控制台–管理–清单–新增

选择大小,上次修改日期,存储类别,默认选仅限当前版本。如果桶开启了多版本,需要选择“包括所有版本“。

3.对清单文件建立Athena表并查询
在开启 s3清单功能后,可能需要多达48小时才能收到第一份S3清单文件,一般情况下生成清单时间少于24小时。清单文件csv生成之后,请按照下列方式在Athena服务中建立一个清单表,以供查询使用。第一次使用Athena点击“入门”之后可能会需要您设置在S3中的查询结果位置。详情参见文档https://docs.thinkwithwp.com/zh_cn/athena/latest/ug/getting-started.html
如何使用语句建立S3清单的Athena table:( 请修改 `inventory_list` 为新表名,并修改’s3://inventory/testinventory/data/hive’为新生成的S3清单地址下的hive前缀)
CREATE EXTERNAL TABLE `inventory_list`(
`bucket` string,
`key` string,
`size` bigint,
`last_modified_date` string,
`storage_class` string)
PARTITIONED BY (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION
's3://inventory/testinventory/data/hive'
详细如何查询Athena清单表的语句:
-- 按照某天生成的清单,查询桶内有多少存储类型:
Select distinct storage_class from inventory_list where dt='YYYY-MM-DD-00-00'
-- 比如按照2020-05-20生成的清单查询:
Select distinct storage_class from inventory_list where dt='2020-05-20-00-00'
-- 查询每个存储类型有多少个文件,文件量多大:(根据上个语句查询出来总共有多少存储类型,按照每个存储类型进行单独查询)
select count(*) as count ,sum(size)/1073741824 as GB from inventory_list where storage_class = 'STANDARD' and dt='YYYY-MM-DD-00-00'
select count(*) as count ,sum(size)/1073741824 as GB from inventory_list where storage_class = 'GLACIER' and dt='YYYY-MM-DD-00-00'
select count(*) as count ,sum(size)/1073741824 as GB from inventory_list where storage_class = 'XXXXX' and dt='YYYY-MM-DD-00-00'
select count(*) as count ,sum(size)/1073741824 as GB from inventory_list where storage_class = 'XXXXX' and dt='YYYY-MM-DD-00-00'
select count(*) as count ,sum(size)/1073741824 as GB from inventory_list where storage_class = 'XXXXX' and dt='YYYY-MM-DD-00-00'
-- 查询每个storage class,0KB的文件有多少
select count(*) as count from inventory_list where storage_class = 'STANDARD' and size=0 and dt='YYYY-MM-DD-00-00'
select count(*) as count from inventory_list where storage_class = 'XXXXXX' and size=0 and dt='YYYY-MM-DD-00-00'
-- 查询标准的storage class, 大于0KB小于128KB的文件有多少。
select count(*) as count ,sum(size)/1073741824 as GB from inventory_list where storage_class = 'STANDARD' and size > 0 and size < 128*1024 and dt='YYYY-MM-DD-00-00'
-- 查询标准的storage class, 小于8KB的文件有多少。
select count(*) as count ,sum(size)/1073741824 as GB from inventory_list where storage_class = 'STANDARD' and size <= 8*1024 and dt='YYYY-MM-DD-00-00'
-- 查询某一些文件夹下的文件大小和文件数量有多大,之后可能会排除某些文件夹不做转换。
select count(*) as count ,sum(size)/1073741824 as GB from inventory_list where key like 'logs%' and dt='YYYY-MM-DD-00-00'
-- 查询30天以内创建的standard存储类型文件具体数量和大小:
select count(*) as count ,sum(size)/1073741824 as GB from inventory_list where storage_class = 'STANDARD' and from_iso8601_timestamp(last_modified_date) > CAST((current_timestamp - interval '30' day) AS DATE) and dt='YYYY-MM-DD-00-00'
-- 如果需要使用S3批处理进行存储类型转换,那么按照特定要求生成我们需要的S3 批处理使用的csv文件,之后使用Athena“save as”功能下载之后,上传到某个存储桶作为 S3批处理的输入文件
Select bucket,key from inventory_list where key not like 'logs%' and size > 128*1024 and storage_class = 'STANDARD' and dt='YYYY-MM-DD-00-00'
4.查询上一个月的CUR,列出关于某个桶的具体用量信息
如何设置CUR(Cost Usage Report)在本文中就不再复述,请参考文档开启CUR并且建立好Athena表。
https://docs.thinkwithwp.com/zh_tw/cur/latest/userguide/cur-ate-setup.html
常用CUR select 语句如下,请替换default.cur_table和bucket_name为您自己环境中的资源名。
-- 查询某个桶的上个月整月详细用量
SELECT
bill_billing_period_start_date,
bill_billing_period_end_date,
line_item_resource_id,
product_product_name,
line_item_operation,
sum(CAST(line_item_unblended_cost AS DOUBLE)) cost,
sum(CAST(line_item_usage_amount AS DOUBLE)) "usageamount(GB/count)"
FROM
default.cur_table
WHERE
product_product_name = 'Amazon Simple Storage Service'
and line_item_resource_id='bucket_name'
and bill_billing_period_start_date >= date_trunc('month',DATE_ADD('day', -1, date_trunc('month', now())))
and bill_billing_period_end_date <= date_trunc('month', now())
GROUP BY
1,2,3,4,5
ORDER BY
sum(CAST(line_item_unblended_cost AS DOUBLE)) desc;
查询结果中显示的具体的收费项目 line_item_operation在以下链接中可以找到
https://docs.thinkwithwp.com/zh_cn/AmazonS3/latest/dev/aws-usage-report-understand.html
5.根据查询结果,核算不同的方案产生的每个月费用,进行对比
关于常见的数据转换方案和优劣对比,可以参考如下表格。

6.根据核算结果,首先决定是否有数据需要删除,删除不需要的数据
S3删除数据无额外费用,所以如果经过清单分析,发现有一些数据可以删除,建议使用生命周期先对这些数据进行删除。生命周期是通过对特定标签(tag)或者前缀(prefix)进行操作,具体分为两种情况:
(1)如果可以确认某些前缀的文件可以完全删除,那么可以直接用生命周期直接对这个前缀下的文件直接删除处理(设置过期时间为1天)
(2)如果不是某个前缀下所有的文件都可以删除,那么可以选择对特定的标签(tag)操作,不过需要先使用S3批处理功能对需要的文件打标签。(注意,批处理可以替换所有对象标签,如果已有标签也会被替换掉)
-- 比如查找所有1年前生成的日志文件列表:
Select bucket,key from inventory_list where key like 'logs%' and storage_class = 'STANDARD' and from_iso8601_timestamp(last_modified_date) < CAST((current_timestamp - interval '365' day) AS DATE) and dt='YYYY-MM-DD-00-00'
然后对生成的CSV清单进行处理,S3批处理使用方式通过: s3控制台界面–批处理操作–创建作业–清单格式csv–替换所有对象标签
当批处理作业完成之后再对整桶的某个标签(tag)做生命周期删除(设置过期时间为1天)
7.针对不能删除的数据,根据核算出的最佳方案,使用生命周期或者S3批处理来进行文件存储类型转换,完成优化。
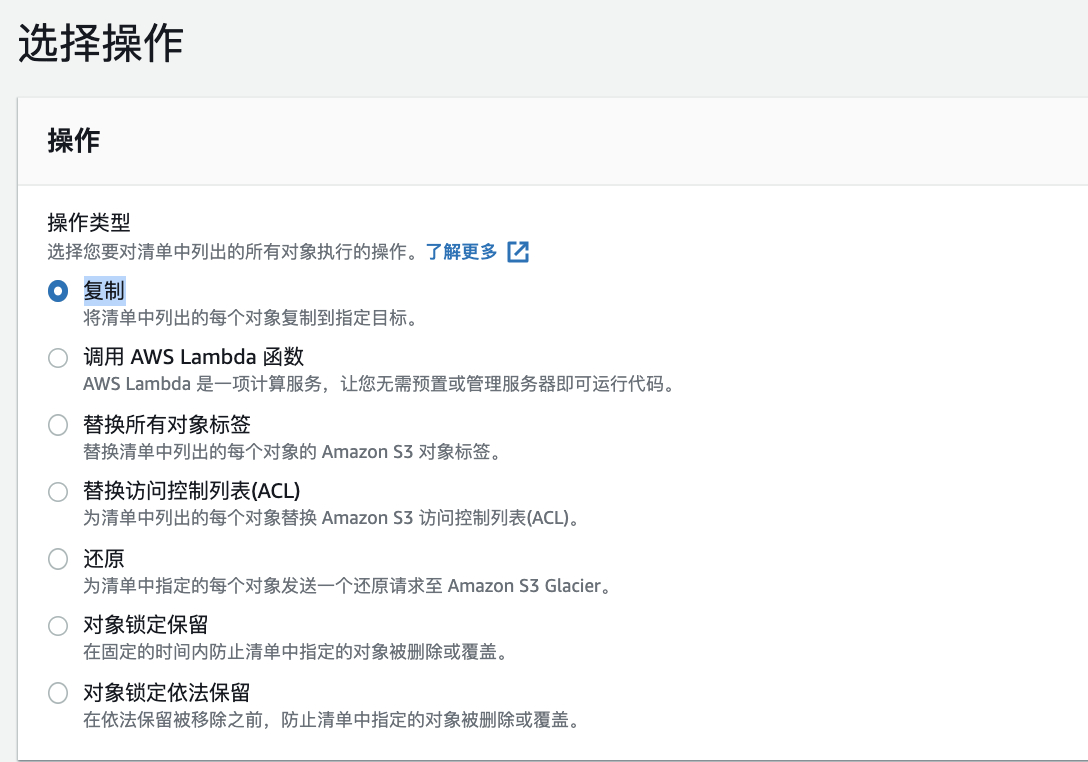
对于生命周期的使用就不再赘述(参见步骤5中的方案比较)。使用S3批处理转换存储类型通过 : s3控制台界面à批处理操作–创建作业–清单格式csv–复制–选择存储类, 选择以下选项,其他设置请保持默认。



总结
请关注我们系列中的下一篇博客文章,在该文章中,我们会详细列举一下S3优化过程中遇到的常见问题,以及如何解决。
本篇作者