亚马逊AWS官方博客
通过 Rekognition 实现无服务器智能相册
简介
在本文的案例中我们将通过Amazon Rekognition对我们的照片进行人脸检测,再将检测到的人脸与私有人脸集合进行比对,来识别特定库中的人物,进而对图片做分类关联,如通过班级学生照片、家庭人员照片构建人脸集合,再将任意合照作为输入时,可以标注出照片中特定班级、家庭人员信息,在功能上我们主要使用面孔检测、分析、搜索、验证相关功能。
Amazon Rekognition 是亚马逊基于面部识别的一个项目,以人工智能和机器学习为中心。借助Amazon Rekognition我们可以在图像和视频中识别对象、人物、文本、场景和活动,也可以检测任何不适宜的内容。Amazon Rekognition 还提供高度精确的面孔分析和面孔搜索功能,可以使用这些功能来检测、分析和对比面孔,以处理各种用户验证、人员计数和公共安全使用案例。
应用场景
Amazon Rekognition拥有非常丰富的功能,主要应用场景包括以下:
图像标注:可以识别数千种对象(例如自行车、电话、建筑)和场景(例如停车场、海滩、城市)。在分析视频时,您还可以识别具体活动,例如“包裹配送”或“踢足球”。
自定义标签:通过自定义标签我们可以轻松扩展Amazon Rekognition的检测功能,例如,您可以构建模型来对装配线上的特定机器部件进行分类,或检测运行状况不佳的工厂。
内容审核:可帮助您识别图像和视频资产中潜在的不安全或不适宜的内容
文本检测:可以读取倾斜和失真的文本,从而捕获商店名称、街道标志和产品包装上的文本等信息。
面孔检测、分析:可以轻松检测面孔在图像和视频中出现的时间,并针对每张面孔获取性别、年龄范围、眼睛睁开程度、眼镜、面部毛发等属性。在视频中,您也可以衡量这些面孔属性随时间的变化,比如构建一个演员所表达情感的时间线。
面孔搜索、验证:可以自定义私有面孔图像人脸集合来识别照片或视频中特定任务。
名人识别:您可以快速识别视频和图像库中的名人,以便为市场营销、广告和媒体行业使用案例编录录像和照片。
轨迹:用于视频文件时,您可以捕捉场景中人物的轨迹。例如,您可以使用运动员在比赛期间的移动情况来确定战术,并进行赛后分析。
整体架构
一、AWS服务需求
Amazon API Gateway,可以帮助开发人员轻松创建、发布、维护、监控和保护任意规模的 API。
Amazon S3,对象存储服务,提供行业领先的可扩展性、数据可用性、安全性和性能。
Amazon SQS, 消息队列服务,可以帮助分离和扩展微服务、分布式系统和无服务器应用程序。
Amazon Lambda,几乎可以为任何类型的应用程序或后端服务运行代码,而且完全无需管理。
Amazon Rekognition,基于深度学习的图像识别服务,可以检测对象、场景和面孔;提取文本;识别名人;以及标识图像中的不当内容。
二、架构说明
应用分为两部分:私有人脸集合构造、人脸检测与识别
浅绿色背景部分为私有人脸集合构造部分,通过服务器上传照片文件到S3中,S3会将消息通过SQS传递给Lambda,Lambda中通过SDK提供的方法创建特定的人脸集合,当上传的图片在S3中的前缀一致时,将会添加到同一个集合中。
浅红色背景部分为人脸检测与识别部分,前端应用调用API Gateway发布的API并将需要检测的图片数据(base64)放在请求中,API Gateway将请求发送至相应的Lambda,Lambda使用AWS Rekognition进行人脸识别并提取图片中所有的人脸,再调用AWS Rekognition将每张人脸与特定集合进行比对,最终返回图片中所有人脸位置及比对结果,此外还会包含一部分人脸特征预测信息(年龄、性别预测等)。

私有人脸集合构造
- 在进行检测和识别之前需要构造人脸集合,我们通过S3对象存储桶来存储需要构造人脸集合的图片。S3可以监听特定前缀/后缀文件的特定事件,并将相应信息发送到指定后端,如.jpg后缀文件的对象创建事件发生时,会将文件meta-data及事件本身的信息发送给AWS SQS服务。
- AWS SQS在架构中一方面做异步的解耦,一方面我们可以更好的对消息的消费进行管理(延迟、重试等),此外AWS SQS中也有trigger的功能,可以和lambda进行关联,当有消息时会通知Lambda进行消费。
- 当Lambda通过SQS获取图片对象创建的事件及详细信息后,会读取图片数据并调用AWS Rekognition提供的接口,创建相应的Collection,Collection ID为图片对象的前缀,如上图所示,前缀为Singer、Moviestar的图片上传时,会分别用来构建/添加图片特征到Singer、Moviestar人脸集合,若图片上传到根目录,则人脸集合名称为“default”。
- 此外需要注意的是,每张照片的描述信息为上传的文件名称,后续比对成功则会返回该描述信息,如具体的人名(目前不支持中文)。
- AWS Rekognition收到请求后创建相应的人脸集合,一个人脸集合中可存储的最大人脸数目为2000万。
人脸检测与识别
- 客户端调用API Gateway的接口上传任意照片数据,根据客户业务逻辑获取要比对的集合collection_id,完整请求的body如下:
注:Threshold为相似度阈值,低于阈值的结果将不会输出,有多个匹配结果会输出阈值最高的结果
- 请求通过API Gateway会转发给后端的Lambda处理,Lambda会根据request中的内容,先对图片进行人脸检测,获取图片中所有的人脸位置(单张照片最大支持100张人脸),对每张人脸进行剪裁,再将剪裁后的人脸与特定人脸集合做比对,对比对后的结果做阈值过滤,最终输出结果示例如下:
1)比对不成功的会返回检测到的人脸位置,以及识别的部分人脸特征(如年龄、性别),如有必要可添加更多特征输出(如:是否微笑、戴眼镜等)
2)比对成功测出了返回人脸位置及部分特征外,还会返回人脸集合中人脸的描述信息
构建步骤
一、创建临时文件桶

- 登陆控制台,选择日本区域
- 查找S3服务

- 创建存放临时文件的S3桶

二、上传相关临时文件
在后续验证环节需要通过该包对图片数据进行处理,Lambda默认自带的环境中没有提供该包,需要我们上传构建Lambda layer
- 打开刚才创建的桶,默认参数上传包文件

三、通过Cloudformation实现一键部署
- 下载yaml文件
- 搜索Cloudformation服务,点击创建堆栈
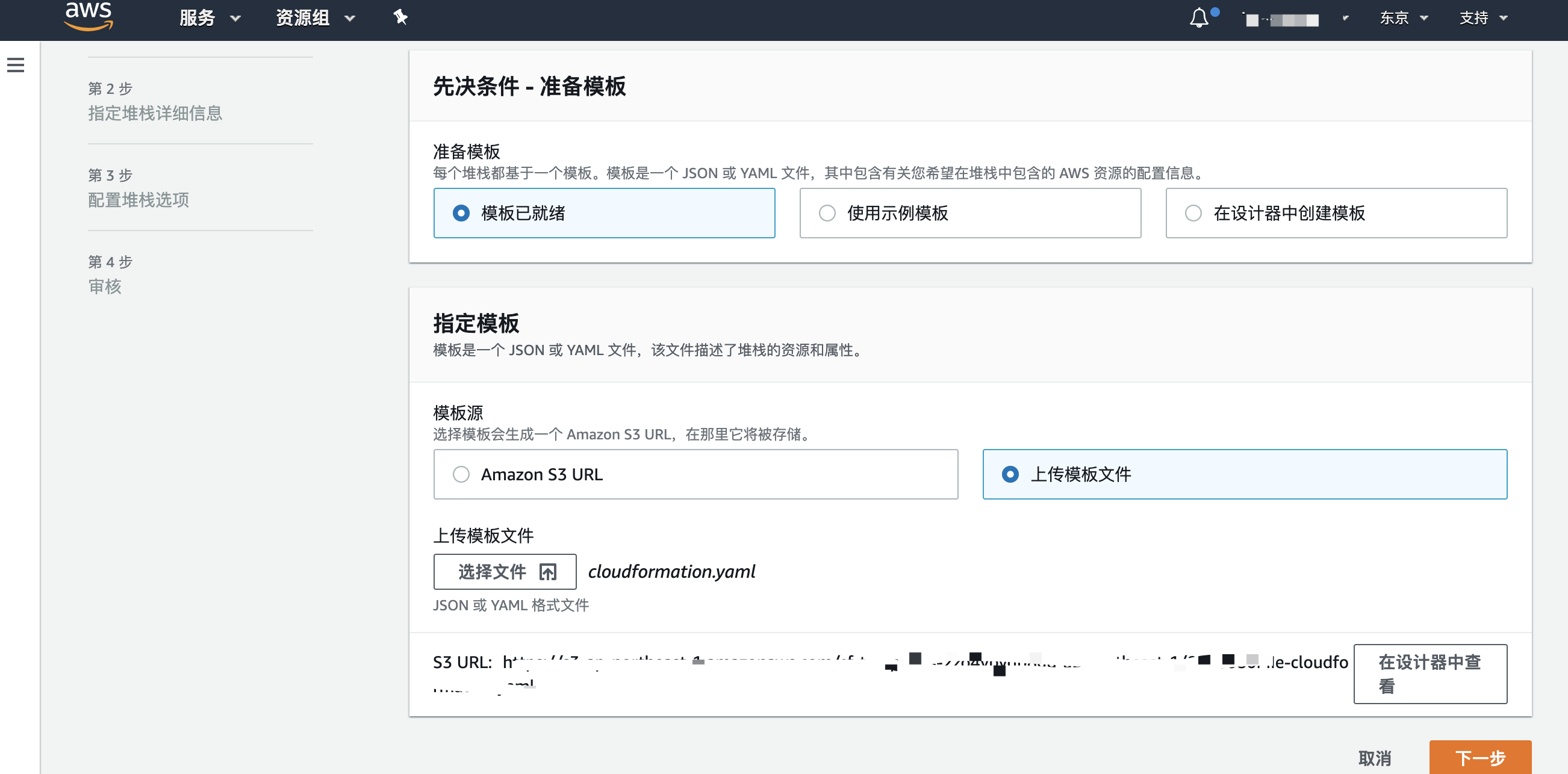
- 选择上传模版文件并选择下载的yaml文件
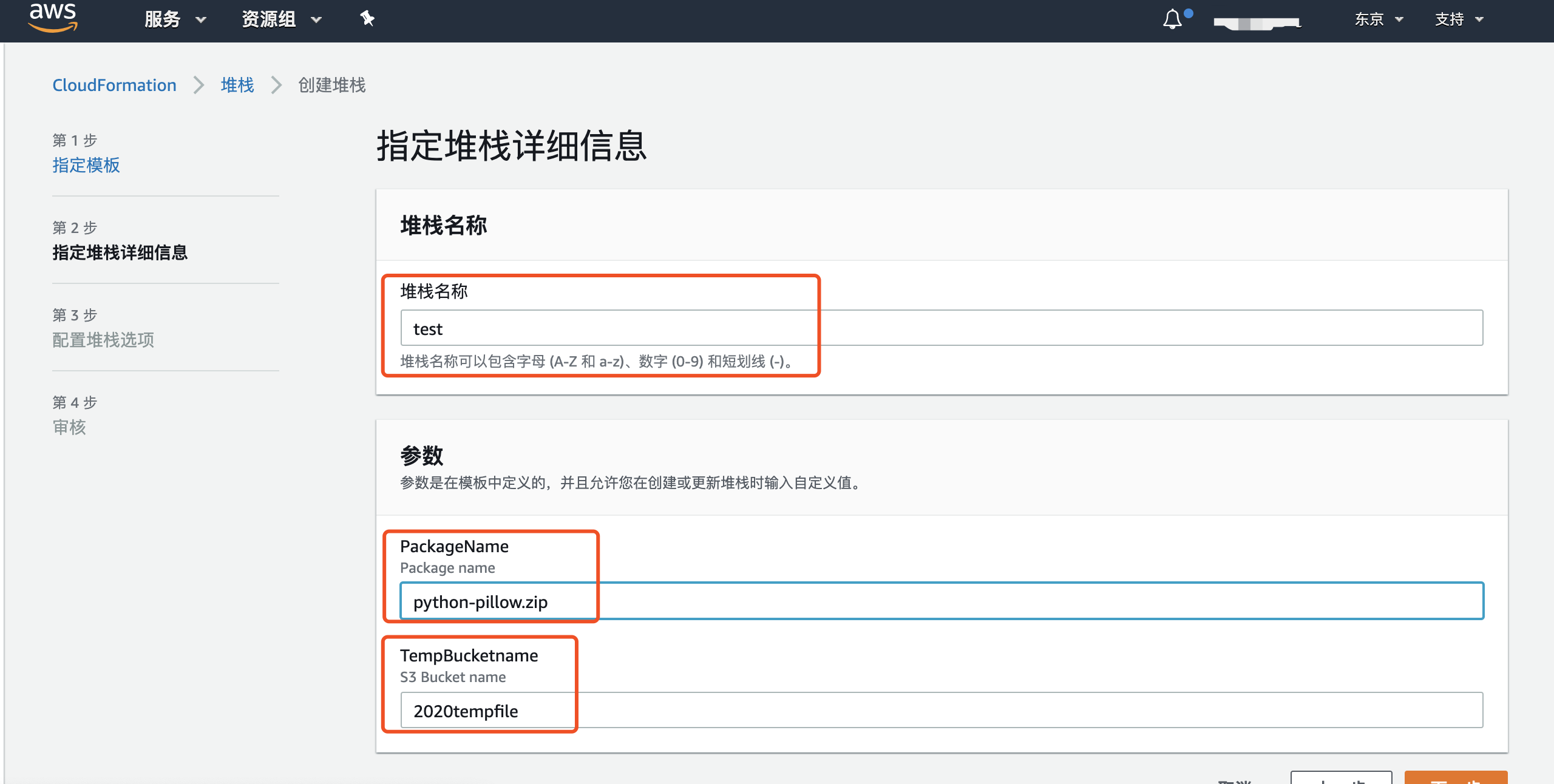
- 输入堆栈名称,以及临时桶的名称、python-pillow包名称,点击下一步

- 等待部署完成(1~2分钟),点击输出选项卡记录apiGatewayInvokeURL

四、功能验证
- 下载测试照片文件
- 将压缩包解压
- 在创建好的S3桶(前缀为堆栈名称)中创建文件夹,如music

- 上传照片到创建好的文件夹中
- 将下述内容保存成脚本文件,如script.py
- 按如下方式运行脚本获取结果
python script.py <img> <api path>
其中:
<img> 为测试照片地址
<api path> 为cloudformation输出中的apiGatewayInvokeURL
例如:
清理资源
一、删除基础架构
- 搜索cloudformation服务,选择堆栈后点击删除

二、删除AWS Rekognition中的数据
- 创建访问密钥
- 安装awscli工具并配置
安装参考:https://thinkwithwp.com/cn/cli/

- 删除AWS Rekognition中的数据
替换<>标注部分
music为S3中创建的文件夹,如文档中使用的music
ap-northeast-1为选择的区域,如文档中使用的日本区域
aws rekognition delete-collection –collection-id <music> –region <ap-northeast-1>
总结
方案中仅仅用到了Rekognition的一小部分功能,客户可根据自己的需求做定制开发新功能,包括视频面孔搜索分析、名人识别、物体和场景检测等等,文档中部分参数和返回值做了处理,客户也可以根据需要做一些深度集成。此外整个方案采用无服务器架构,无需客户运维管理,按请求计费,降低了服务成本。最后借助于Cloudformation可在全球区域进行部署与迁移,增加了速度和灵活性。
参考
Amazon Rekognition 官方文档:https://docs.thinkwithwp.com/zh_cn/rekognition/latest/dg/what-is.html
AWS Lambda 官方文档:https://docs.thinkwithwp.com/zh_cn/lambda/?id=docs_gateway
Amazon API Gateway 官方文档:https://docs.thinkwithwp.com/zh_cn/apigateway/?id=docs_gateway
Amazon SQS 官方文档:https://docs.thinkwithwp.com/zh_cn/sqs/?id=docs_gateway
Amazon S3 官方文档:https://docs.thinkwithwp.com/zh_cn/s3/?id=docs_gateway