Amazon Kinesis Data Analytics介绍
如今各种企业每天都在面对持续不断生成的数据需要处理,这些数据可能来自移动或 Web 应用程序生成的日志文件、网上购物数据、游戏玩家活动、社交网站信息或者是金融交易等。能够及时地处理并分析这些流数据对企业来说至关重要,通过良好的流数据处理和应用,企业可以快速做出业务决策,改进产品或服务的质量,提升用户的满意度。
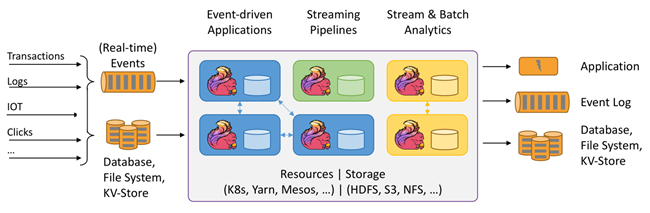
目前,市面上已经有很多工具可以帮助企业实现流数据的处理和分析。其中,Apache Flink是一个用于处理数据流的流行框架和引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
图片来自Apache Flink官网
Amazon Kinesis Data Analytics 是快速使用 Apache Flink 实时转换和分析流数据的简单方法,通过无服务器架构实现流数据的处理和分析。借助Amazon Kinesis Data Analytics,您可以使用基于Apache Flink的开源库构建Java、Scala以及Python应用程序。
Kinesis Data Analytics为您的Apache Flink应用程序提供底层基础设施,其核心功能包括提供计算资源、并行计算、自动伸缩和应用程序备份(以检查点和快照的形式实现)。您可以使用高级Flink编程特性(如操作符、函数、源和接收器等),就像您自己在托管Flink基础设施时使用它们一样。
在Amazon Kinesis Data Analytics使用Python
Amazon Kinesis Data Analytics for Apache Flink 现在支持使用 Python 3.7 构建流数据分析应用程序。这使您能够以 Python 语言在 Amazon Kinesis Data Analytics 上通过 Apache Flink v1.11 运行大数据分析,对Python语言开发者来说非常方便。Apache Flink v1.11 通过PyFlink Table API 提供对 Python 的支持,这是一个统一的关系型 API。

图片来自Apache Flink官网
此外,Apache Flink还提供了一个用于细粒度控制状态和时间的DataStream API,并且从Apache Flink 1.12版本开始就支持Python DataStream API。有关Apache Flink中API的更多信息,请参阅Flink官网介绍。
Amazon Kinesis Data Analytics Python应用程序示例
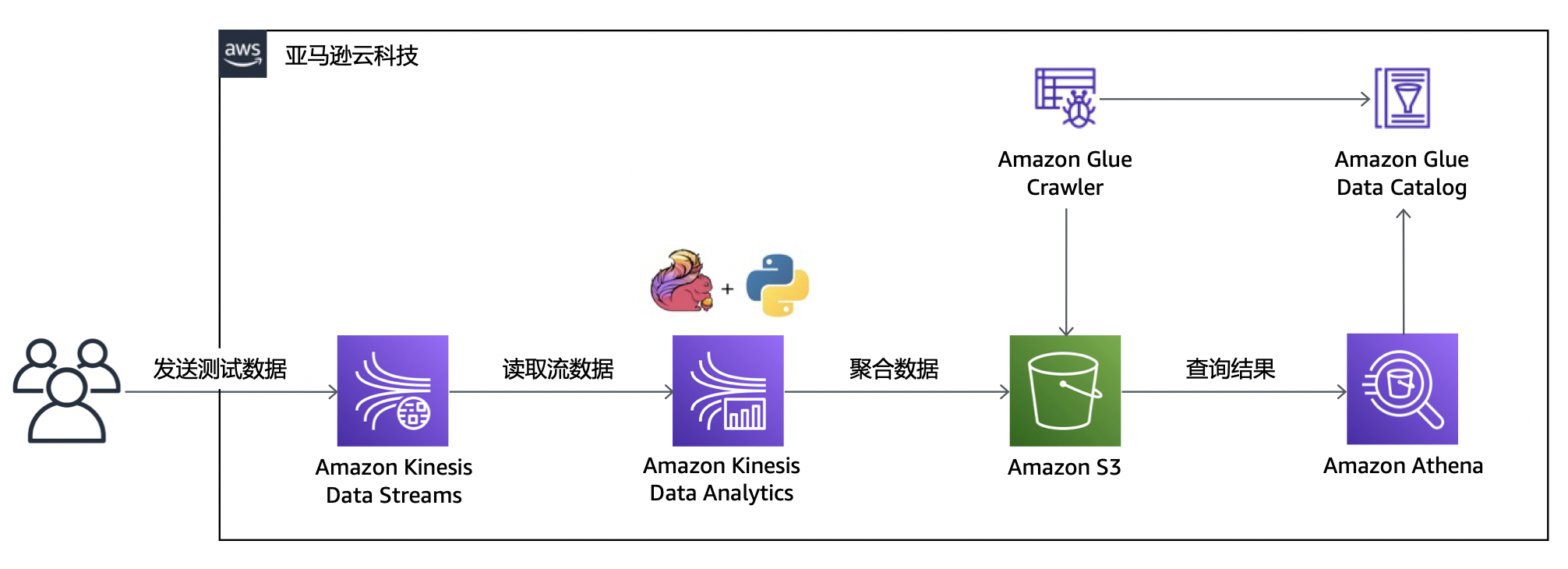
接下来,我们将演示如何快速上手构建Python版的Amazon Kinesis Data Analytics for Flink应用程序。示例的参考架构如下图所示,我们将发送一些测试数据到Amazon Kinesis Data Stream,然后通过Amazon Kinesis Data Analytics Python应用程序的Tumbling Window窗口函数做基本的聚合操作,再将这些数据持久化到S3中;之后可以使用Amazon Glue和Amazon Athena对这些数据进行快速的查询。整个示例应用程序都采用了无服务器的架构,在可以实现快速部署和自动弹性伸缩外,还极大地减轻了运维和管理负担。
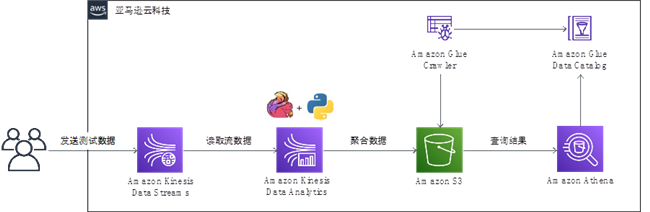
以下示例是在由光环新网运营的亚马逊云科技中国(北京)区域上进行。
创建Kinesis Data Stream
示例将在控制台上创建Kinesis Data Stream,首先选择到Amazon Kinesis服务-数据流,然后点击“创建数据流”。
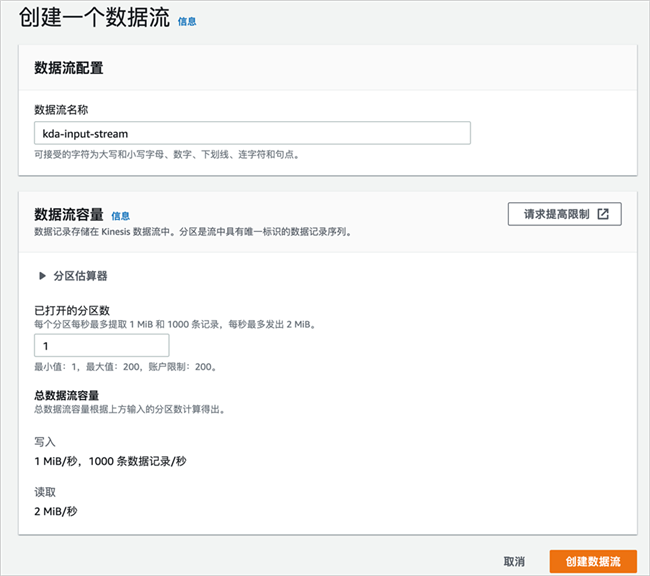
输入数据流名称,如“kda-input-stream“;数据流容量中的分区数设置为1,注意这里是为了演示,请根据实际情况配置合适的容量。
点击创建数据流,等待片刻,数据流创建完成。
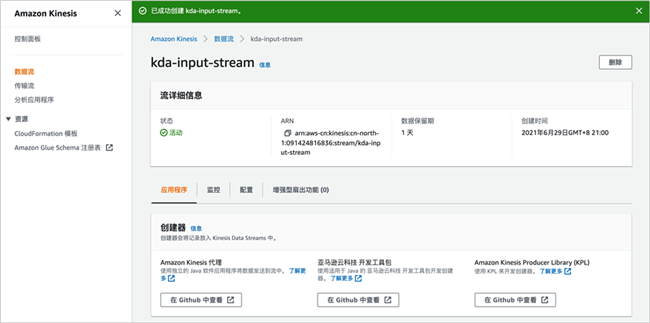
稍后,我们将像这个Kinesis数据流发送示例数据。
创建S3存储桶
示例将在控制台上创建S3存储桶,首先选择到Amazon Kinesis服务,然后点击“创建存储桶”。

输入存储桶名称,如“kda-pyflink-***”,这个名称稍后我们在Kinesis应用程序中用到。
保持其它配置不变,点击“创建存储桶”。
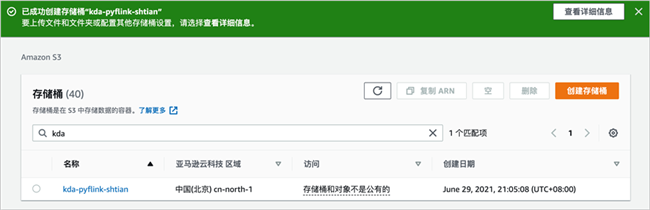
稍等片刻,可以看到已成功创建存储桶。
发送示例数据到Kinesis Data Stream
接下来,我们将使用一段Python程序向Kinesis数据流发送数据。创建kda-input-stream.py文件,并复制以下内容到这个文件,注意修改STREAM_NAME为您刚刚创建的Kinesis数据流名称,profile_name配置为对应的用户信息。
import datetime
import json
import random
import boto3
STREAM_NAME = "kda-input-stream"
def get_data():
return {
'event_time': datetime.datetime.now().isoformat(),
'ticker': random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV']),
'price': round(random.random() * 100, 2)}
def generate(stream_name, kinesis_client):
while True:
data = get_data()
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data),
PartitionKey="partitionkey")
if __name__ == '__main__':
session = boto3.Session(profile_name='<your profile>')
generate(STREAM_NAME, session.client('kinesis', region_name='cn-north-1'))
执行以下代码,开始向Kinesis数据流发送数据。
$ python kda-input-stream.py
编写Pyflink代码
接下来,我们编写PyFlink代码。创建kda-pyflink-demo.py文件,并复制以下内容到这个文件。
# -*- coding: utf-8 -*-
"""
kda-pyflink-demo.py
~~~~~~~~~~~~~~~~~~~
1. 创建 Table Environment
2. 创建源 Kinesis Data Stream
3. 创建目标 S3 Bucket
4. 执行窗口函数查询
5. 将结果写入目标
"""
from pyflink.table import EnvironmentSettings, StreamTableEnvironment
from pyflink.table.window import Tumble
import os
import json
# 1. 创建 Table Environment
env_settings = (
EnvironmentSettings.new_instance().in_streaming_mode().use_blink_planner().build()
)
table_env = StreamTableEnvironment.create(environment_settings=env_settings)
statement_set = table_env.create_statement_set()
APPLICATION_PROPERTIES_FILE_PATH = "/etc/flink/application_properties.json"
def get_application_properties():
if os.path.isfile(APPLICATION_PROPERTIES_FILE_PATH):
with open(APPLICATION_PROPERTIES_FILE_PATH, "r") as file:
contents = file.read()
properties = json.loads(contents)
return properties
else:
print('A file at "{}" was not found'.format(APPLICATION_PROPERTIES_FILE_PATH))
def property_map(props, property_group_id):
for prop in props:
if prop["PropertyGroupId"] == property_group_id:
return prop["PropertyMap"]
def create_source_table(table_name, stream_name, region, stream_initpos):
return """ CREATE TABLE {0} (
ticker VARCHAR(6),
price DOUBLE,
event_time TIMESTAMP(3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
)
PARTITIONED BY (ticker)
WITH (
'connector' = 'kinesis',
'stream' = '{1}',
'aws.region' = '{2}',
'scan.stream.initpos' = '{3}',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
) """.format(
table_name, stream_name, region, stream_initpos
)
def create_sink_table(table_name, bucket_name):
return """ CREATE TABLE {0} (
ticker VARCHAR(6),
price DOUBLE,
event_time TIMESTAMP(3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
)
PARTITIONED BY (ticker)
WITH (
'connector'='filesystem',
'path'='s3a://{1}/',
'format'='csv',
'sink.partition-commit.policy.kind'='success-file',
'sink.partition-commit.delay' = '1 min'
) """.format(
table_name, bucket_name)
def count_by_word(input_table_name):
# 使用 Table API
input_table = table_env.from_path(input_table_name)
tumbling_window_table = (
input_table.window(
Tumble.over("1.minute").on("event_time").alias("one_minute_window")
)
.group_by("ticker, one_minute_window")
.select("ticker, price.avg as price, one_minute_window.end as event_time")
)
return tumbling_window_table
def main():
# KDA 应用程序属性键
input_property_group_key = "consumer.config.0"
sink_property_group_key = "sink.config.0"
input_stream_key = "input.stream.name"
input_region_key = "aws.region"
input_starting_position_key = "flink.stream.initpos"
output_sink_key = "output.bucket.name"
# 输入输出数据表
input_table_name = "input_table"
output_table_name = "output_table"
# 获取 KDA 应用程序属性
props = get_application_properties()
input_property_map = property_map(props, input_property_group_key)
output_property_map = property_map(props, sink_property_group_key)
input_stream = input_property_map[input_stream_key]
input_region = input_property_map[input_region_key]
stream_initpos = input_property_map[input_starting_position_key]
output_bucket_name = output_property_map[output_sink_key]
# 2. 创建源 Kinesis Data Stream
table_env.execute_sql(
create_source_table(
input_table_name, input_stream, input_region, stream_initpos
)
)
# 3. 创建目标 S3 Bucket
create_sink = create_sink_table(
output_table_name, output_bucket_name
)
table_env.execute_sql(create_sink)
# 4. 执行窗口函数查询
tumbling_window_table = count_by_word(input_table_name)
# 5. 将结果写入目标
tumbling_window_table.execute_insert(output_table_name).wait()
statement_set.execute()
if __name__ == "__main__":
main()
因为应用程序要使用到Kinesis Flink SQL Connector,这里需要将对应的amazon-kinesis-sql-connector-flink-2.0.3.jar下载下来。
将kda-pyflink-demo.py和amazon-kinesis-sql-connector-flink-2.0.3.jar打包成zip文件,例如kda-pyflink-demo.zip/;然后,将这个zip包上传到刚刚创建的S3存储桶中。进入刚刚创建的S3存储桶,点击“上传”。
选择刚刚打包好的zip文件,然后点击“上传”。
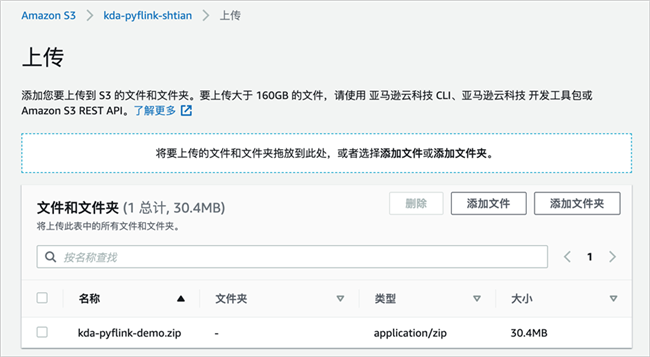
创建Python Kinesis Data Analytics 应用程序
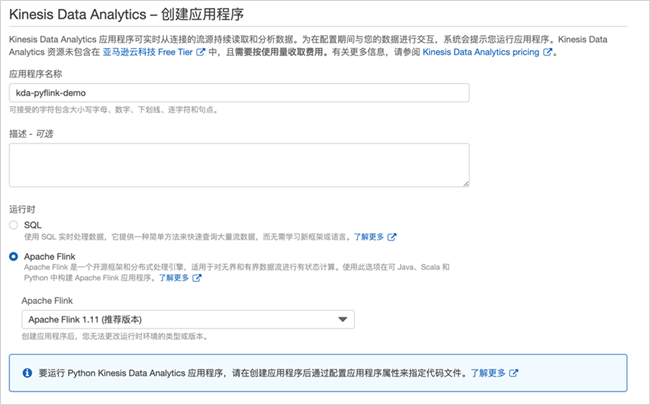
首先选择到Amazon Kinesis服务- Data Analytics,然后点击“创建应用程序”

输入应用程序名称,例如“kda-pyflink-demo”;运行时选择Apache Flink,保持默认1.11版本。
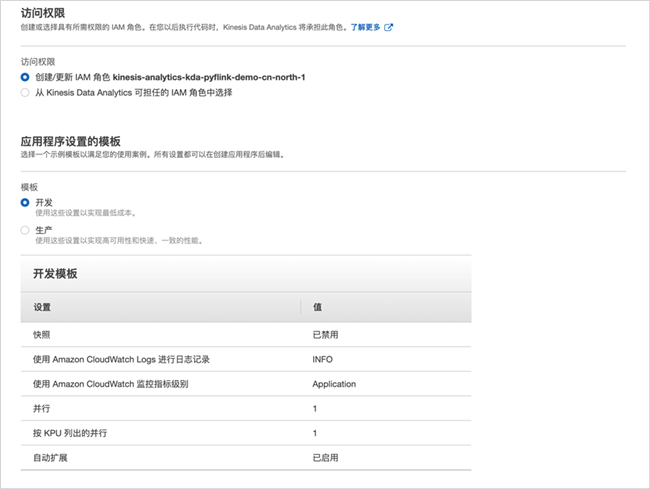
访问权限保持默认,例如“创建/更新 IAM 角色 kinesis-analytics-kda-pyflink-demo-cn-north-1”;应用程序设置的模板选择“开发”,注意这里是为了演示,可以根据实际情况选择“生产”。
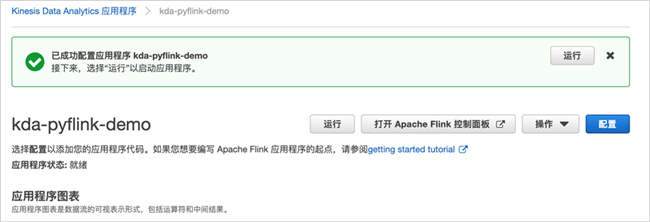
点击“创建应用程序”,稍等片刻,应用程序创建完成。
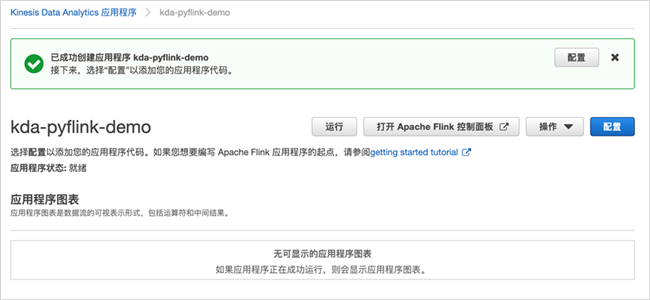
根据提示,我们继续配置应用程序,点击“配置”;代码位置配置为刚刚创建的S3中的zip包位置。
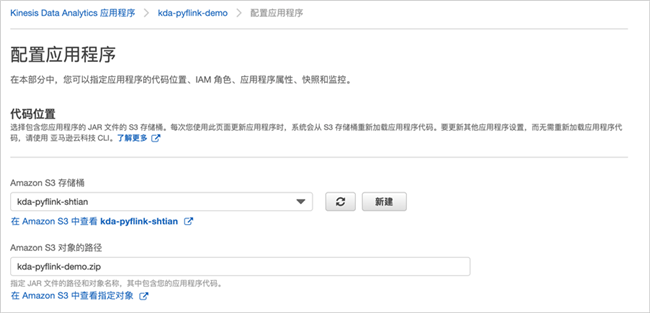
然后展开属性配置。
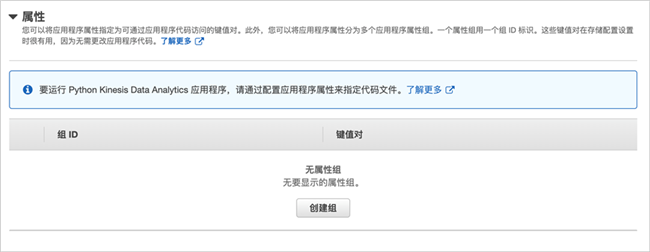
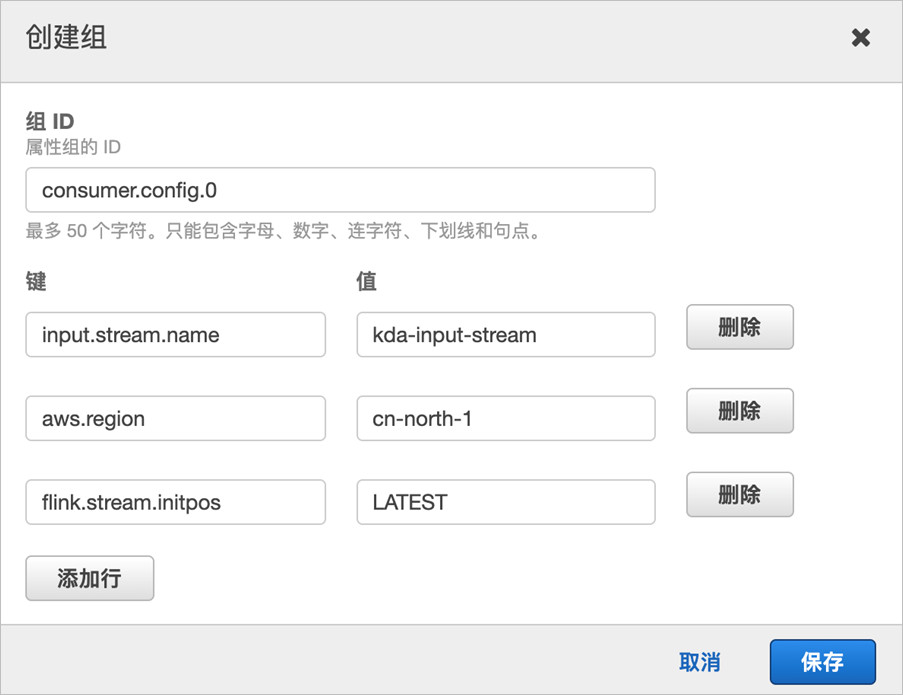
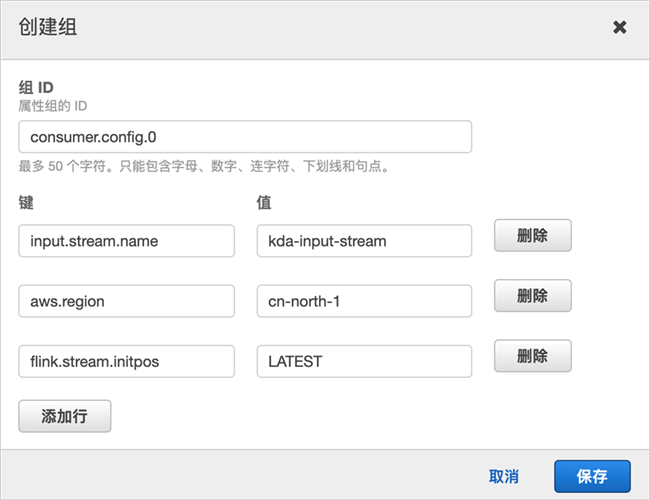
创建属性组,设置组名为“consumer.config.0”,并配置以下键值对:
input.stream.name为刚刚创建的Kinesis数据流,例如kda-input-stream
aws.region为当前区域,这里是cn-north-1
flink.stream.initpos设置读取流的位置,配置为LATEST
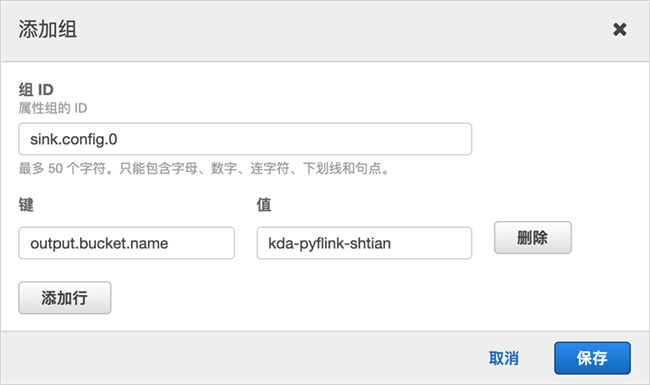
创建属性组,设置组名为“sink.config.0”,并配置以下键值对:
output.bucket.name为刚刚创建的S3存储桶,例如kda-pyflink-shtian
创建属性组,设置组名为“kinesis.analytics.flink.run.options”,并配置以下键值对:
python为刚刚创建的PyFlink程序,kda-pyflink-demo.py
jarfile为Kinesis Connector的名称,这里是amazon-kinesis-sql-connector-flink-2.0.3.jar
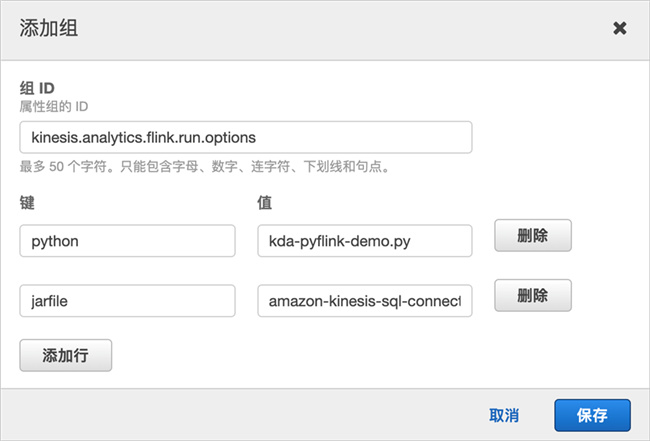
然后点击“更新”,刷新应用程序配置
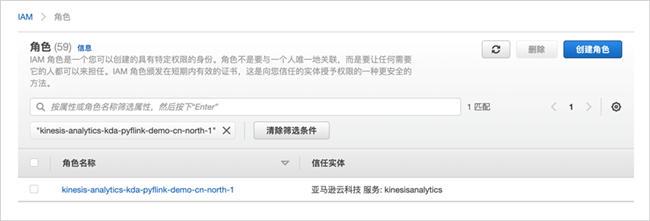
接下来,配置应用程序使用的IAM角色的权限。进入到IAM界面,选择角色,然后找到刚刚新创建的角色。
然后,展开附加策略,并点击“编辑策略”。
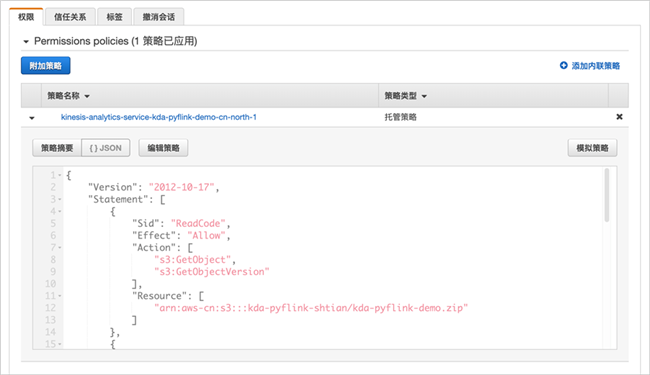
补充最后两段IAM策略,允许该角色可以访问Kinesis数据流和S3存储桶,注意需要替换为您的亚马逊云科技中国区账号。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadCode",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion"
],
"Resource": [
"arn:aws-cn:s3:::kda-pyflink-shtian/kda-pyflink-demo.zip"
]
},
{
"Sid": "ListCloudwatchLogGroups",
"Effect": "Allow",
"Action": [
"logs:DescribeLogGroups"
],
"Resource": [
"arn:aws-cn:logs:cn-north-1:012345678901:log-group:*"
]
},
{
"Sid": "ListCloudwatchLogStreams",
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams"
],
"Resource": [
"arn:aws-cn:logs:cn-north-1:012345678901:log-group:/aws/kinesis-analytics/kda-pyflink-demo:log-stream:*"
]
},
{
"Sid": "PutCloudwatchLogs",
"Effect": "Allow",
"Action": [
"logs:PutLogEvents"
],
"Resource": [
"arn:aws-cn:logs:cn-north-1:012345678901:log-group:/aws/kinesis-analytics/kda-pyflink-demo:log-stream:kinesis-analytics-log-stream"
]
},
{
"Sid": "ReadInputStream",
"Effect": "Allow",
"Action": "kinesis:*",
"Resource": "arn:aws-cn:kinesis:cn-north-1:012345678901:stream/kda-input-stream"
},
{
"Sid": "WriteObjects",
"Effect": "Allow",
"Action": [
"s3:Abort*",
"s3:DeleteObject*",
"s3:GetObject*",
"s3:GetBucket*",
"s3:List*",
"s3:ListBucket",
"s3:PutObject"
],
"Resource": [
"arn:aws-cn:s3:::kda-pyflink-shtian",
"arn:aws-cn:s3:::kda-pyflink-shtian/*"
]
}
]
}
回到Kinesis Data Analytics 应用程序界面,点击“运行”。
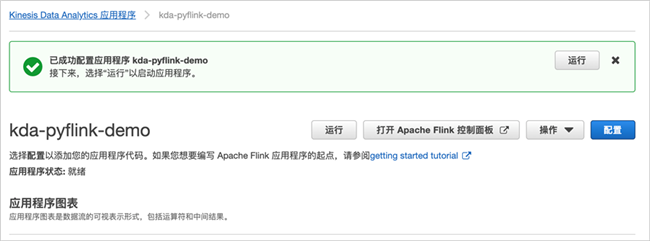
点击“打开Apache Flink控制面板”,跳转到Flink的界面。
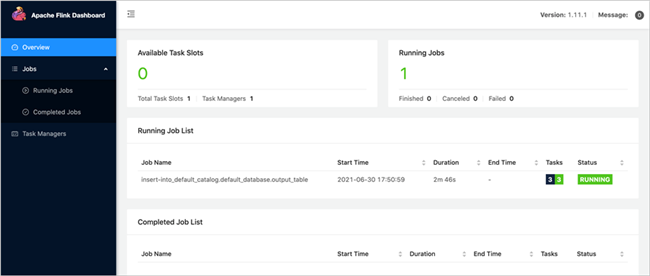
点击查看正在运行的任务。
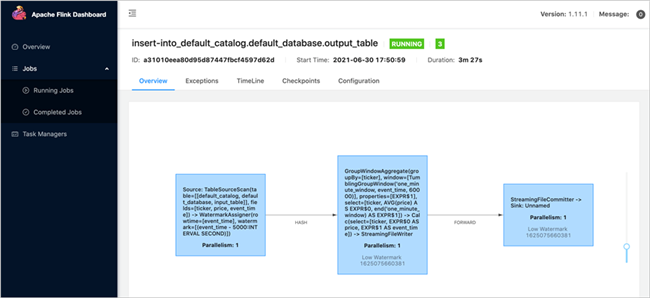
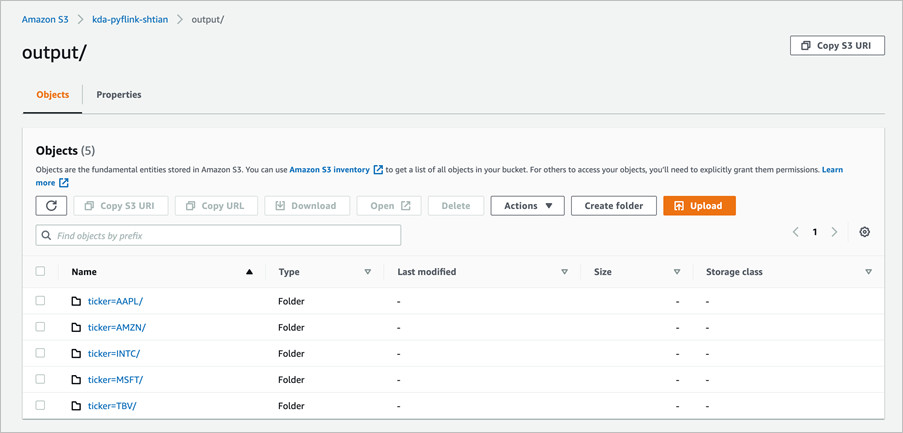
您可以根据需求进一步查看详细信息。下面,我们到S3中验证数据是否已经写入,进入到创建的存储桶,可以看到数据已经成功写入。
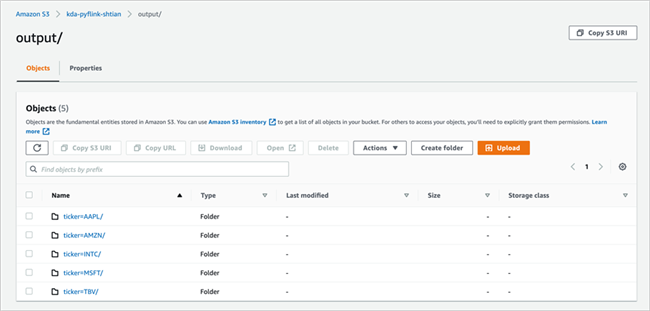
使用Amazon Glue对数据进行爬取
进入到Glue服务界面,选择爬网程序,点击“添加爬网程序“,输入爬网程序名称。
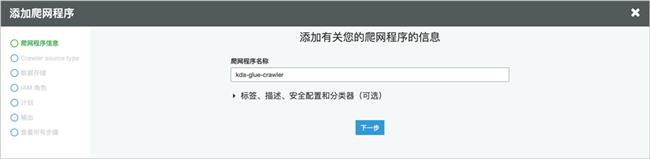
保持源类型不变,添加数据存储为创建的S3存储桶输出路径。
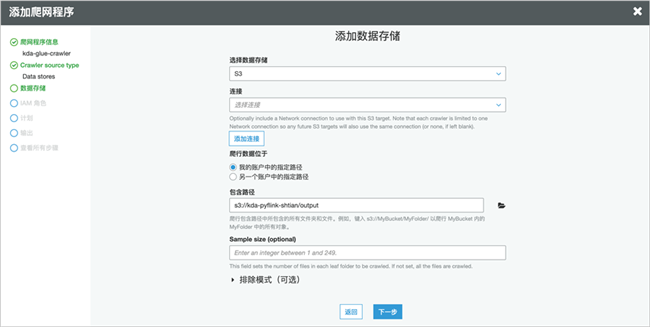
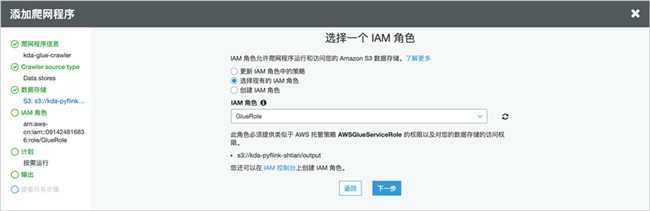
选择已有角色或者创建一个新的角色。
选择默认数据库,可以根据需求添加表前缀。
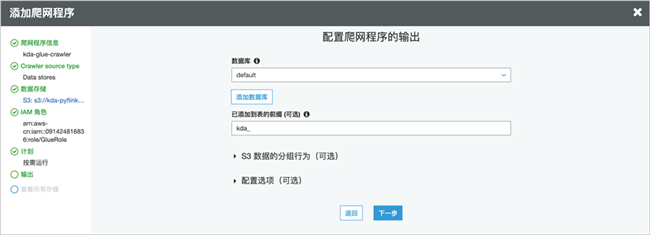
创建完成后,点击执行。
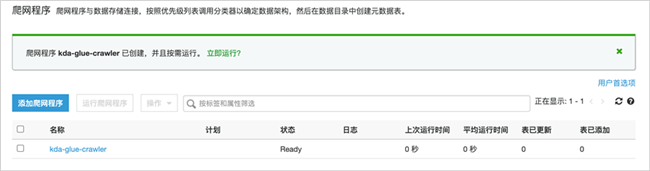
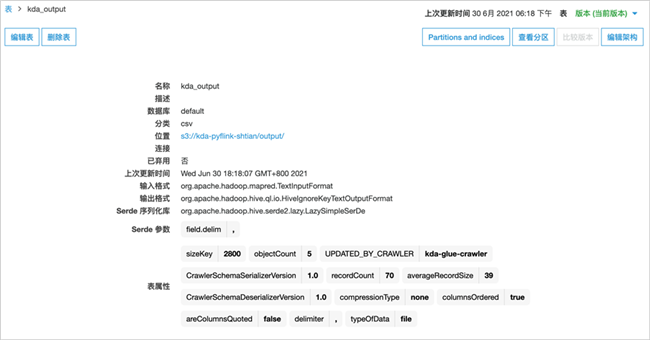
爬取成功后,可以在数据表中查看到详细信息。
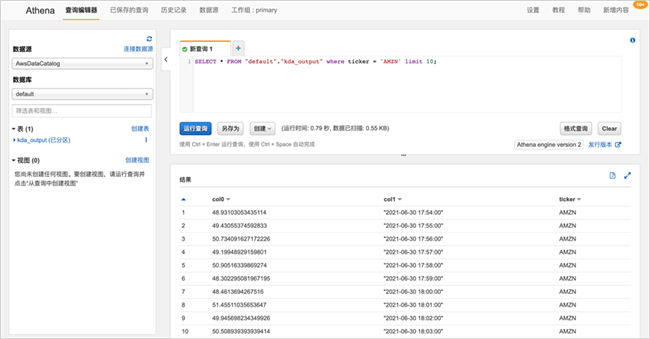
然后,可以切换到Athena服务来查询结果。
注:如果出现Glue爬网程序或者Athena查询权限错误,可能是由于开启Lake Formation导致,可以参考文档授予角色相应的权限。
小结
本文首先介绍了在亚马逊云科技平台上使用Apache Flink的快速方式 – Amazon Kinesis Data Analytics for Flink,然后通过一个无服务器架构的示例演示了如何在Amazon Kinesis Data Analytics for Flink通过PyFlink实现Python流数据处理和分析,并通过Glue和Athena对数据进行即席查询。Amazon Kinesis Data Analytics for Flink对Python的支持也已经在在光环新网运营的AWS中国(北京)区域及西云数据运营的AWS中国(宁夏)区域上线,欢迎使用。
参考资料:
https://thinkwithwp.com/solutions/implementations/aws-streaming-data-solution-for-amazon-kinesis/
https://docs.thinkwithwp.com/lake-formation/latest/dg/granting-catalog-permissions.html
https://docs.thinkwithwp.com/kinesisanalytics/latest/java/examples-python-s3.html
https://ci.apache.org/projects/flink/flink-docs-release-1.11/
本篇作者