亚马逊AWS官方博客
使用 Amazon SageMaker Debugger 与 Amazon SageMaker Experiments 为机器学习模型剪枝
过去十年以来,深度学习技术已经在众多领域取得长足进展,特别是计算机视觉与自然语言处理。如今,最先进的模型已经在图像分类等任务当中实现了与人类水平相当的性能表现。深度神经网络之所以能够实现这样的壮举,是因为它们包含数百万个由人类利用大型训练数据集训练得出的参数。以BERT(Large)模型为例,其中包含3.4亿个参数;Resnet-152则包含6000万个参数。可以想见,从零开始训练此类模型需要巨大的计算量,而且往往耗时数小时、数天甚至数周。
一般来说,数据科学家会尽可能使用迁移学习技术,即将某一个问题转化为另一个相关但又有所不同的问题,并借此使得模型获取新知识的过程。通过迁移学习,您可以在相对较小的数据集上对经过预训练的模型进行微调,进而提高其准确性。在这种情况下,模型可能不再需要规模惊人的参数储备——换言之,较小的模型也可以带来良好的学习效果。
在边缘机器学习场景下,这种为模型“瘦身”的做法至关重要。对于边缘设备来说,硬件限制(包括延迟、内存占用量以及计算时间等)的意义与模型准确性同样重要。例如,无人驾驶汽车就需要一套准确性高且延迟低的模型。在这种情况下,模型不可能为了将准确性提升1%而把预测处理时长增加1倍。
模型剪枝能够在不牺牲准确性的前提下,显著降低模型的大小。其基本思路非常简单:在模型当中找出对训练过程几乎没有帮助的冗余参数。
这篇文章将介绍如何使用Amazon SageMaker进行迭代式模型剪枝。文中将列举一个使用预训练模型的示例应用,并通过迭代剪枝将其体积削减至原本的三分之一,同时不对准确性造成明显损害。
模型剪枝
模型剪枝的根本目的,在于消除对于训练过程没有太大贡献的权重。权重是一项可学习参数,它们会在训练过程中被随机初始化及优化。在正向传播过程中,数据会贯穿整个模型。其中损失函数负责根据特定标签评估模型输出;而在反向传播期间,系统则通过更新权重以最大程度降低损失。通过这种方式,即可计算出损失与权重之间的相对梯度,并保证每项权重得到不同程度的更新。经过几次迭代之后,某些权重会表现出比其他权重更强的影响力。剪枝的目标正是在不对模型准确性造成显著影响的前提下,删除其中的无用项。具体工作流程如下图所示。

您可以使用以下几种试探方法衡量不同权重的重要性:
- 权重幅值 – 如果权重的绝对值小于阈值,则将其删除;较小的权重对输出的影响也相对较小。
- 平均激活 – 如果在整个训练过程中,大部分神经元都不活跃,则可推断出进入激活函数的权重不太重要。
剪枝可以分为非结构化与结构化权重剪枝:
- 非结构化剪枝用于删除任意权重(如上图所示)。
- 结构化剪枝可删除整个卷积过滤器及其相关通道。
结构化剪枝往往用于由大量卷积层组成的计算机视觉模型当中。过滤器是一个卷积核的集合(每个输入通道对应一个卷积核)。过滤器会输出一个特征图(feature map),也称为输出通道。如下图所示为输出三个特征图的三个卷积核。模型需要学习的参数数量(权重)为3 x 输入通道 x 内核宽度 x 内核高度,在本示例中输入通道数为1。为了简单起见,大家可以设定此图中不存在偏差张量。您可以对过滤器进行排名,以找到最不重要的过滤器(例如图中的黄色过滤器)。只要将它删除,您的参数数量就将减少至1 x 输入通道 x 内核宽度 x 内核高度。

为了对各个过滤器进行重要性排名,大家可以参考《通过卷积神经网络剪枝实现资源有效推理(“Pruning Convolutional Neural Networks for Resource Efficient Inference”)》论文中提出的排名方法:估计剪枝后过滤器对于损失函数的影响。其核心目标是消除那些不会影响损失函数的因素。如果过滤器的激活输出以及相应的梯度较小,则排名将相对较低。通过在整个训练中累积激活输出和梯度的乘积,可以估算过滤器的重要性。
在此之后,您可以删除排名最低的过滤器,对模型进行微调,以便从剪枝中恢复并重新获得准确性。整个过程可以重复多次以获取最佳效果。
在Amazon SageMaker上进行迭代模型剪枝
在Amazon SageMaker Debugger 中,我们可以通过训练任务发出张量,同时使用内置规则自动检测训练过程中出现的问题。另外,大家也可以检索梯度与激活输出,并据此计算过滤器排名。关于更多详细信息,请参阅《Amazon SageMaker Debugger——调试您的机器学习模型》。Amazon SageMaker Experiments则允许您以规模化方式定义、可视化并跟踪机器学习实验。关于更多详细信息,请参阅《Amazon SageMaker Experiments——组织、跟踪并比较您的机器学习训练》。在本文中,我们将使用SageMaker Experiments跟踪不同的迭代剪枝。您也可以使用Amazon SageMaker Studio中的“Experiments”视图快速识别并部署在准确性与大小之间取得最佳平衡点的模型。
为了逐步进行迭代模型剪枝,本文选择使用在ImageNet上预训练完毕的Resnet18模型,并利用仅包含101个类的Caltech101数据集对模型进行微调。您也可以在重新训练期间反复调整图像数据集的大小。ResNet是由多个残差组成的卷积神经网络。其中每个残差块,具体包括卷积层、批处理归一化层以及ReLu函数。跳过连接,则意味着允许输入绕开当前块。在本文中,我们将使用ResNet18,即包含约1100万个参数的最精简ResNet模型版本。在每一轮剪枝迭代中,我们将删除排名最低的200个过滤器。
如下图所示,为这套解决方案的实际工作流程:
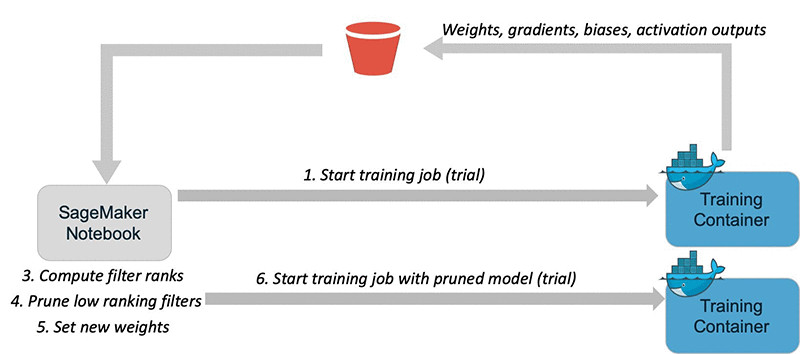
其具体操作步骤包括:
- 启动训练作业。
- 获取权重、梯度、偏差与激活输出。
- 计算过滤器排名。
- 对排名最低的过滤器进行剪枝。
- 设置新的权重。
- 使用经过剪枝的模型启动新一轮训练任务。
创建experiment与debugger hook配置
在实施这套解决方案之前,我们首先需要创建一个模型剪枝experiment。这里的experiment代表一组试验的集合,而每项trial又是多个训练步骤的集合。具体请参见以下代码:
在每一轮剪枝迭代中,我们都会启动新的Amazon SageMaker训练任务,该任务是experiment中新的trail。具体参见以下代码:
接下来,需要定义experiment_config,即传递给Amazon SageMaker训练任务的字典。以此为基础,Amazon SageMaker会将训练作业与experiement及trail关联起来。具体请参见以下代码:
在开始训练之前,需要先定义debugger hook配置。Amazon SageMaker Debugger为权重、偏差、梯度以及损失提供多套默认集合。在本文中,我们还需要保存激活输出。要执行检索,应创建一个自定义集合,其中的正则表达式负责指示需要包含的张量名称。由于ResNet由批处理归一化层组成,所以我们也可以存储运行均值和方差的批量归一化统计信息。张量每100步保存一次,其中每一步代表一次前进与后退传递。具体请参见以下代码:
启动训练作业
现在,我们已经做好利用Amazon SageMaker训练ResNet18模型的全部准备工作了。训练循环将在entry_point 文件的train.py中进行定义。要了解更多详细信息,请参考GitHub repo。要发出张量,请将debugger hook配置传递至PyTorch Estimator当中,具体参见以下代码:
在定义估计器对象之后,即可调用fit。这步操作将启动ml.p3.2xlarge托管实例以运行您的训练脚本。如前文所述,您需要将experiment_config传递至训练作业,详见以下代码:
获取梯度、权重与偏差
在训练任务完成之后,您可以获取其张量,例如梯度、权重与偏差。在这里,大家可以使用smdebug库,通过相关函数读取并过滤各张量。首先,创建一个 trial 以访问debugger所保存的张量。关于更多详细信息,请参见GitHub repo。在Amazon SageMaker Debugger使用场景下,trail代表的是一个对象,用户可以借此查询特定训练任务中的张量。在Amazon SageMaker Experiment使用场景下,trial属于experiment的一部分,负责表示与单一训练任务相关的训练步骤集合。详见以下代码示例:
要访问张量值,请调用smdebug_trial.tensor()。例如,要想获取第一个卷积层的激活输出,请使用以下代码:
计算过滤器排名
现在您可以访问张量,并计算它们的过滤器排名了。首先迭代当前训练步骤,而后检索激活输出及其梯度。例如,以下代码片段会计算模型中第一个特征层的过滤器排名,而后为每个过滤器计算出对应的排名值:
接下来,我们可以归一化过滤器排名并按大小对结果进行排序。
对低排名过滤器进行剪枝
现在,您可以检索排名最低的过滤器。以下代码显示,您可以对layer1.0中的1、36与127号过滤器进行剪枝,因为它们的排名值为0.0:
要对过滤器执行剪枝,请使用SageMaker Debugger获取layer1.0中第一个卷积层的权重张量,并删除第二个维度(axis=1)中的上述条目。具体参见以下代码:
设置新的权重
您还需要调整卷积参数。Resnet18模型内layer1.0当中的卷积层拥有64个输出通道。在移除以上三个过滤器后,它只余下61个输出通道。您还需要调整后续批量归一化层的权重。为此,我们删除第一维(axis=0)中的条目,具体参见以下代码:
启动下一轮剪枝迭代
在对200个最小过滤器进行剪枝之后,使用最新权重保存新的模型定义,而后开始下轮剪枝迭代。您可以重复完成这些步骤,每一轮迭代都将削减模型的实际大小。
结果
您可以在Amazon SageMaker Studio当中跟踪并可视化各迭代模型剪枝experiment。训练脚本会利用SageMaker Debugger中的save_scalar方法保存模型参数数量及模型准确性。关于更多详细信息,请参见GitHub repo。其中save_scalar的值会被写入至数据存储内,供Amazon SageMaker Studio用于创建可视化结果。在以下散点图中,x轴代表模型参数的数量,而y轴则代表模型的验证准确性。
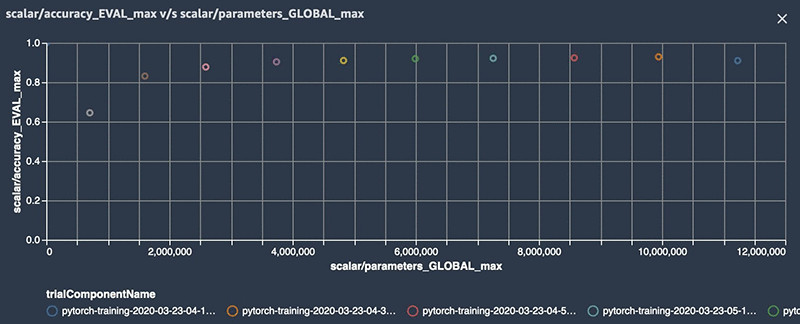
最初,这套模型中包含1100万个参数。在经过11轮迭代之后,参数数量减少至706000,准确性提高到90%,但准确性从第8次剪枝迭代后开始下降。以下截图所示为experiment视图,其中列出了每一轮trail的详细信息。

使用自定义规则运行迭代模型剪枝
在之前的示例中,当模型的参数少于400万时,准确性开始降低。在达到这一阈值后,我们希望停止experiment。SageMaker Debugger中提供内置规则,可以在模型训练发生问题(例如梯度消失或者损失不再降低)时被触发。如果模型的容量不足(参数太少),则说明学习效果不好。其代表的可能性之一就是损失无法进一步降低。关于更多详细信息,请参阅《Amazon SageMaker Deubgger中的内置规则(Built-in Rules Provided by Amazon SageMaker Debugger)》。
在本文中,我们可以定义一项自定义规则,利用它将当前模型的准确性与前一训练任务的模型准确性进行比较。例如,如果准确性下降超过10%,则触发规则并返回True。接下来,您可以设置Amazon CloudWatch警报及AWS Lambda函数以停止训练作业,并防止将基础设施资源浪费在对低质量模型的剪枝实验当中。关于更多详细信息,请参见GitHub repo。
以下代码所示,为一条自定义规则的高级概述:
这条规则用于实现一个继承自smdebug规则类的Python类。它以前一训练任务的模型准确性为参数,在完成每一步新操作并产生新张量时调用invoke_at_step函数。利用smdebug,您可以将损失以模型预测与标签的形式输入到损失函数当中。接下来,您就可以计算当前模型准确性并将其与训练前的水平进行比较。关于规则机制的完整实现方法与细节信息,请参见GitHub repo。
要在训练作业中运行该规则,大家需要将其传递至PyTorch估计器对象。在此之前,我们还要先创建一个自定义规则配置,详见以下代码示例:
这条规则配置负责指定规则定义的位置、对应的输入参数以及规则容器将要运行的实例类型。您还需要为规则容器指定镜像。关于更多详细信息,请参阅《Amazon SageMaker自定义规则估计器注册表ID(Amazon SageMaker Custom Rule Evaluator Registry Ids)》。
在规则定义完成后,将参数rules = [check_accuracy_rule]传递至该Pytorch估计器。
在每一轮剪枝迭代中,我们都需要将上一轮训练作业中的准确性传递至规则当中,并通过SageMaker Experiments与ExperimentAnalytics模块进行检索。详见以下代码示例:
使用以下代码覆盖规则配置中的值:
在每一轮迭代中,检查作业状态。如果上一代作业停止,则退出循环。详见以下代码:
下图所示,为参数数量与模型准确性之间的关系。与之前的实验不同,训练作业会在生成低质量模型时自动停止,而后experiment结束。结果就是,模型剪枝只运行了8轮迭代。

以下截图所示,为SageMaker Studio中的“Debugger”视图,可以看到自定义规则发现了一个问题。

关于使用SageMaker Debugger定义并运行自定义规则的更多详细信息,请参阅《如何使用自定义规则(How to Use Custom Rules)》。
总结
本文探讨了使用Amazon SageMaker进行迭代模型剪枝的方法,同时介绍了如何通过识别对训练过程鲜有帮助的冗余参数来显著降低模型大小并保持模型准确性。我们还在本文中引入了使用预训练模型的应用示例,可以看到该模型通过迭代剪枝成功实现了准确性保障前提下的“瘦身”任务。