亚马逊AWS官方博客
预览版 – 使用 Amazon Bedrock 代理将基础模型连接到公司的数据源
我们在 7 月宣布推出 Amazon Bedrock 代理的预览版,这是让开发人员能够创建生成式 AI 应用程序以完成任务的新功能。今天,我很高兴地介绍使用代理将基础模型(FM)安全地连接至公司数据源的新功能。
借助知识库,可以使用代理让 Bedrock 中的 FM 访问其他数据,这些数据可以帮助模型生成更相关、更符合上下文且更准确的响应,而无需持续重新训练 FM。根据用户输入,代理可以识别相应的知识库,检索相关信息,并将信息添加到输入提示中,从而为模型提供更多上下文信息以生成完成内容。
Amazon Bedrock 代理使用称为检索增强生成(RAG)的概念来实现这一目标。要创建知识库,请指定数据的 Amazon Simple Storage Service(Amazon S3)位置,选择嵌入模型,并提供向量数据库的详细信息。Bedrock 将数据转换为嵌入并将嵌入内容存储在向量数据库中。然后,可以向代理添加知识库以启用 RAG 工作流程。
对于向量数据库,可以在 Amazon OpenSearch 无服务器的向量引擎、Pinecone 和 Redis Enterprise Cloud 之间进行选择。我将在本文的后面部分分享有关如何设置向量数据库的更多详细信息。
检索增强生成、嵌入和向量数据库入门
RAG 不是一套特定的技术,而是为 FM 提供其在训练期间未看到数据的访问权限的概念。使用 RAG,可以借助其他信息(包括公司特定的数据)来增强 FM,而无需持续重新训练模型。
持续重新训练模型不仅需要大量计算,而且成本高昂,并且一旦对模型进行重新训练,公司可能在此期间已经生成新数据,而您的模型中会包含陈旧的信息。RAG 通过让您的模型在运行时有权访问其他外部数据来解决此问题。然后,将相关数据添加到提示中,以帮助提高完成内容的相关性和准确性。
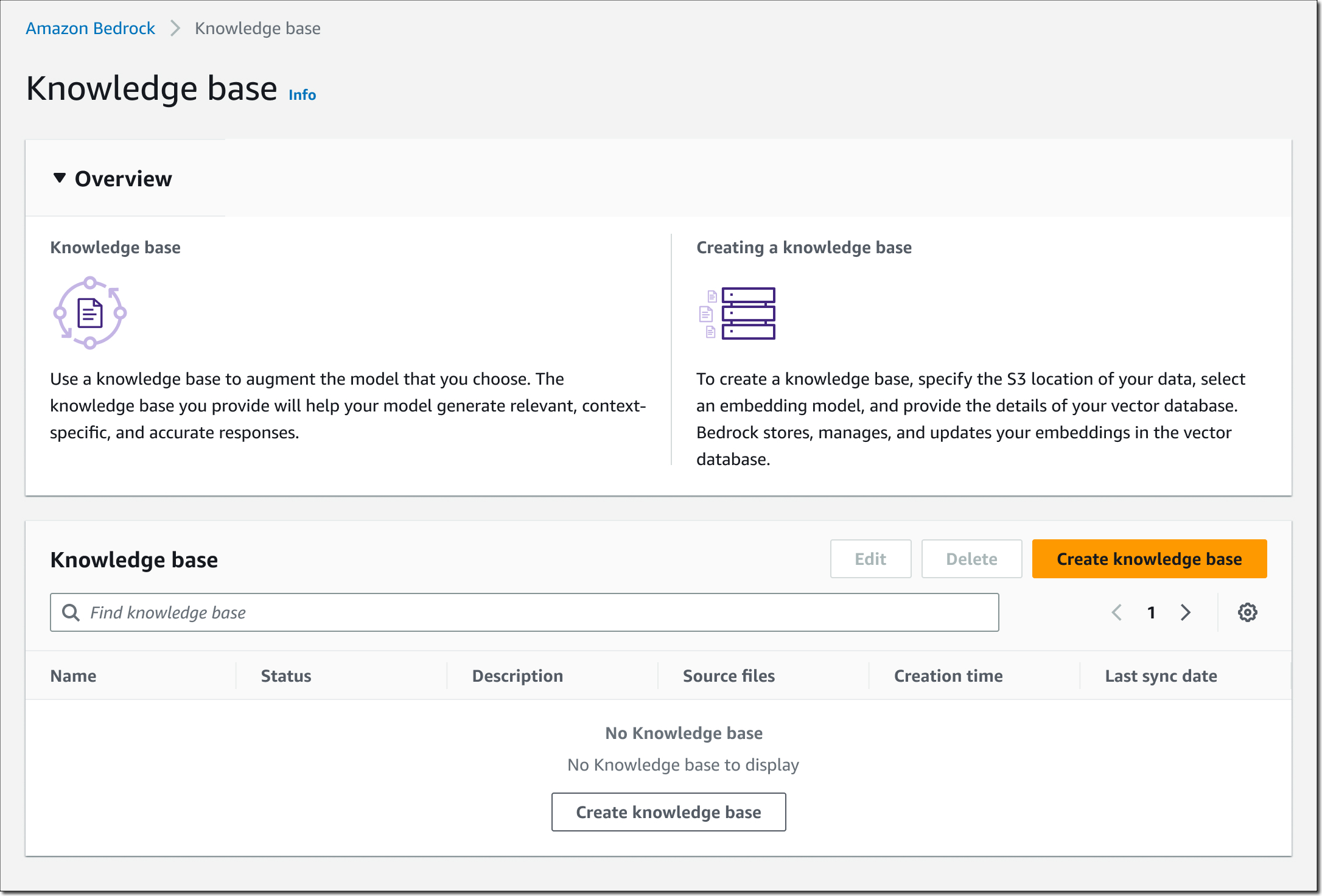
这些数据可以来自多个数据来源,例如文档存储或数据库。文档搜索的常见实现方法是使用嵌入模型将文档或文档块转换为向量嵌入,然后将向量嵌入存储在向量数据库中,如下图所示。
向量嵌入包括文档中文本数据的数字表示形式。每个嵌入都旨在捕获数据的语义或上下文含义。每个向量嵌入都放入向量数据库中,通常还带有其他元数据,例如对从中创建嵌入的原始内容的引用。然后,向量数据库对向量编制索引,可以使用多种方法完成此操作。这种索引可以快速检索相关数据。
与传统的关键字搜索相比,向量搜索无需精确匹配关键字即可找到相关结果。例如,如果您搜索“产品 X 的成本是多少?”,并且文档中写明“产品 X 的价格是 […]”,那么关键字搜索可能不起作用,因为“价格”和“成本” 是两个不同的单词。使用向量搜索时,它将返回准确的结果,因为“价格”和“成本”在语义上是相似的;它们的含义相同。向量相似度以距离指标计算,例如欧几里得距离、余弦相似度或点积相似度。
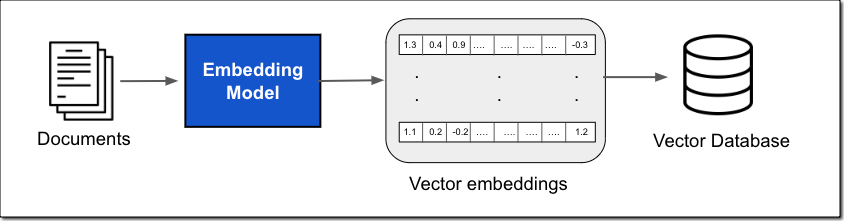
然后,在提示工作流程中使用向量数据库,根据输入查询有效地检索外部信息,如下图所示。

工作流程首先是用户输入提示。使用相同的嵌入模型,可以创建输入提示的向量嵌入表示。然后,使用此嵌入在数据库中查询相似的向量嵌入,以返回最相关的文本作为查询结果。
接下来,将查询结果添加到提示中,并将增强的提示传递给 FM。模型使用提示中的附加上下文来生成完成内容,如下图所示。
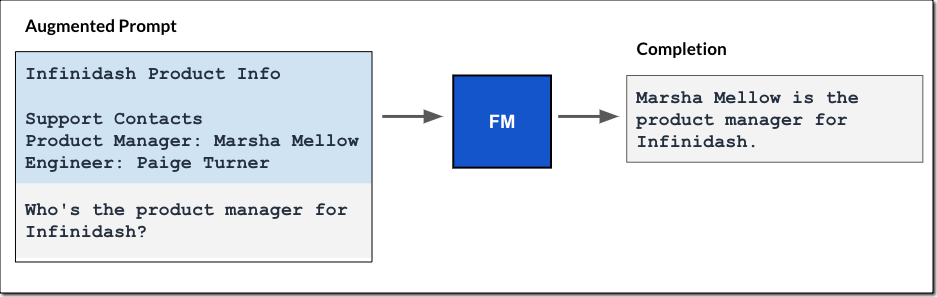
类似于我在关于 Amazon Bedrock 代理的博客文章中描述的完全托管代理体验,Amazon Bedrock 知识库管理数据摄取工作流程,并且代理自动管理 RAG 工作流程。
开始使用 Amazon Bedrock 知识库
您可以通过指定数据来源(例如 Amazon S3)、选择嵌入模型(例如 Amazon Titan Embeddings)来将数据转换为向量嵌入以及用于存储向量数据的目标向量数据库,以此添加知识库。Bedrock 负责在向量数据库中创建、存储、管理和更新嵌入。
如果您向代理添加知识库,代理将根据用户输入识别相应的知识库,检索相关信息,然后将信息添加到输入提示中,从而为模型提供更多上下文信息以生成响应,如下图所示。从知识库检索的所有信息都带有来源归因,以提高透明度并最大限度地减少幻觉。

接下来更详细地介绍这些步骤。
为 Amazon Bedrock 创建知识库
假设您是一家税务咨询公司的开发人员,想要为用户提供一款生成式人工智能应用程序:Taxbot,该应用程序可以回答美国的纳税申报问题。 您首先要创建包含相关税务文档的知识库。然后,可以在 Bedrock 中配置可访问此知识库的代理,并将该代理集成到 TaxBot 应用程序中。
要开始使用,请打开 Bedrock 控制台,在左侧导航窗格中选择知识库,然后选择创建知识库。
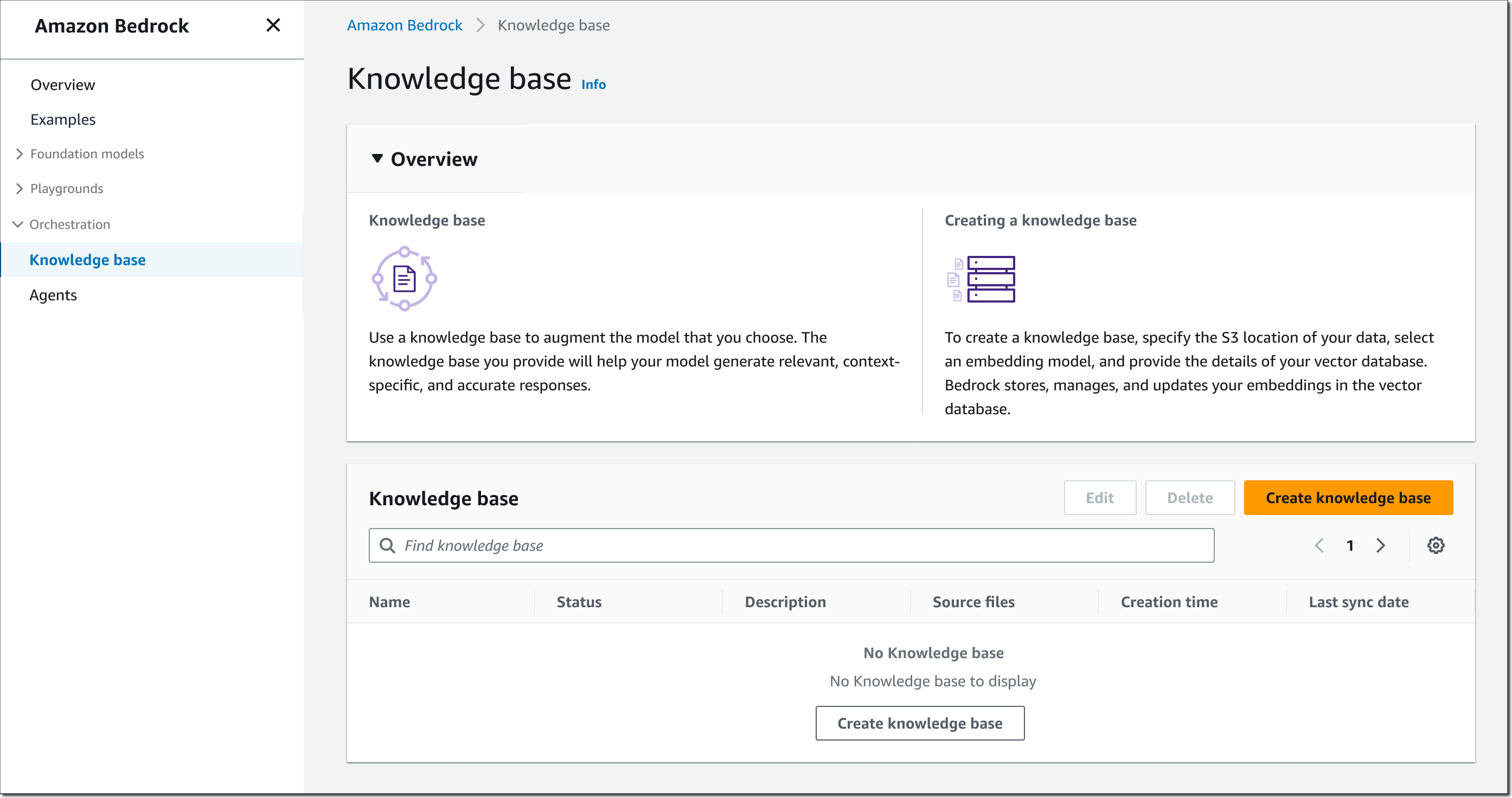
步骤 1 – 提供知识库详细信息。 输入知识库的名称和描述(可选)。您还必须选择 AWS Identity and Access Management(IAM)运行时角色,该角色具有适用于 Amazon Bedrock 的信任策略、访问您希望知识库使用的 S3 存储桶的权限,以及对向量数据库的读/写权限。您也可以根据需要分配标签。

步骤 2 – 设置数据来源。 输入数据来源名称并为数据指定 Amazon S3 的位置。支持的数据格式包括 .txt、.md、.html、.doc 和 .docx、.csv、.xls 和 .xlsx 以及 .pdf 文件。还可以提供 AWS Key Management Service(AWS KMS)密钥以允许 Bedrock 解密和加密您的数据,并在 Bedrock 将数据转换为嵌入时提供另一个 AWS KMS 密钥,用于临时数据存储。
选择嵌入模型,例如 Amazon Titan Embeddings – Text,然后选择向量数据库。对于向量数据库,如前所述,可以在 Amazon OpenSearch 无服务器的向量引擎、Pinecone 或 Redis Enterprise Cloud 之间进行选择。

关于向量数据库的重要说明:Amazon Bedrock 不会代表您创建向量数据库。您必须从支持的选项列表中创建新的空向量数据库,并且提供向量数据库索引名称以及索引字段和元数据字段映射。该向量数据库需要专供 Amazon Bedrock 使用。
接下来了解 Amazon OpenSearch 无服务器的向量引擎的设置。假设您已按照开发人员指南和这篇 AWS 大数据博客文章中所述设置 OpenSearch 无服务器集合,请提供 OpenSearch 无服务器集合的 ARN,指定向量索引名称以及向量字段和元数据字段映射。
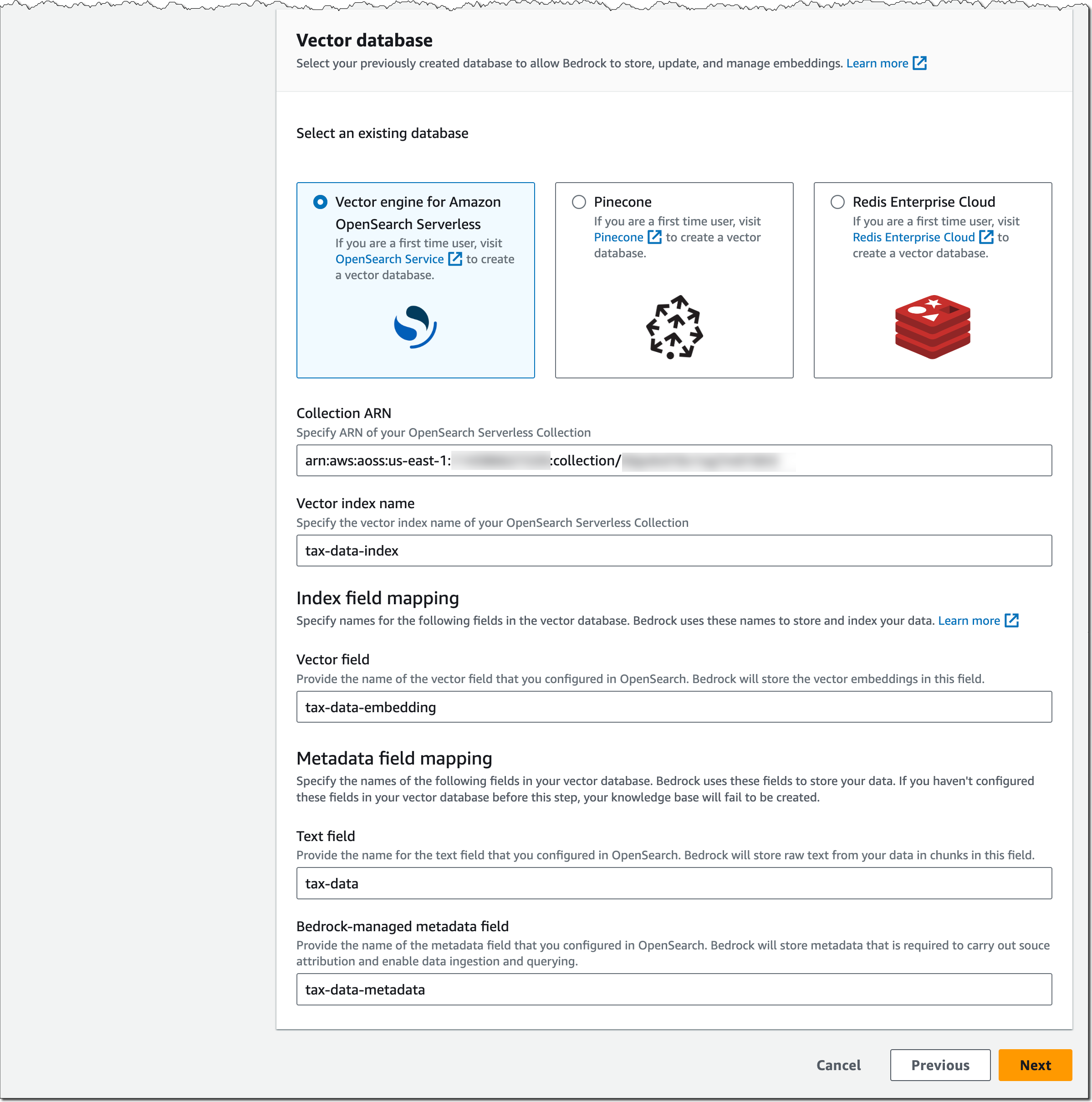
Pinecone 和 Redis Enterprise Cloud 的配置与此类似。查阅此 Pinecone 博客文章和此 Redis Inc. 博客文章,了解有关如何为 Bedrock 设置和准备向量数据库的更多详细信息。
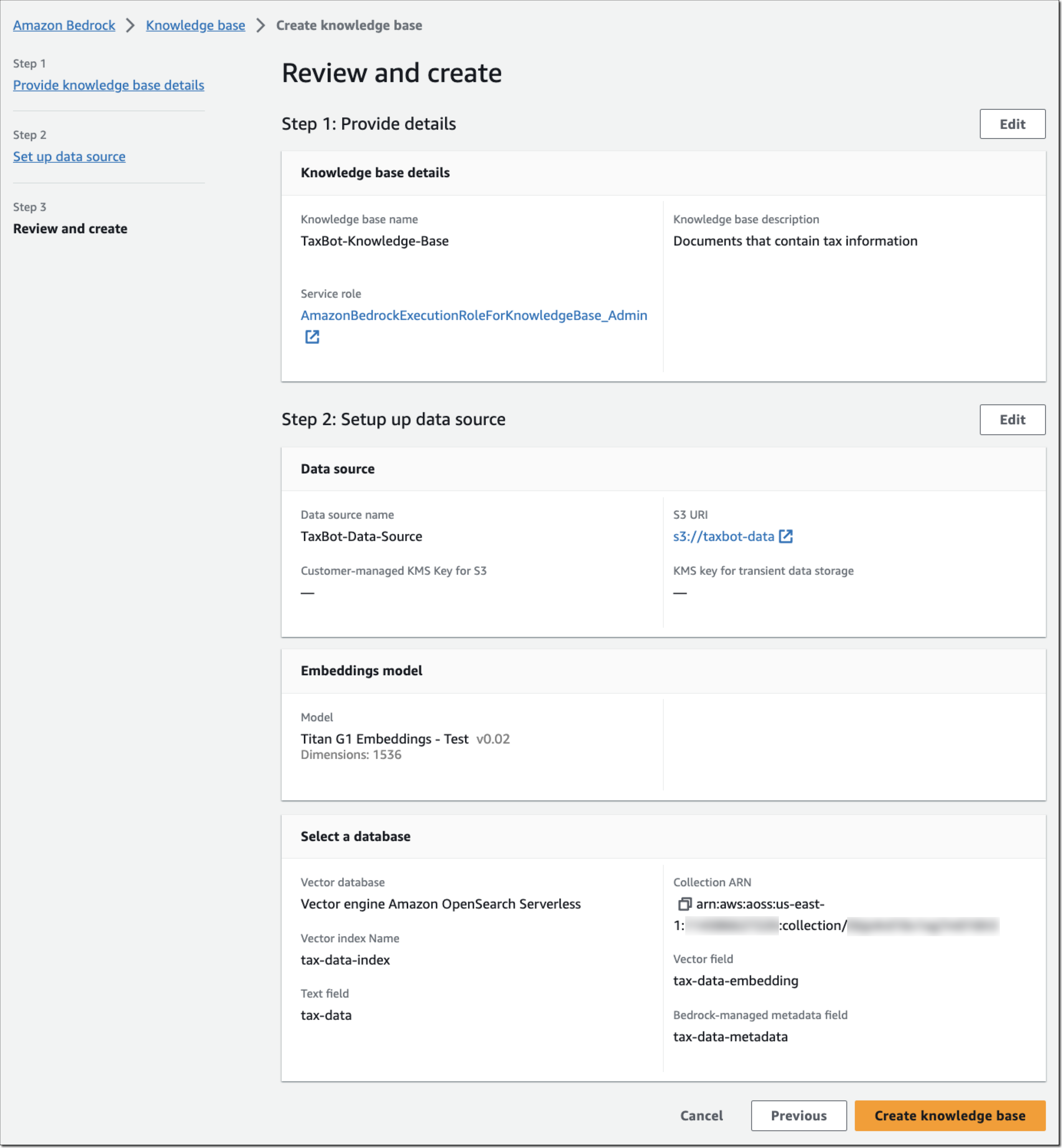
步骤 3 – 查看并创建。 查看您的知识库配置,然后选择创建知识库。
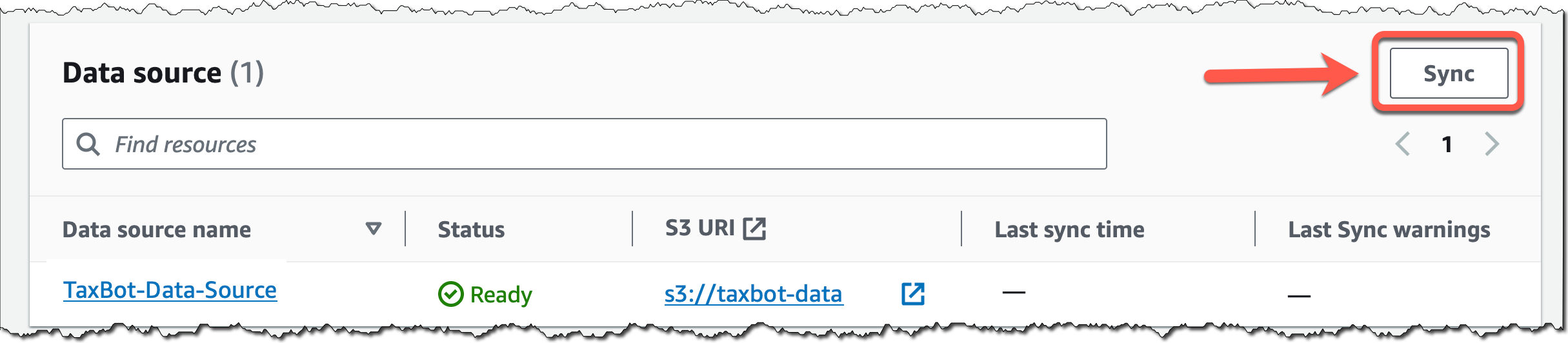
返回知识库详细信息页面,为新创建的数据来源选择同步,无论何时向数据来源添加新数据,都将启动摄取工作流程,将您的 Amazon S3 数据转换为向量嵌入并将嵌入内容更新插入到向量数据库中。根据处理的数据量,整个工作流程可能需要一些时间。
接下来,我将向您展示如何将知识库添加到代理配置中。
为 Amazon Bedrock 代理添加知识库
在为 Amazon Bedrock 创建或更新代理时,您可以添加知识库。按照此关于 Amazon Bedrock 代理的 AWS 新闻博客文章中所述创建代理。
在我的税务机器人示例中,我创建名为“TaxBot”的代理,选择一个根基模型,并在步骤 2 中为该代理提供以下说明:“您是乐于助人且友好的代理,可以为用户回答美国的纳税申报问题。” 在步骤 4 中,您现在可以选择先前创建的知识库,并向代理提供描述何时使用此知识库的说明。

这些说明非常重要,因为它们可以帮助代理决定是否应使用特定的知识库进行检索。代理将根据用户输入和可用的知识库说明确定相应的知识库。
在我的税务机器人示例中,我添加了“Taxbot-Knowledge-Base”知识库以及以下说明:“使用此知识库回答纳税申报问题。”
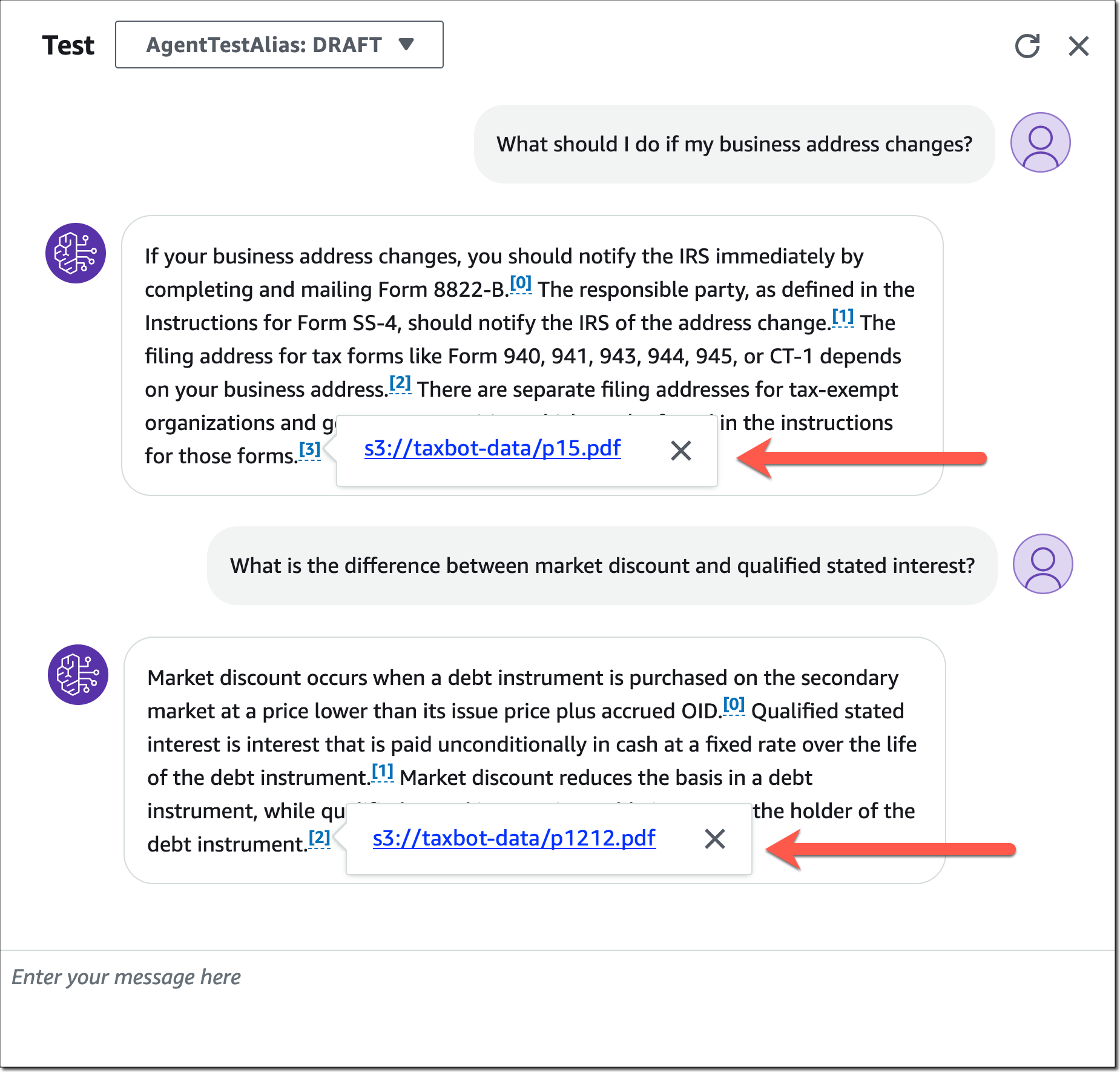
完成代理配置后,可以使用添加的知识库来测试代理及其运行情况。请注意代理如何为从知识库中提取的信息提供来源归因。
 学习生成式人工智能的基础知识
学习生成式人工智能的基础知识
采用大型语言模型(LLM)的生成式人工智能是一门为期三周的按需课程,面向想要学习如何通过 LLM(包括 RAG)构建生成式人工智能应用程序的数据科学家和工程师。这是开始使用 Amazon Bedrock 进行构建的完美基础。立即注册学习采用 LLM 的生成式人工智能。
注册以了解有关 Amazon Bedrock(预览版)的更多信息
Amazon Bedrock 目前提供预览版。如果您想访问预览版中的 Amazon Bedrock 知识库,请通过通常的 AWS 支持联系方式联系我们。我们定期为新客户提供访问权限。若要了解更多信息,请访问 Amazon Bedrock 功能页面并注册以了解有关 Amazon Bedrock 的更多信息。
— Antje
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。