亚马逊AWS官方博客
新增 – 借助标准检索层和 S3 批量操作,将 Amazon S3 Glacier 灵活恢复时间缩短 85%
去年,Amazon S3 Glacier 庆祝其成立十周年。Amazon S3 Glacier 是云端冷存储领域的领导者,我写了它过去十年的创新。
Amazon S3 Glacier 存储类为您提供长期、安全且持久的存储选项,让您以更低的成本出色归档数据。Amazon S3 Glacier 存储类(Amazon S3 Glacier Instant Retrieval、Amazon S3 Glacier Flexible Retrieval 和 Amazon S3 Glacier Deep Archive)专为较冷的数据打造,为您提供从几毫秒到几天的检索灵活性,并且让您能以每 TB 每月 4 美元的低成本存储存档数据。
许多客户告诉我们,他们之所以将数据保留更长的时间,是因为他们认识到数据的未来价值潜力,而且他们已经在利用存档数据的子集获利,或者计划将来使用大量存档数据。现代数据归档不仅要优化冷数据的存储成本;还要设置机制,以便在需要将这些数据用于业务时,您可以根据业务需求快速访问这些数据。
2022 年,AWS 客户从 Amazon S3 Glacier 恢复了超过 320 亿个对象。在对媒体进行转码、恢复操作备份、训练机器学习(ML)模型或分析历史数据时,客户需要快速检索存档对象。虽然使用 S3 Glacier Instant Retrieval 的客户可以在几毫秒内访问数据,但 S3 Glacier Flexible Retrieval 的成本更低,并提供三种检索选项:1-5 分钟内快速检索、3-5 小时内标准检索、5-12 小时内免费批量检索。S3 Glacier Deep Archive 是我们成本较低的存储类,标准检索选项可在 12 小时内检索数据,批量检索选项可在 48 小时内检索数据。
2022 年 11 月,在 S3 Glacier Flexible Retrieval 和 S3 Glacier Deep Archive 中检索大量存档数据时,Amazon S3 Glacier 将恢复吞吐量提高了 10 倍,而且无需额外费用。借助 Amazon S3 批量操作,您能以更快的速度自动启动请求,从而恢复包含数 PB 数据的数十亿个对象。
为延续长达 10 年的冷存储创新趋势,我们今天宣布,S3 Glacier Flexible Retrieval 中标准检索的速度普遍提高 85%,而且无需额外费用。使用 S3 批量操作时,标准检索层的数据恢复速度会自动加快。
借助 S3 批量操作,您可以提供要检索的对象的清单并指定检索层,从而大规模恢复存档数据。借助 S3 批量操作,标准检索层中的恢复操作现在通常会在几分钟内开始向您返回对象,不再需要 3-5 小时,因此您可以轻松地加快从存档中恢复数据的速度。
此外,S3 批量操作还会对作业应用新的性能优化,从而提高总体恢复吞吐量。因此,您能以更快的速度恢复数据并处理已恢复的对象。并行处理恢复的数据与正在进行的恢复,这样有助于您加快数据工作流并快速响应业务需求。
开始从 S3 Glacier Flexible Retrieval 更快地进行标准检索
要通过这种性能改进来恢复存档数据,您可以使用 S3 批量操作对 S3 对象执行大规模和小规模批量操作。S3 批处理操作可以对您指定的 S3 对象列表执行单一操作。您可以通过 AWS 管理控制台、AWS 命令行界面(AWS CLI)、SDK 或 REST API 使用 S3 批量操作。
要创建批量作业,请在 Amazon S3 控制台的左侧导航窗格中选择批量操作,然后选择创建作业。您可以选择一种清单格式,即包含要检索的对象密钥的 S3 对象列表。如果您的清单格式为 CSV 文件,则文件中的每一行都必须包含桶名称、对象密钥以及(可选)对象版本。

在下一步中,选择要对清单中列出的所有对象执行的操作。恢复操作会针对您指定的 S3 对象列表中的存档对象启动恢复请求。使用恢复操作,系统会对清单中指定的每个对象发出恢复请求。
当您使用 S3 Glacier Flexible Retrieval 存储类中的标准检索层进行恢复时,检索速度会自动加快。
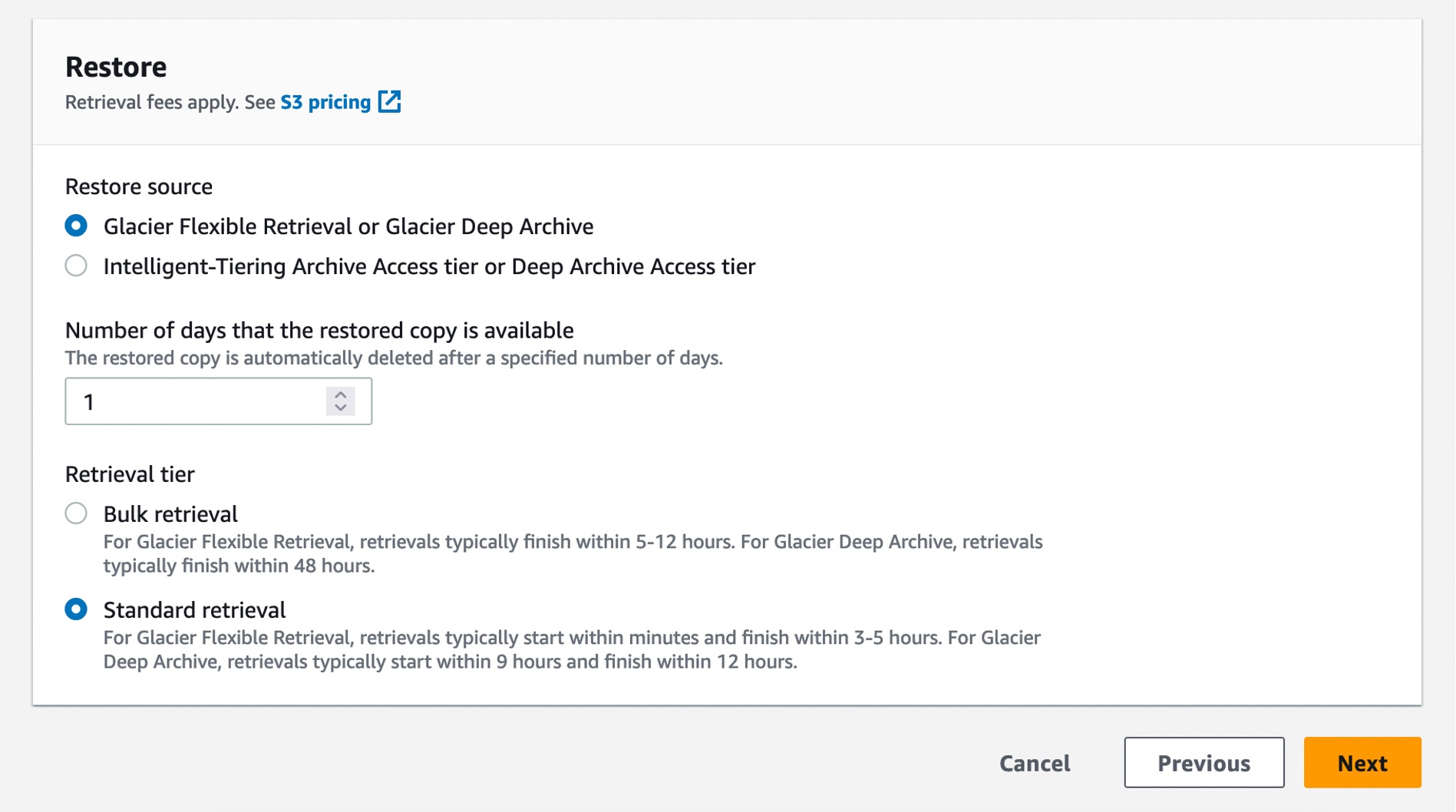
您还可以使用 AWS CLI 通过 S3InitiateRestoreObject 作业创建恢复作业:
$aws s3control create-job \
--region us-east-1 \
--account-id 123456789012 \
--operation '{"S3InitiateRestoreObject": { "ExpirationInDays": 1, "GlacierJobTier":"STANDARD"} }' \
--report '{"Bucket":"arn:aws:s3:::reports-bucket ","Prefix":"batch-op-restore-job", "Format":" S3BatchOperations_CSV_20180820","Enabled":true,"ReportScope":"FailedTasksOnly"}' \
--manifest '{"Spec":{"Format":"S3BatchOperations_CSV_20180820", "Fields":["Bucket","Key"]},"Location":{"ObjectArn":"arn:aws:s3:::inventory-bucket/inventory_for_restore.csv", "ETag":"<ETag>"}}' \
--role-arn arn:aws:iam::123456789012:role/s3batch-role然后,您可以运行以下 CLI 命令,检查请求的作业提交的状态:
$ aws s3control describe-job \
--region us-east-1 \
--account-id 123456789012 \
--job-id <JobID> \
--query 'Job'.'ProgressSummary'您可以查看和更新作业状态、添加通知和日志记录、跟踪作业失败以及生成完成报告。S3 批量操作作业活动在 AWS CloudTrail 中记录为事件。要跟踪作业事件,您可以在 Amazon EventBridge 中创建自定义规则,并将这些事件发送到您选择的目标通知资源,例如 Amazon Simple Notification Service(Amazon SNS)。
当您创建 S3 批量操作作业时,您还可以为所有任务或者仅为失败的任务请求完成报告。完成报告包含每项任务的额外信息,包括对象密钥名称和版本、状态、错误代码以及任何错误的描述。
有关更多信息,请参阅 Amazon S3 用户指南中的跟踪作业状态和完成报告。
以下是包含 250 个对象(每个对象的大小为 100 MB)的示例检索作业的结果。正如从之前的恢复性能行(右边的蓝色行)中所见,使用标准检索,这些恢复通常会在 3-5 小时内完成。现在,当您将标准检索与 S3 批量操作配合使用时,您的作业通常会在几分钟内开始,如经过改善的恢复性能行(左边的橙色行)所示,可将数据恢复时间缩短 85%。

要了解更多信息,请参阅 AWS 存储博客上的从 Amazon S3 Glacier 存储类大规模恢复存档对象以及 Amazon S3 用户指南中的恢复存档对象。
现已推出
现在,所有 AWS 区域,包括 AWS GovCloud(美国)区域和中国区域,均推出 Amazon S3 Glacier Flexible Retrieval 的更快标准检索。您可以免费获得这种性能改进。 您需要为 S3 批量操作和数据检索付费。有关更多信息,请参阅 S3 定价页面。
 最后,我们出版了名为“使用 Amazon S3 Glacier 最大化冷存储的价值”的新电子书。阅读这本电子书,了解 Amazon S3 Glacier 如何帮助各行各业各种规模的组织实现数据归档转型,以释放商业价值、提高敏捷性并节省存储成本。
最后,我们出版了名为“使用 Amazon S3 Glacier 最大化冷存储的价值”的新电子书。阅读这本电子书,了解 Amazon S3 Glacier 如何帮助各行各业各种规模的组织实现数据归档转型,以释放商业价值、提高敏捷性并节省存储成本。
要了解更多信息,请访问 S3 Glacier 存储类页面和入门指南,然后向 AWS re:Post for S3 Glacier 发送反馈,或通过您通常的 AWS Support 联系人发送反馈。
我很高兴您能开始使用这项新功能,我期待听到更多关于您如何使用存档数据重塑业务的信息。
– Channy