亚马逊AWS官方博客
全新 – 由 NVIDIA H100 Tensor Core GPU 提供支持的 Amazon EC2 P5 实例,用于加速实现生成式人工智能和 HPC 应用程序
2023 年 3 月,AWS 和 NVIDIA 宣布了一项多部分合作,重点是构建最具可扩展性的按需人工智能(AI)基础设施,该基础设施针对训练日益复杂的大型语言模型(LLM)和开发生成式人工智能应用程序进行了优化。
我们预先宣布由 NVIDIA H100 Tensor Core GPU 以及 AWS 最新联网和可扩展性技术提供支持的 Amazon Elastic Compute Cloud(Amazon EC2)P5 实例,该实例将为构建和训练最大型的机器学习(ML)模型提供高达 20 exaflops 的计算性能。该公告是 AWS 和 NVIDIA 之间十多年合作的产物,期间在 Cluster GPU(cg1)实例(2010 年)、G2(2013 年)、P2(2016 年)、P3(2017 年)、G3(2017 年)、P3dn(2018 年)、G4(2019 年)、P4(2020 年)、G5(2021 年)和 P4de 实例(2022 年)中提供视觉计算、人工智能和高性能计算(HPC)。
最值得注意的是,机器学习模型规模现在已达到数万亿个参数。但是,这种复杂性增加了客户训练模型的时间,最新的 LLM 现在需要经过长达数月的训练。HPC 客户也经历了类似的趋势。随着 HPC 客户数据集合的保真度不断提高,并且数据集达到 EB 规模,这些客户正寻求在日益复杂的应用程序中加快推出解决方案的方法。
EC2 P5 实例简介
今天,我们宣布全面推出 Amazon EC2 P5 实例,这是下一代 GPU 实例,旨在满足客户在人工智能/机器学习和 HPC 工作负载中对高性能和可扩展性的需求。P5 实例由最新的 NVIDIA H100 Tensor Core GPU 提供支持,与上一代基于 GPU 的实例相比,训练时间最多可缩短 6 倍(从几天缩短到几小时)。这种性能提升可让客户的训练成本降低多达 40%。
P5 实例提供 8 个 NVIDIA H100 Tensor Core GPU、640GB 的高带宽 GPU 内存、第三代 AMD EPYC 处理器、2TB 的系统内存以及 30TB 的本地 NVMe 存储空间。P5 实例还提供 3200Gbps 的聚合网络带宽(支持 GPUDirect RDMA),同时通过绕过 CPU 进行节点间通信实现更低的延迟和高效的横向扩展性能。
以下是这些实例的规格:
| 实例
大小 |
vCPU | 内存
(GiB) |
GPU
(H100) |
网络带宽
(Gbps) |
EBS 带宽
(Gbps) |
本地存储
(TB) |
| P5.48xlarge | 192 | 2048 | 8 | 3200 | 80 | 8 x 3.84 |
以下是简短的信息图,其中展示了 P5 实例和 NVIDIA H100 Tensor Core GPU 与以前实例和处理器的比较:
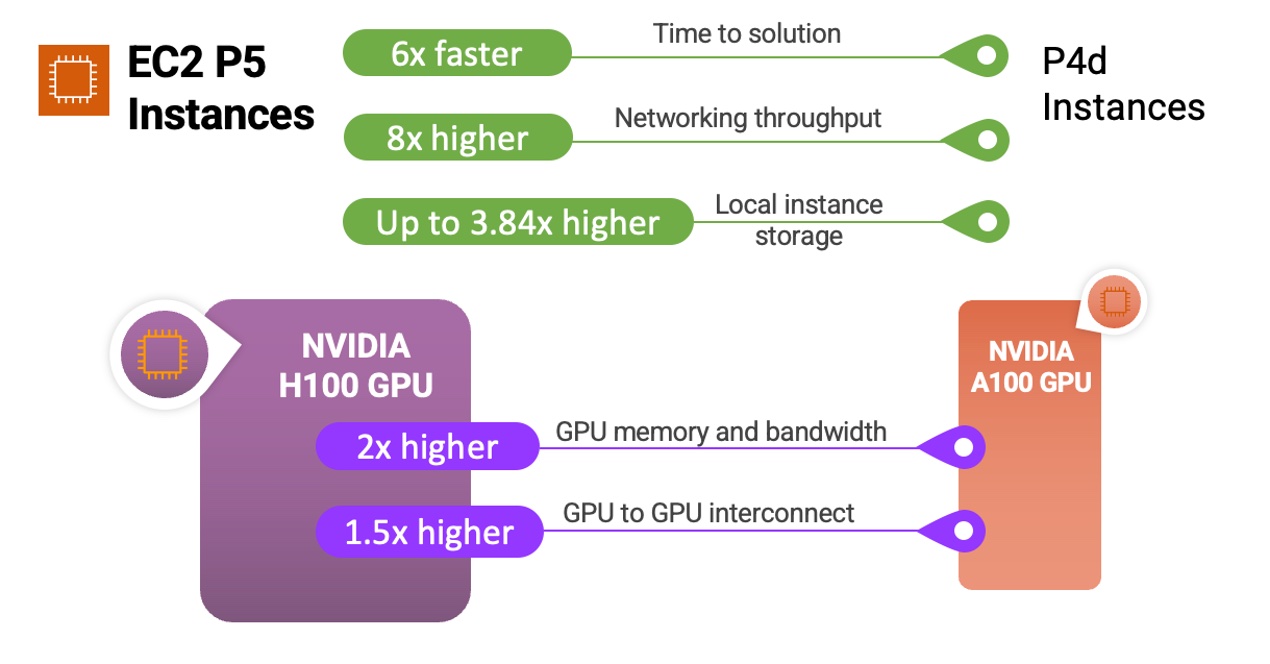
P5 实例非常适合训练和运行推理,适用于要求最严苛、计算密集型的生成式人工智能应用程序(包括问题解答、代码生成、视频和图像生成、语音识别等)背后日益复杂的 LLM 和计算机视觉模型。在这些应用程序中,与上一代基于 GPU 的实例相比,P5 提供最多可缩短 6 倍的训练时间。如果客户可以在工作负载中使用精度较低的 FP8 数据类型(使用转换器模型主干的许多语言模型中常见的类型),则通过支持 NVIDIA 转换器引擎,性能将进一步提升高达 6 倍。
使用 P5 实例的 HPC 客户可以在药物发现、地震分析、天气预报和财务建模等领域更大规模地部署要求严苛的应用程序。在基因组测序或加速数据分析等应用程序中使用动态编程(DP)算法的客户还将通过支持新的 DPX 指令集从 P5 中受益。
这可让客户探索以前看似无法触及的问题空间,更快地迭代其解决方案,以及更快地推向市场。
您可以在下面查看实例规格的详细信息以及 p4d.24xlarge 和全新 p5.48xlarge 之间实例类型的比较:
| 功能 | p4d.24xlarge | p5.48xlarge | 比较 |
| 加速器的数量和类型 | 8 x NVIDIA A100 | 8 x NVIDIA H100 | – |
| 每台服务器 FP8 TFLOPS | – | 16,000 | 640% vs.A100 FP16 |
| 每台服务器 FP16 TFLOPS | 2,496 | 8,000 | |
| GPU 内存 | 40GB | 80GB | 200% |
| GPU 内存带宽 | 12.8TB/秒 | 26.8TB/秒 | 200% |
| CPU 系列 | Intel Cascade Lake | AMD Milan | – |
| vCPU | 96 | 192 | 200% |
| 系统内存总量 | 1152GB | 2048GB | 200% |
| 联网吞吐量 | 400Gbps | 3200Gbps | 800% |
| EBS 吞吐量 | 19Gbps | 80Gbps | 400% |
| 本地实例存储 | 8TB NVMe | 30TB NVMe | 375% |
| GPU 到 GPU 的互连 | 600GB/秒 | 900GB/秒 | 150% |
第二代 Amazon EC2 UltraClusters 和 Elastic Fabric Adaptor
P5 实例为多节点分布式训练和紧密耦合的 HPC 工作负载提供市场领先的横向扩展功能。它们使用第二代 Elastic Fabric Adaptor(EFA)技术提供高达 3,200Gbps 的联网速度,与 P4d 实例相比提升 8 倍。
为了满足客户对大规模和低延迟的需求,在第二代 EC2 UltraClusters 中部署 P5 实例,现在可为客户提供在多达 20,000 多个 NVIDIA H100 Tensor Core GPU 上的更低延迟。EC2 UltraClusters 中的 P5 实例提供云端最大规模的机器学习基础设施,可带来高达 20 exaflops 的聚合计算能力。

EC2 UltraClusters 使用 Amazon FSx for Lustre,这是基于最受欢迎的高性能并行文件系统构建的完全托管共享存储。借助 FSx for Lustre,您可以按需大规模快速处理海量数据集,并可实现亚毫秒级的延迟。FSx for Lustre 的低延迟和高吞吐量特性已针对 EC2 UltraClusters 上的深度学习、生成式人工智能和 HPC 工作负载进行优化。
FSx for Lustre 为 EC2 UltraClusters 中的 GPU 和机器学习加速器持续提供数据,从而加速处理最严苛的工作负载。这些工作负载包括 LLM 训练、生成式人工智能推理和 HPC 工作负载,例如基因组学和金融风险建模。
EC2 P5 实例入门
首先,您可以在美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)区域使用 P5 实例。
启动 P5 实例时,您将选择 AWS Deep Learning AMI(DLAMI)来支持 P5 实例。DLAMI 为机器学习从业者和研究人员提供基础设施和工具,以便在预配置的环境中快速构建可扩展、安全的分布式机器学习应用程序。
您将能够使用 Amazon Elastic Container Service(Amazon ECS)或 Amazon Elastic Kubernetes Service(Amazon EKS)的库在带有 AWS 深度学习容器的 P5 实例上运行容器化应用程序。 要获得更加妥善管理的体验,您还可以通过 Amazon SageMaker 使用 P5 实例,该工具可以帮助开发人员和数据科学家轻松扩展到数十、数百或数千个 GPU,从而以任何规模快速训练模型,而不必担心集群和数据管道的设置。HPC 客户可以利用带有 P5 实例的 AWS Batch 和 ParallelCluster 来帮助高效地编排作业和集群。
现有 P4 客户需要更新其 AMI 才能使用 P5 实例。具体而言,需要更新 AMI 以包含支持 NVIDIA H100 Tensor Core GPU 的最新 NVIDIA 驱动程序。这些客户还需要安装最新的 CUDA 版本(CUDA 12)、CuDNN 版本、框架版本(例如 PyTorch、Tensorflow)和带有更新拓扑文件的 EFA 驱动程序。为了让您轻松完成此过程,我们将提供新的 DLAMI 和深度学习容器,这些容器预先打包立即使用 P5 实例所需的所有软件和框架。
现已推出
Amazon EC2 P5 实例现已在如下 AWS 区域推出:美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)。有关更多信息,请参阅 Amazon EC2 定价页面。要了解更多信息,请访问我们的 P5 实例页面,浏览 AWS re:Post for EC2 或通过您平时的 AWS Support 联系方式进行探索。
可以选择内置生成式人工智能的广泛 AWS 服务,所有这些服务均在适用于生成式人工智能的最具成本效益的云基础设施上运行。要了解更多信息,请访问 AWS 上的生成式人工智能,以更快地进行创新并重塑您的应用程序。
— Channy