亚马逊AWS官方博客
使用 Prometheus 与 Grafana 对 Amazon EMR上的分析类工作负载进行监控与优化
Amazon EMR 是AWS推出的一项大数据服务,旨在以经济高效的方式在AWS上运行Apache Spark以及其他多种开源应用程序。正因为如此,要实时检测应用程序或基础设施中存在的关键问题并实现快速溯源,我们就必须对Amazon EMR集群开展持续监控。监控集群在一定时段内的运作及使用情况,将帮助运营及工程团队及时发现潜在的性能瓶颈与优化空间,借此进行集群规模伸缩并规划所需容量。在本文中,我们将展示如何集成开源系统监控与警报工具Prometheus,以及开源可视化与分析工具Grafana,借此为EMR集群建立一套端到端监控系统。此外,我们还将分享相关示例,演示如何使用Prometheus与Grafana发现改进机会,借此优化您的EMR运作效率、提高性能并降低成本。
本文将具体讨论以下内容:
- 在Amazon Elastic Compute Cloud (Amazon EC2)实例上安装并配置Prometheus与Grafana。
- 配置EMR集群,收集由Prometheus从中抓取到的关键指标。
- 使用Grafana仪表板对EMR集群上的工作负载运行指标进行分析与优化。
- 了解Prometheus如何向Alertmanager(属于Prometheus中的一项组件)推送警报,由Alertmanager将通知发送至alert_sns_forwarder组件,后者最终将通知转发至Amazon Simple Notification Service (Amazon SNS)。
- 配置Amazon SNS以发送邮件通知。
- 将这套监控系统引入生产环境时,需要考虑的部分注意事项。
下图所示,为这套解决方案的基本架构。

Exporters,是指从受监控系统处收集指标,并为Prometheus提供端点以实现指标轮询的代理。Node_exporter与jmx_exporters分别从EMR集群中各个节点的操作系统与应用程序(例如YARN与HDFS)当中收集指标。
Prometheus服务器将对这些exporters在各节点上公开的端点进行轮询,借此完成指标收集。各项指标将被存储在本地Prometheus服务器之上。当用户通过浏览器开启Grafana仪表板时,Grafana服务器将查询Prometheus服务器以生成实际显示的仪表板内容。
大家可以在Prometheus当中设置警报选项;一旦超出警报阈值,Prometheus服务器即会将警报推送至Alertmanager。Alertmanager负责对通知执行重复数据删除、分组并路由至接收程序。在Alertmanager的原生支持下,接收程序再进一步将各事件分别发送至PagerDuty、Slack、Opsgenie等目标处。
由于Alertmanager并未与Amazon SNS原生集成,因此我们需要使用通用webhook接收程序 alert_sns_forwarder,借此将通知消息转换并路由至Amazon SNS内的预配置主题当中。大家可以通过电子邮件、手机短信、HTTP/S、Amazon Simple Queue Service (Amazon SQS)或者 AWS Lambda等订阅该主题并接收警报。
先决条件
在实际操作之前,大家需要做好以下准备:
- 用于访问各AWS服务的AWS账户。
- 一个还有访问密钥及secret访问密钥的AWS身份与访问管理(IAM)用户,用于配置AWS命令行界面(CLIO)。
- 此IAM用户应有权创建IAM角色与策略、创建SNS主题、启动EMR集群,并在AWS CloudFormation中创建栈。
- 带有公共子网的Amazon VPC。
解决方案部署
在本文中,我们提供一份CloudFormation模板作为通行指南,您可以根据实际需求对其进行检查与定制。另外需要强调的是,此栈中部署的某些资源会在使用状态下产生成本。
结合本文的讨论场景,相关资源将安装在一个带有公共子网的VPC内。我们建议大家在生产环境中尽可能将资源安装在私有子网内。另外,我们还建议您在Prometheus与node_exporter及jmx_exporter之间、包括在Grafana之上,启用TLS连接与密码验证机制。为了简化设置过程,示例CloudFormation模板会将端口9090设置为网络入口,保证您能够远程访问Prometheus UI。如果不需要,请删除此访问权限。
示例CloudFormation模板还包含几个嵌套模板,用于协同实现以下操作:
- 选择部署本解决方案的VPC与子网。
- 使用您选定的实例类型创建一个EC2实例。
- 以服务形式下载、安装并配置Pormetheus,并辅以正确的抓取配置以接入待监控的目标EMR集群。
- 以服务形式下载、安装并配置
alert_sns_forwarder,借此将警报通知从AlertManager转换为Amazon SNS消息,并将这些消息发布至Amazon SNS。 - 以服务形式下载、安装并配置Alertmanager,借此将警报通知从Prometheus服务器转发至
alert_sns_forwarder。 - 设置样本警报,用于在待监控EMR集群上任意节点的磁盘空间利用率超过90%时,将通知消息发送至Amazon SNS。
- 以服务形式下载、安装并配置Grafana,借此接入Prometheus数据源。我们还将在待监控的目标EMR集群上预先安装以下仪表板,实现各项指标的可视化显示:
- OS Level Metrics – 选择由Amazon Linux操作系统公开的CPU、内存与磁盘指标。
- HDFS – DataNode Metrics – 选择由HDFS数据节点进程公开的存储与网络指标。
- HDFS – NameNode Metrics – 选择由HDFS命名节点进程公开的存储与副本指标。
- YARN – Resource Manager – 选择由YARN资源管理器进程公开的资源、应用程序与容器指标。
- YARN – Node Manager – 选择由YARN节点管理器进程公开的资源与容器指标。
- YARN – Queues – 选择由YARN队列过滤的资源、应用程序与容器指标。
- JVM Metrics – 选择由HDFS JVM及YARN进程公开的内存与垃圾回收指标。
- Log Metrics – 记录由HDFS记录程序及YARN进程收集的失败、错误与警报。
- RPC Metrics – 选择由HDFS与YARN进程公开的RPC指标。
- 创建一个Amazon EC2安全组,大家可以通过CloudFormation模板中的对应参数配置指向入口TCP端口22(SSH)、Grafana(3000)以及Prometheus UI(9090)的网络访问。以此为基础,您可以锁定指向Prometheus与Grafana EC2实例的访问请求,且仅允许来自已知CIDR范围与端口的访问操作。
- 创建一个IAM实例配置文件,用于为已安装的Prometheus与Grafana分配EC2实例。
- 创建一个SNS主题,并在模板中以参数形式订阅对应电子邮件地址,借此从Prometheus Alertmanager处接收通知消息。
- 使用引导操作脚本启动EMR集群,具体流程如下:
- 下载并设置
node_exporter,由其以即服务形式将全部节点上的OS指标公开至Prometheus。 - 下载
jmx_exporter,由HDFS命名节点、HDFS数据节点、YARN资源管理器以及YARN节点管理器进程利用它在所有节点上向Prometheus公开应用程序指标。 - 在集群上配置HDFS命名节点、HDFS数据节点、YARN资源管理器以及YARN节点管理器进程,保证
jmx_exporter以Java探针的形式加以启动。
- 下载并设置
- 为EMR集群创建额外的主安全组与辅助安全组,允许网络流量进入Prometheus服务器上的端口7001、7005与9100。
启动CloudFormation栈
要启动栈并置备相关资源,大家需要完成以下操作步骤:
- 选择以下 Launch Stack 链接: https://us-east-1.console.thinkwithwp.com/cloudformation/home?region=us-east-1#/stacks/create/template?templateURL=https://aws-bigdata-blog.s3.amazonaws.com/artifacts/aws-blog-emr-prometheus-grafana/cloudformation_templates/emrPrometheusGrafana.cf.json
这项操作会使用模板自动在您的AWS账户中启动AWS CloudFormation模板。系统会提示您进行登录,大家则可根据需要在AWS CloudFormation控制台上查看该模板详情。这里提醒大家,请注意在正确的目标区域内创建此栈。
这套CloudFormation栈还需要使用多项参数,具体如以下截屏所示。
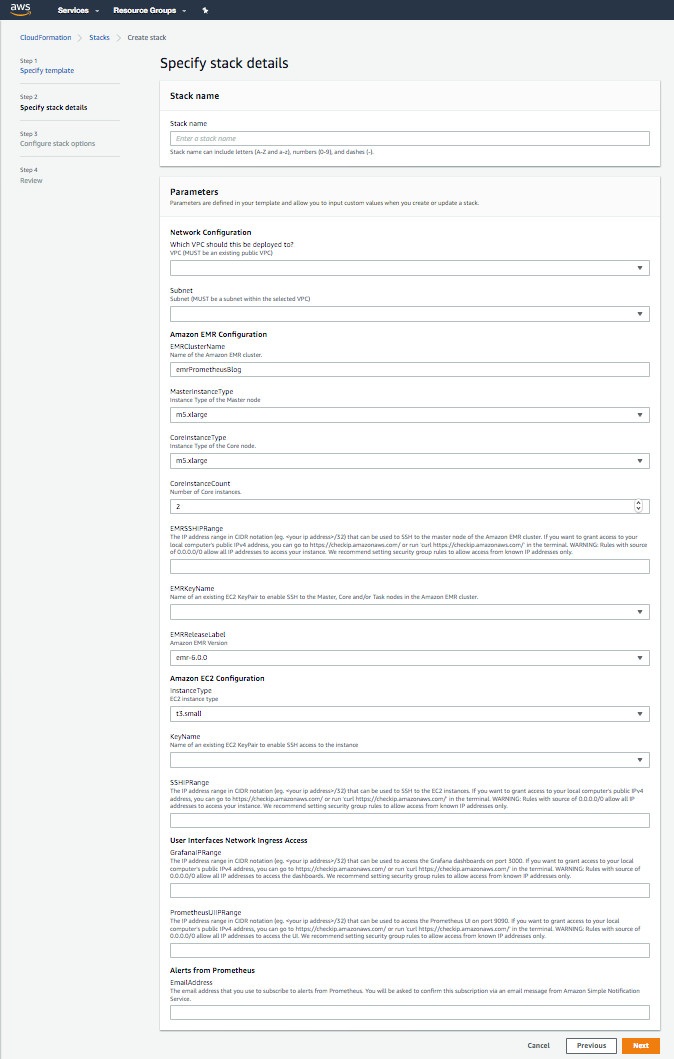
下表所示,为各项参数的基本说明:
| 参数 | 说明 | 默认值 |
| 栈名称 | 具备可读性的栈名称,例如 emrPrometheusGrafana。 |
无 |
| 网络配置 | ||
| VPC | 即EC2实例与EMR集群启动所处的VPC。 | 无 |
| 子网 | 即EC2实例与EMR集群启动所处的子网。 | 无 |
| Amazon EMR配置 | ||
| EMRClusterName | EMR集群名称。 | emrPrometheusBlog |
| MasterInstanceType | 主节点的实例类型。 | m5.xlarge |
| CoreInstanceType | 核心节点的实例类型。 | m5.xlarge |
| CoreInstanceCount | 核心实例数量。 | 2 |
| EMRSSHIPRange | 用于通过SSH连接至EMR集群主节点的CIDR注释中的IP地址范围(例如<您的ip地址 >/32)。如果您希望授权对本地计算机的公共IPv4地址进行访问,则可前往 https://checkip.amazonaws.com/或在终端中运行curl https://checkip.amazonaws.com/。0.0.0.0/0源规则允许所有IP地址访问您的实例。我们建议您设置安全组规则,约定仅允许来自已知IP地址的访问。 |
无 |
| EMRKeyName | 用于通过SSH接入EMR集群主节点的现有EC2密钥对。 | 无 |
| EMRReleaseLabel | Amazon EMR版本。 | emr-6.0.0 |
| Amazon EC2 配置 | ||
| InstanceType | 用于安装Prometheus、Alertmanager、 alert_sns_forwarder以及Grafana服务的EC2实例类型。由于此实例负责托管Prometheus服务器,而该服务器将作为时序数据库保存指标数据,因此实例类型应至少拥有50 GB可用磁盘空间(具体取决于使用需求)。在本文中,我们选择使用t3.small节点类型。 |
t3.small |
| KeyName | 用于通过SSH接入该实例的现有EC2密钥对。 | 无 |
| SSHIPRange | 用于通过SSH连接至该EC2实例的CIDR注释中的IP地址范围(例如<您的ip地址 >/32)。如果您希望授权对本地计算机的公共IPv4地址进行访问,则可前往 https://checkip.amazonaws.com/或在终端中运行curl https://checkip.amazonaws.com/。 |
无 |
用户界面网络入口访问 |
||
| GrafanaIPRange | 用于在端口3000上接入Grafana仪表板的CIDR注释中的IP地址范围(例如<您的ip地址 >/32)。如果您希望授权对本地计算机的公共IPv4地址进行访问,则可前往 https://checkip.amazonaws.com/或在终端中运行curl https://checkip.amazonaws.com/。 |
无 |
| PrometheusUIIPRange | 用于在端口9090上访问Prometheus UI的CIDR注释中的IP地址范围(例如<您的ip地址 >/32)。如果您希望授权对本地计算机的公共IPv4地址进行访问,则可前往 https://checkip.amazonaws.com/或在终端中运行curl https://checkip.amazonaws.com/。 |
无 |
| Prometheus警报 | ||
| EmailAddress | 您用于订阅Prometheus警报消息的电子邮件地址。您需要通过由Amazon SNS发出的邮件信息确认订阅。 | 无 |
- 输入上表中的各项参数值。
- 选择 Next。
- 在下一屏幕中,输入必要标签、IAM角色或者其他高级选项。
- 选择 Next。
- 在最后一屏内检查详细信息,而后选中复选框以确认CloudFormation可能根据需求创建具有自定义名称的IAM资源,或要求使用
CAPABILITY_AUTO_EXPAND。
- 选择 Create。

栈创建可能需要几分钟时间。在CloudFormation栈创建完毕之后,您可在Outputs选项卡中找到以下三个键-值对:
- ClusterId – 所创建EMR集群的ID。
- MasterPublicDnsName – EMR集群主节点的公共DNS名称。
- WebsiteURL – 新创建Grafana仪表板的URL。默认登录名与密码皆为
admin。在首次登录时,系统会提示您更改密码。
此外,您还将从no-reply@sns.amazonaws.com 处收取到一封电子邮件,要求您确认来自Amazon SNS的订阅提示。
- 在邮件中,选择Confirm订阅链接。
现在,我们已经成功通过电子邮件订阅SNS主题,可随时从Prometheus处收取警报信息了。
工作负载示例
以下用例所示,为如何使用Grafana仪表板中的Amazon EMR指标及分析结论,对集群上运行的Hadoop作业进行性能调优。
此用例只是一项简单的WordCount计数作业,可计算输入文件中的单词数量。大家可以从sourcecode.zip处下载WordCount程序源代码。这是一款非常基础的MapReduce程序。您可以使用Yelp开放数据集中的Yelp业务审查数据集,其原始数据为JSON格式。在本示例中,请将该数据集转换为GZIP(大小约为2.4 GB)与BZIP2(大小约为1.8 GB)格式。最后,在先前启动完成的集群上运行此WordCount作业。
通过以下代码,我们将向集群中添加新步骤以启动作业(请将 <j-*************> 部分替换为您刚刚创建的CloudFormation栈中Outputs选项卡内的集群ID,并将 <s3://bucket-name/outputs-folder> 替换为Amazon Simple Storage Service (Amazon S3)位置以作为作业输出目标):
您可以随时输入以下代码以取消该步骤(将 <j-*************> 替换为集群ID,将 <s-*************> 替换为步骤ID):
当以上步骤处于RUNNING状态时,前往Grafana仪表板即可查看指标分析结果。以下截屏所示,为YARD – Resource Manager仪表板的显示内容。
在作业执行的很长一段时间内,Container Stats指标中只会显示分配有两个容器(ApplicationMaster容器与mapper容器),且不存在暂时挂起的容器。这是因为我们的作业 输入格式为GZIP,无法进行拆分。在这种情况下,无论输入文件有多大,系统都只会启动一个mapper容器以对应唯一一个 InputSplit。直到mapper阶段结束,reducer阶段开始后,容器配额才会对应增加。
VCores Utilization显示出相同的结果:其长时间保持在50%以下,直到单一mapper容器执行完成,并添加多个reducer容器为止。
通过OS Level Metrics 仪表板(如下图所示)来看,此作业在mapper阶段的CPU与内存资源利用率也非常低,导致处理时间被大大延长。

对于一套包含一个m5.xlarge主节点与两个m5.xlarge核心节点的集群,这项作业需要30分钟才能完成。而在这30分钟之内,单是mapper阶段就用去了28分钟。
根据来自仪表板的相关结论,我们可以做出一些有针对性的性能调整。
仍然使用同一数据集,接下来我们转为使用BZIP2格式(而非GZIP)作为输入文件,并使用以下代码执行提交(将 <j-*************> 替换为CloudFormation栈中OutPuts选项卡内的集群ID,并将 <s3://bucket-name/outputs-folder> 替换为作业输出所指向的Amazon S3存储位置):
当此步骤处于RUNNING状态时,重新查看仪表板提示。
以下截屏所示,为YARD – Resource Manager仪表板的显示内容。

Container Stats 显示,作业开始时立即分配了七个容器。此外,挂起容器数量明显更高,为46。我们这次使用的BZIP2输入格式是一种可以拆分的压缩格式。结果就是,系统将启动多个mapper容器,每个容器处理一个InputSplit。这就极大改善了mapper阶段的并发水平。
VCores Utilization 还显示,VCores在作业峰值期间的利用率为100%。
下图中的OS Level Metrics 仪表板显示,此作业运行期间的资源利用率也有所提高。
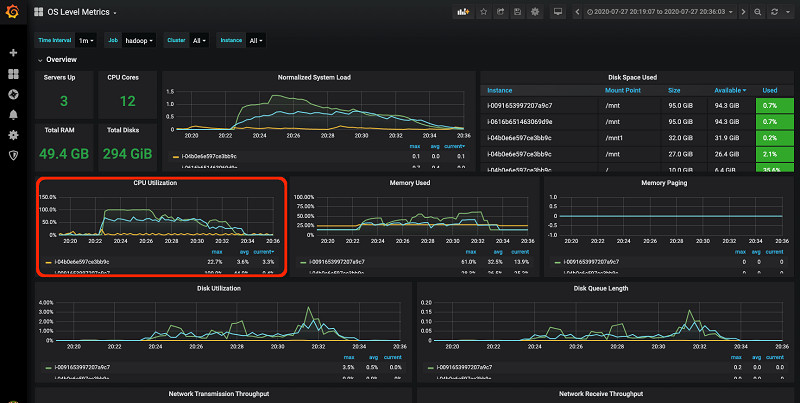
此项作业的处理时长缩短至11分钟,相较于上一轮运行实现了63%的性能提升。
处理时间还有进一步优化的余地吗?通过仪表板的显示内容,答案是肯定的。在第二轮运行过程中,曾出现46个挂起容器等待分配的情况,彼时的VCores Utilization为100%。这意味着集群已经按容量为所有容器分配了资源。大家可以全长以下代码,添加包含10个m5.xlarge任务节点的任务实例组以调整集群大小(将 <j-*************>替换为集群ID):
使用add-instance-groups命令后,返回的输出结果如下所示:
请记录其中InstanceGroupIds的值;我们稍后需要使用它将实例组内的节点设置为0。
经过重新调整之后,YARN – Resource Manager仪表板更新为下图所示。

使用以下代码,大家可以使用同样的BZIP2格式输入数据集再次运行这一作业:
这一次,作业在启动之后立即分配了所有待处理容器;由于集群总节点数有所增加,因此不再出现容器挂起状况。
此轮作业耗时4分钟;与第二轮相比,性能提升64%;与第一轮相比,性能更是提升达87%。
为了节约成本,我们在作业完成之后,可以通过以下代码将之前通过任务实例组中添加的任务节点数减少为0,借此实现集群规模收缩(请将<ig-************>替换为您之前记录的实例组ID):
警报示例
我们创建的CloudFormation栈会设置一项警报,用以监控EMR集群中的全体节点。以此为基础,一旦磁盘分区容量占用率超过90%,您所指定的电子邮件地址将收到一封警报邮件。
请按照以下步骤,将超大示例文件写入集群中主节点上的磁盘分区,而后等待系统触发电子邮件警报:
使用密钥通过SSH接入EMR集群主节点:
您可以在之前创建的CloudFormation栈上的Outputs选项卡中,查看主节点的公共DNS名称。
- 输入以下代码,显示当前磁盘容量使用情况:
- 创建一个大小为4.5 GB的文件,用于将磁盘容量利用率提升至90%以上:
- 再次检查磁盘容量使用情况,确认利用率已经高于90%。详见以下代码:
大家也可以通过Grafana OS Level Metrics仪表板查看磁盘使用信息。从以下截屏中可以看到,Disk Space Used面板中的/emr分区利用率已经达到91.1%。
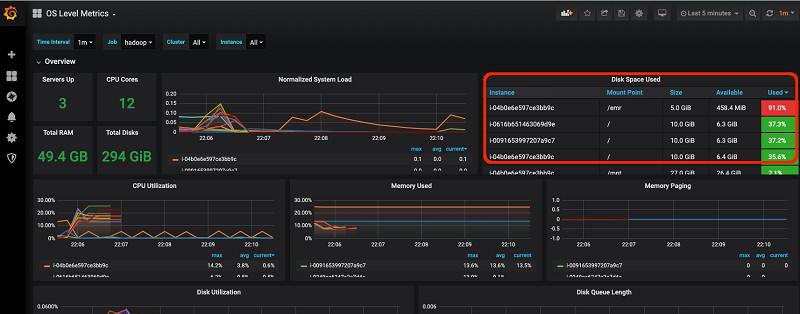
现在,您应该在收件箱中收到一封电子邮件,发件方为no-reply@sns.amazonaws.com,标题为“Prometheus Alert”。
生产注意事项
Prometheus将所有指标存储在一套安装时内置的本地时序数据库当中。本文建议大家规划磁盘容量、磁盘可用性以及备份快照,借此提高系统的持久性水平。
在默认情况下,指标存储周期为15天。您可以使用--storage.tsdb.retention.time命令行标记调整此项保留期限。关于提供远程长期存储并在特定情况下实现高可用性的解决方案,请参阅远程端点与存储。Alertmanager还支持集群创建以进一步提升可用性。关于更多详细信息,请参阅GitHub repo上的高可用性部分。
另一项重点,在于保证Prometheus监控系统停止运行时及时发出通知。默认情况下,Prometheus服务器与Alertmanager分别通过localhost:9090/metrics 与 localhost:9093/metrics端点公开自身指标。您可以将这些指标抓取并发布至Amazon CloudWatch,并设置CloudWatch警报以触发指标数据点缺失警报。关于更多详细信息,请参阅如何使用Amazon CloudWatch警报。
资源清理
为了避免持续产生费用,请删除工作负载用例运行期间创建的CloudFormation栈与Amazon S3中的输出文件。
总结
本文介绍了如何使用Prometheus与Grafana设置监控系统,借此监控目标EMR集群;以及如何使用Grafana仪表板查看关键指标以优化各类性能问题。大家也可以在Prometheus中设置警报,保证系统在发生严重问题时发出通知,并参考仪表板以缩小故障排查范围。您还可以根据需求扩展这套监控系统,利用它监控多个EMR集群及其他应用程序,打造出一套完整的、覆盖整体基础设施与应用程序的一站式指标监控系统。