亚马逊AWS官方博客
RDS MySQL的日志管理
概述
数据库日志是分析研究业务状态的参考资料,也是发生事故或审计时,可追溯检查的最具可靠性和权威性的原始记录,是寻找问题根源的重要的证据之一。
RDS MySQL的默认参数组和选项组并没有打开所有的日志选项。RDS的控制台里提供了把日志直接输出到CloudWatch的方法,可以在CloudWatch里面直接分析日志。如果对于成本比较敏感,我们也可以通过Lambda定期把日志导出到S3做存储和分析。
本教程旨在帮助初次接触RDS并想导出日志的用户,包含以下几部分内容:
- 通过S3存储桶做日志的生命周期管理
- 开启RDS(MySQL) 的日志
- 通过Lambda转储RDS日志
通过S3存储桶做日志的生命周期管理
Amazon S3是一种对象存储服务,有行业领先的扩展性、数据可用性、安全性和性能。S3不但能可靠又低成本的保存日志,还能通过生命周期管理功能自动归档或删除过期的日志。
创建S3存储桶
因为S3存储桶的名字是DNS的一部分,要起一个独一无二的名字,然后选择区域,创建存储桶。
阻止所有公有访问权限选项默认是选中的,强烈建议不要改这个地方,否则数据有被他人访问的风险。

为存储桶设置生命周期管理策略
1)进入存储桶,在管理选项卡内点击+添加生命周期

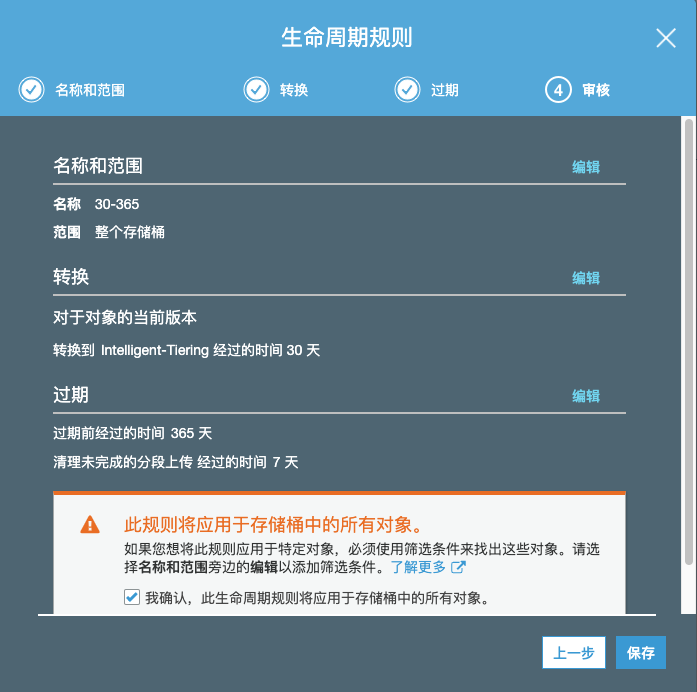
2)设置生命周期规则
设立一个30-365为名的规则,30天后自动用智能分层功能降低存储成本,365天后删除日志。




开启RDS(MySQL) 的日志
MySQL 有错误日志、慢查询日志、常规日志、审计日志和Binlog。错误日志是默认打开的,慢查询日志和审计日志需要修改参数组才能打开,审计日志需要修改选项组才能打开。Binlog默认不保存。
| MySQL RDS | 打开方法 | 默认保存周期 |
| 审计日志 | 修改选项组 | 文件达到1MiB后轮换,保留9个文件 |
| 错误日志 | 已默认打开 | 文件每小时轮换一次,保留24小时 |
| 慢查询日志 | 修改参数组 | mysql.slow_log表,每24小时轮换 |
| 常规日志 | 修改参数组 | mysql.general_log表,每24小时轮换 |
| binlog | 执行存储过程 | 生成后尽快被删除,不保存 |
创建选项组开启审计日志
注意:更换选项组或修改审计选项不会造成RDS重启,但可能造成连接中断。
支持MySQL5.6和5.7 版本。
1)选择正确的引擎版本,创建选项组

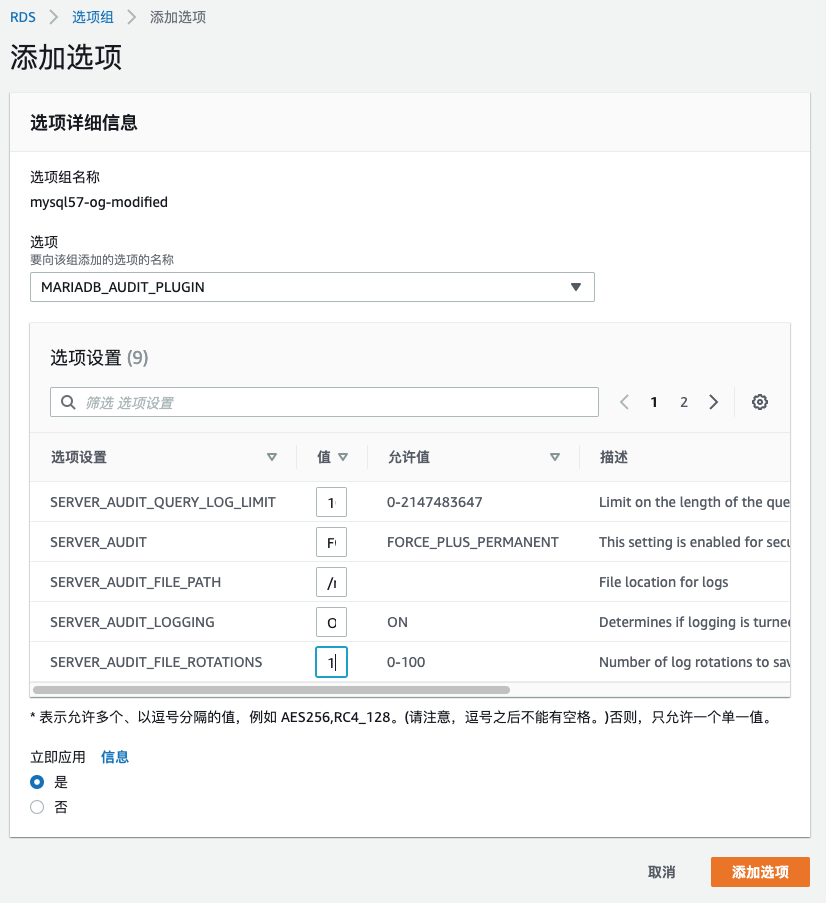
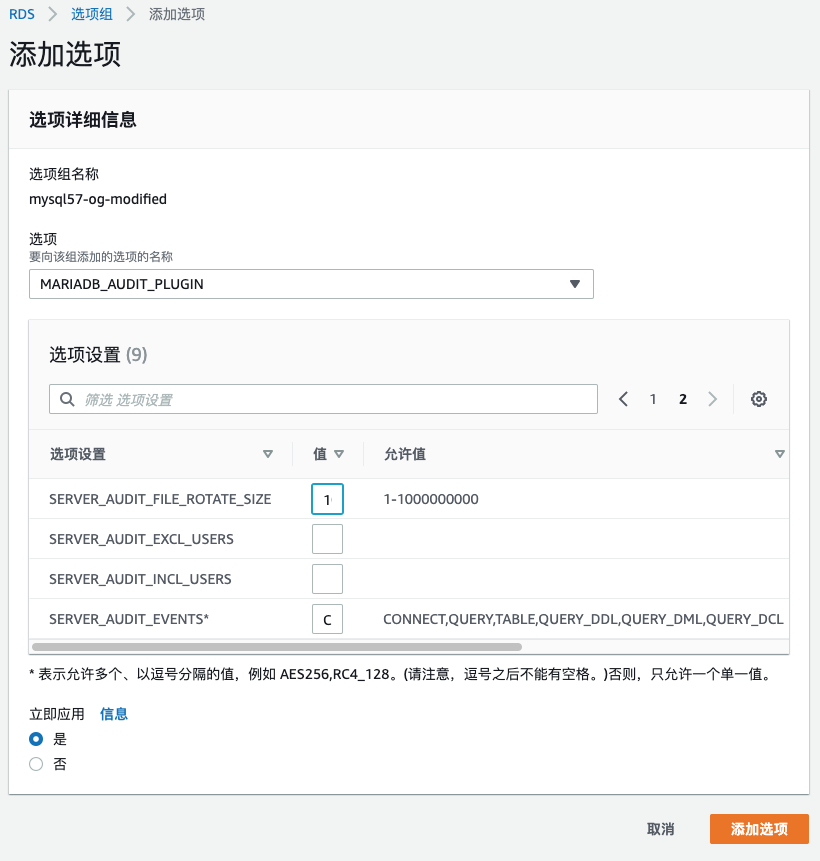
2)给新创建的选项组增加审计插件选项
默认:保留9个审计文件,每个文件大小1MiB。请根据业务情况修改。
例:100个文件,每个100MiB(占10GiB)。
SERVER_AUDIT_FILE_ROTATIONS: 100
SERVER_AUDIT_FILE_ROTATE_SIZE: 100000000
选项的含义和取值范围可参考下面的链接https://docs.thinkwithwp.com/zh_cn/AmazonRDS/latest/UserGuide/Appendix.MySQL.Options.AuditPlugin.html
开启常规日志和慢查询日志,performance_schema
注意:更换参数组需要重启RDS,更改参数组中的参数可能需要重启RDS。
开启常规日志和慢查询日志会影响DB的性能,尤其是DB负载很高查询很多的时候。因此请根据情况选择是否打开。
修改参数的影响请参考下面的链接:https://docs.thinkwithwp.com/zh_cn/AmazonRDS/latest/UserGuide/USER_ModifyInstance.MySQL.html#USER_ModifyInstance.MySQL.Settings
1)选择正确的数据库系列,创建参数组

2)编辑新创建的参数组
存储日志到文件:log_output = FILE
开启常规日志: general_log = 1
开启慢查询日志:slow_query_log = 1
long_query_time = 3.5(记录超过3.5秒的查询)
log_queries_not_using_indexes = 1 (记录未使用索引的查询)
开启performance_schema:performance_schema = 1
RDS参数组没有默认打开performance_schema,建议打开。

在RDS上保存Binlog
RDS的Binlog生成后会很快被删除。为了故障调查等原因,建议保留一定时间。保留Binlog会占用RDS的磁盘空间。
连上RDS后可以用下面的存储过程行设定Binlog的保存时间,比如24小时:
> call mysql.rds_set_configuration(‘binlog retention hours’, 24);
查询当前设置用下面的存储过程
> call mysql.rds_show_configuration;
注:如果要RDS生成Binlog,还需要修改数据库实例,设置备份保留期在1天以上。
下载binlog要用mysqlbinlog程序,详情请参照
https://docs.thinkwithwp.com/zh_cn/AmazonRDS/latest/UserGuide/USER_LogAccess.Concepts.MySQL.html
修改RDS实例,使用新创建的选项组和参数组(需要重启RDS)
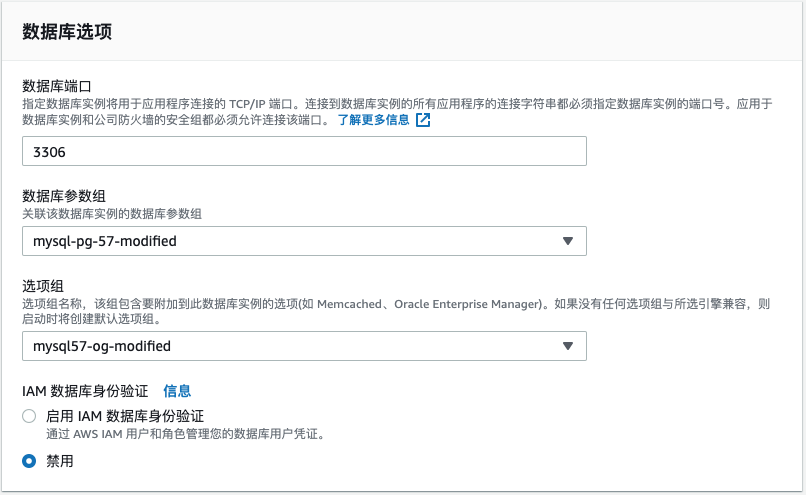


RDS的Configuration页面是pending-reboot状态,RDS重启后变成in-sync状态,设置生效。

通过Lambda转储RDS日志
AWS Lambda是无服务器计算服务,可运行代码来响应事件并自动管理底层计算资源。它非常适合在一天导出几次日志这样的场景来使用。
代码说明
1)这段代码利用API获得RDS的日志状态。其中describeDBLogFiles获得1小时内新生成的日志一览后依次处理各个日志。downloadDBLogFilePortion下载日志并压缩后存储到Lambda的/tmp临时路径,putObject上传日志文件到S3存储桶。
2)Lambda代码最多运行15分钟,处理能力与分配的内存大小有关。建议分配256MiB以上的内存并指定15分钟的超时时间。如果RDS在业务繁忙时间生成的日志量太大,Lambda不能在15分钟内处理完所有日志,就需要分配更大的内存。
3)Lambda的临时路径/tmp的容量是512MiB,以20%的压缩比率计算,能处理最大2.5GiB的单个日志。
4)Lambda除了基本的执行权限以外,还需要内联策略下载RDS日志,附加AWSLambdaExecute权限上传到S3。
5)日志会储存到指定的存储桶,路径结构如下
<bucket>–RDS–<rds_id>–<log_type>–<YYYY-MM-DD>

创建Lambda的步骤
1)从头创建lambda 函数

这个步骤将创建一个拥有基本的Lambda执行权限的角色。后面第4)步中再给它添加RDS和S3的访问权限。
2)配置一个CloudWatch Events,每小时的第10分钟自动执行Lambda
Schedule可以用Crontab格式:cron(10 * ? * * *)

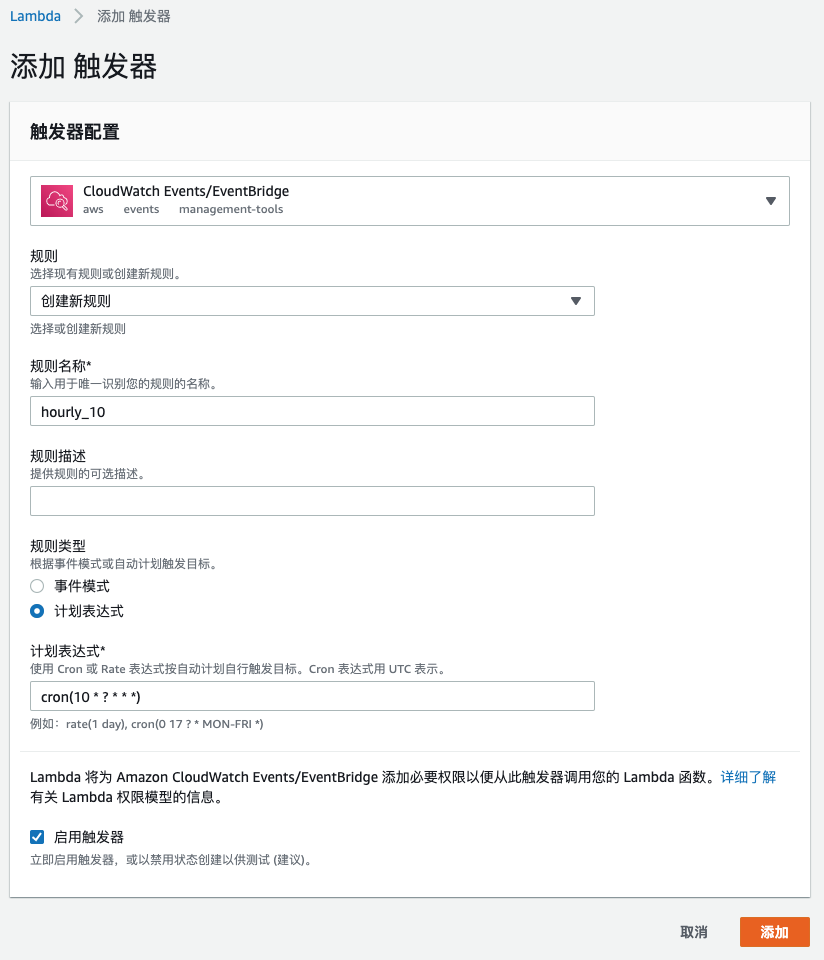
3)复制示例代码到函数代码框
Lambda示例代码(NodeJS 12):
下面的代码里面,rdsid、bucket、region三个变量需要根据实际情况修改。

粘贴和修改完代码以后,要点击一下画面右上角的保存按钮。
4)编辑基本设置中的内存和超时

权限设置,点击下方查看…角色的链接,为RDS和S3的相关操作附加策略。权限设置完成后再点保存。

先附加策略AWSLambdaExecute

再添加内联策略
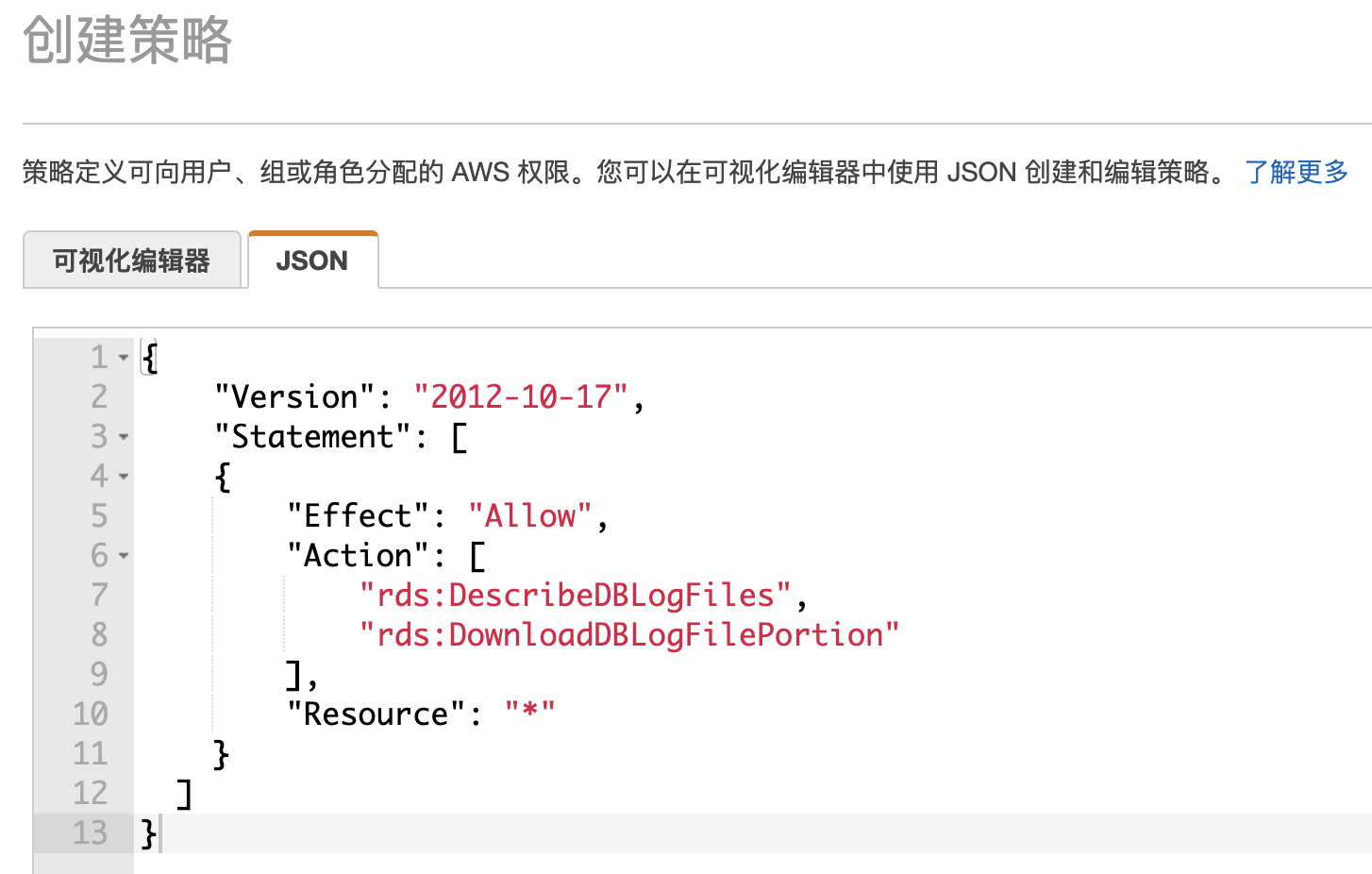
在JSON窗口粘贴以下内容,创建一个名为LambdaDownloadRDSLog的策略


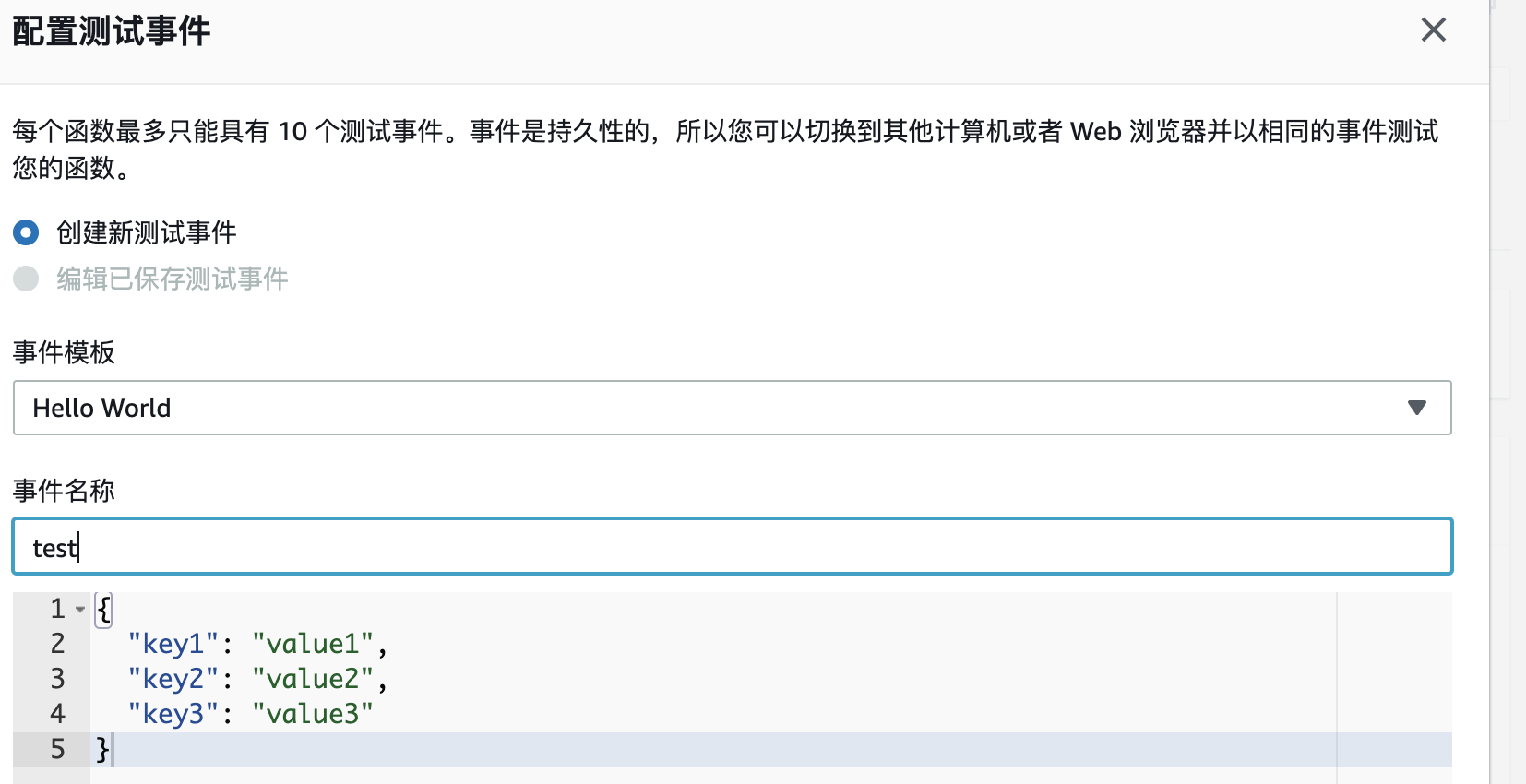
5)测试Lambda函数
这个Lambda函数是定时驱动的,不需要传入参数。点击测试按钮后用默认事件模版创建一个测试事件,然后再测试。


执行结果的详细信息里面,会列出describeDBLogFiles获得的1小时内新生成的日志一览,downloadDBLogFilePortion分页下载日志的结果,putObject上传日志文件到S3存储桶的结果。

Lambda函数测试通过以后,就可以保存下来。这个函数会被刚才配置的CloudWatch事件定期触发,自动转储日志到S3存储桶。
参考链接
1.S3对象生命周期管理:https://docs.thinkwithwp.com/zh_cn/AmazonS3/latest/dev/object-lifecycle-mgmt.html
2.RDS MySQL日志文件:
https://docs.thinkwithwp.com/zh_cn/AmazonRDS/latest/UserGuide/USER_LogAccess.Concepts.MySQL.html
3.MariraDB审核插件支持:
4.修改RDS数据库实例:
5.在Lambda控制台配置函数
https://docs.thinkwithwp.com/zh_cn/lambda/latest/dg/configuration-console.html
6.Node.js中的Lambda函数处理程序
https://docs.thinkwithwp.com/zh_cn/lambda/latest/dg/nodejs-handler.html
7.AWS Node.js SDK
https://docs.thinkwithwp.com/AWSJavaScriptSDK/latest/AWS/RDS.html