亚马逊AWS官方博客
使用 AWS Glue 蓝图将数据库中的数据大规模登陆到数据湖
Original URL: https://thinkwithwp.com/blogs/big-data/land-data-from-databases-to-a-data-lake-at-scale-using-aws-glue-blueprints/
- ETL 作业逻辑 – 我们使用 AWS Glue 蓝图,它允许您为多个具有相同逻辑的作业重复使用一个蓝图
- 作业定义 – 我们使用 JSON 文件,因此您无需学习新语言即可通过编程方式定义作业
- 作业部署 – 使用 AWS Step Functions,您可以复制工作流以在 AWS Glue 上管理不同的数据处理使用案例
在本博文中,您将通过维护一个包含表名和几个参数(例如,工作流目录)的 JSON 文件,学习如何以标准化方式处理数据湖登陆作业部署。AWS Glue 工作流是在 Step Functions 中手动运行资源部署流程后创建和更新的。您可以进一步自定义 AWS Glue 蓝图,创建自己的多步骤数据管道,将数据移动到下游层和专用的分析服务(示例使用案例包括分区或导入到 Amazon DynamoDB 表)。
解决方案概览
下图展示了该解决方案的架构,其中包含两个主要领域:
- 资源部署(组件 1–2)– AWS Step Functions 工作流可根据需要手动运行,以更新或部署所需的 AWS Glue 资源。这些 AWS Glue 资源用于将数据登陆到数据湖中
- ETL 作业运行(组件 3–6)– AWS Glue 工作流(每个源表一个)按定义的时间表运行,提取数据并将其登陆到数据湖原始层
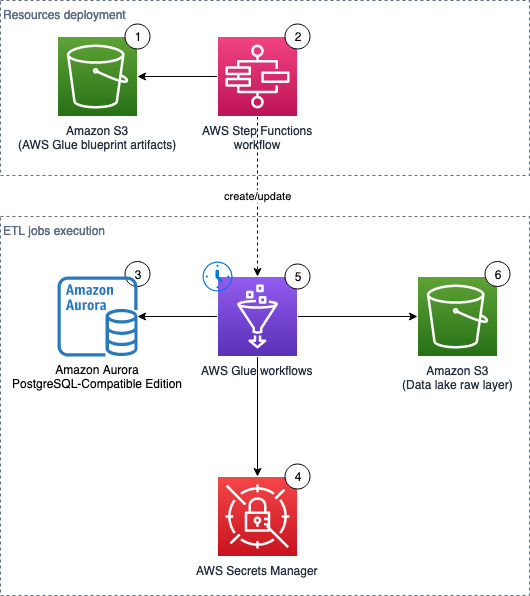
我们的解决方案工作流包含以下步骤:
- S3 存储桶存储 AWS Glue 蓝图(ZIP)和工作流目录(JSON 文件)。
- Step Functions 工作流负责编排 AWS Glue 资源的创建。
- 我们使用 Amazon Aurora 作为示例数据的数据来源,但任何 PostgreSQL 数据库都使用提供的脚本,或者使用其他自定义的 JDBC 源。
- AWS Secrets Manager 存储源数据库的密钥。
- 按照预定义的计划,AWS Glue 会触发相关的 AWS Glue 作业来执行 ETL。
- 提取的数据加载到 S3 存储桶中,该存储桶作为数据湖的原始层。
先决条件
要继续完成这篇博客,请完成以下先决条件步骤。

- 如果您使用 AWS 中或本地的现有数据库作为数据来源,您需要用于 AWS Glue 的网络连接(子网和安全组),该连接可以访问源数据库、Amazon S3 和 Secrets Manager。
使用 AWS CloudFormation 预置资源
在此步骤中,我们使用 AWS CloudFormation 预置解决方案资源。
包含示例数据的数据库(可选)
此 CloudFormation 堆栈仅适用于支持 Amazon Aurora Serverless v1 的 AWS 区域。完成以下步骤以创建带有示例数据的数据库:
- 选择 Launch Stack(启动堆栈)。

- 在 Create stack(创建堆栈)页面上,选择 Next(下一步)。
- 对于 Stack name(堆栈名称),输入
demo-database。 - 对于 DBSecurityGroup,选择数据库的安全组(例如,
default)。 - 对于 DBSubnet,选择两个或更多私有子网来托管数据库。
- 对于 ETLAZ,请为 ETL 作业选择可用区。它必须与
ETLSubnet相匹配。 - 对于 ETLSubnet,请选择作业的子网。这必须与
ETLAZ相匹配。
要查找子网和相应的可用区,请转到 Amazon Virtual Private Cloud(Amazon VPC)控制台并查看 Subnet ID(子网 ID)和 Availability Zone(可用区)列。
- 选择 Next(下一步)。
- 在 Configure stack options(配置堆栈选项)页面上,跳过输入并选择 Next(下一步)。
- 在 Review(审核)页面上,选择 Create Stack(创建堆栈)。
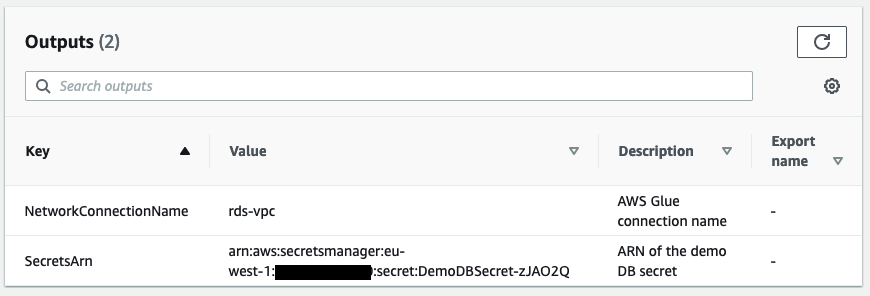
- 堆栈完成后,转到 Outputs(输出)选项卡并记下
SecretsARN的值。
此 CloudFormation 堆栈创建以下资源:
- Amazon Aurora PostgreSQL 兼容版(无服务器 v1,引擎版本 11.13)数据库
- Secrets Manager 密钥(
DemoDBSecret)将连接详细信息存储到源数据库 - 可以与源数据库和 Amazon S3 通信的 AWS Glue 网络连接(
rds_vpc)
现在,您可以使用示例数据填充数据库。数据是通过引用示例 HR 架构生成的。
- 打开 Amazon RDS 查询编辑器。
- 在 Connect to database(连接到数据库)部分中,提供以下信息:
- 对于 Database instance(数据库实例),输入
demo-<123456789012>。 - 对于 Database username(数据库用户名),选择 Connect with a Secrets Manager ARN(使用 Secrets Manager ARN 连接)。
- 对于 Secrets Manager ARN,输入 CloudFormation 堆栈的输出中的 ARN。
- 对于 Database name(数据库名称),输入
hr。
- 对于 Database instance(数据库实例),输入
- 单击 Connect to database(连接到数据库)。
- 在编辑器中输入 SQL 文件的内容,然后选择 Run(运行)。
主堆栈(必需)
此 CloudFormation 堆栈可用于所有 AWS 区域。
- 选择 Launch Stack(启动堆栈)。
- 在 Create stack(创建堆栈)页面上,选择 Next(下一步)。
- 对于 Stack name(堆栈名称),输入
data-lake-landing。 - 对于 BlueprintName(蓝图名称),输入蓝图的名称(默认值:
data-lake-landing)。 - 对于 S3BucketNamePrefix(S3 存储桶名称前缀),输入前缀(默认值:
data-lake-raw-layer)。 - 选择 Next(下一步)。
- 在 Configure stack options(配置堆栈选项)页面上,跳过输入并选择 Next(下一步)。
- 在 Review(审核)页面上,选择 I acknowledge that AWS CloudFormation might create IAM resources with custom names(我确认 AWS CloudFormation 可能会使用自定义名称创建 IAM 资源)。
- 单击 Create stack(创建堆栈)。
- 堆栈完成后,转到 Outputs(输出)选项卡并记下 S3 存储桶(例如
data-lake-raw-layer-123456789012-region)和 Step Functions 工作流(例如,data-lake-landing)的名称。

CloudFormation 堆栈创建以下资源:
- 作为数据湖原始层的 S3 存储桶
- Step Functions 工作流(参见 GitHub 存储库中的定义)
- Step Functions 的 Amazon Identity and Access Management(IAM)角色和策略,用于预置 AWS Glue 资源和 AWS Glue 作业执行。
GlueExecutionRole 限制为 Secrets Manager 中的 DemoDBSecret。如果您需要连接到具有不同端点/地址或凭证的其他数据库,请不要忘记创建新密钥并向 IAM 角色或密钥授予额外权限,这样您的 AWS Glue 作业就可以对源数据库进行身份验证。
准备数据库连接
如果您想使用此解决方案对现有数据库执行 ETL,请按照这部分中的说明操作。否则,如果您已使用示例数据为数据库部署了 CloudFormation 堆栈,请跳转至“编辑工作流目录”部分。
您需要准备好一个正在运行的 PostgreSQL 数据库。要连接到其他数据库引擎,您需要自定义此解决方案,尤其是提供的 PySpark 脚本中的 jdbcUrl。
创建数据库密钥
要创建 Secrets Manager 密钥,请完成以下步骤:
- 在 Secrets Manager 控制台中,选择 Store a new secret(存储新密钥)。
- 对于 Secret type(密钥类型),选择 Credentials for Amazon RDS database(Amazon RDS 数据库的凭证)或 Credentials for other database(其他数据库的凭证)。
- 在 Credentials(凭证)中,输入数据库的用户名和密码。
- 对于 Encryption key(加密密钥),请保留默认值 AWS Key Management Service(AWS KMS)管理的密钥
aws/secretsmanager。 - 对于 Database(数据库),选择数据库实例,或手动输入引擎、服务器地址、数据库名称和端口。
- 选择 Next(下一步)。
- 对于 Secret name(密钥名称),输入您的密钥的名称(例如,
rds-secrets)。 - 选择 Next(下一步)。
- 跳过 Configure rotation – optional(配置轮换 – 可选)页面,然后选择 Next(下一步)。
- 查看摘要并选择 Store(存储)。
创建 AWS Glue 连接
要创建 AWS Glue 连接,请完成以下步骤:
- 在 AWS Glue Studio 控制台上,选择 Connectors(连接器)。
- 在 Connections(连接)下,选择 Create connection(创建连接)。
- 对于 Name(名称),输入名称(例如,
rds-vpc)。 - 对于 Connection type(连接类型),选择 Network(网络)。
- 对于 VPC、子网和安全组(在先决条件步骤中准备),输入运行 ETL 作业并且能够连接到源数据库、Amazon S3 和 Secrets Manager 的位置。
- 单击 Create connection(创建连接)。
现在,您可以配置解决方案的其余部分了。
编辑工作流目录
要下载工作流目录,请完成以下步骤:
- 下载并编辑示例文件。
- 如果您使用所提供的示例数据库,则必须更改
GlueExecutionRole和DestinationBucketName的值。如果您使用自己的数据库,则必须更改除WorkflowName、JobScheduleType和ScheduleCronPattern之外的所有值。
- 将文件重命名为
your_blueprint_name.json,然后将其上传到 S3 存储桶(例如,s3://data-lake-raw-layer-123456789012-eu-west-1/data-lake-landing.json)。
示例工作流将 JobScheduleType 设置为 Cron。有关设置 cron 模式的示例,请参阅用于作业和爬网程序的基于时间的计划。或者,将 JobScheduleType 设置为 OnDemand。
有关参数的完整列表,请参阅 blueprint.cfg。
提供的工作流目录 JSON 文件包含七个表的作业定义:public.regions、public.countries、public.locations、public.departments、public.jobs、public.employees 和 public.job_history。
查看 PySpark 脚本(可选)
示例脚本执行以下任务:
- 从源表中读取更新的记录:
jdbc_df = (spark.read.format("jdbc")
.option("url", jdbcUrl)
.option("user", secret["username"])
.option("password", secret["password"])
.option("query", sql_query)
.load()
)- 添加日期和时间戳列:
df_withdate = jdbc_df.withColumn("ingestion_timestamp", lit(current_timestamp()))- 将 DataFrame 以 Parquet 文件格式写入 Amazon S3。
准备 AWS Glue 蓝图
使用以下步骤准备您的 AWS Glue 蓝图:
- 下载示例文件并将其解压缩到本地计算机。
- 对 PySpark 脚本进行任何必要的更改以包含您自己的逻辑,然后将三个文件(
blueprint.cfg、jdbc_to_s3.py、layout.py,不含任何文件夹)压缩为your_blueprint_name.zip(例如,data-lake-landing.zip):
- 上传到 S3 存储桶(例如,
s3://data-lake-raw-layer-123456789012-region/data-lake-landing.zip)。
现在,您应该已经将两个文件上传到 S3 存储桶中。

运行 Step Functions 工作流以部署 AWS Glue 资源
要运行 Step Functions 工作流,请完成以下步骤:
- 在 Step Functions 控制台上,选择您的状态机(
data-lake-landing),然后选择 View details(查看详细信息)。 - 选择 Start execution(开始执行)。
- 保留弹出窗口中的默认值。
- 选择 Start execution(开始执行)。
- 等到底部的 Success(成功)步骤变为绿色。
一些中间步骤的状态为 Caught error(捕获错误)是正常的。

当工作流目录包含大量 ETL 作业条目时,可能会出现一些延迟。在我们的测试环境中,在干净状态下创建 100 个作业大约需要 22 分钟;第二次运行(删除现有 AWS Glue 资源并创建 100 个作业)可能需要大约 27 分钟。
验证 AWS Glue 中的工作流
要检查工作流,请完成以下步骤:
- 在 AWS Glue 控制台上,选择 Workflows(工作流)。
- 验证是否列出了
workflow_config.json中定义的所有 AWS Glue 工作流。 - 选择其中一个工作流,然后在 Action(操作)菜单上选择 Run(运行)。
- 等待大约 3 分钟(如果不使用提供的带有示例数据的数据库,则会等待更长时间),然后在 Amazon S3 控制台上验证您的数据湖中是否创建了新的 Parquet 文件(例如,
s3://data-lake-raw-layer-123456789012-region/database/table/ingestion_date=yyyy-mm-dd/)。

Step Functions 工作流概述
本节介绍了 Step Functions 工作流中的主要步骤。
注册 AWS Glue 蓝图
蓝图允许您对工作流进行参数化(定义作业和爬网程序),然后生成重用相同代码逻辑的多个 AWS Glue 工作流程,用于处理相似的数据 ETL 活动。下图说明了 Step Functions 工作流的 AWS Glue 蓝图注册部分。

步骤 Glue: CreateBlueprint 在 Amazon S3(示例)中获取 ZIP 存档并将其注册以备后用。
要了解如何开发蓝图,请参阅 AWS Glue 中的蓝图开发。
解析工作流目录并清理资源
步骤 S3: ParseGlueWorkflowsConfig 触发以下 Map 状态,并为输入数组的每个元素运行一组步骤。

我们将最大并发数设置为五个并行迭代,以降低超过允许的 API 最大请求速率(每个区域的每个账户)的几率。对于每个 ETL 作业定义,Step Functions 工作流会清理相关的 AWS Glue 资源(如果存在),包括工作流、作业和触发器。
有关 Map 状态的更多信息,请参阅 Map 。
运行 AWS Glue 蓝图
在 Map 状态中,步骤 Glue: CreateWorkflowFromBlueprint 启动一个异步进程,用于创建 AWS Glue 工作流(针对每个作业定义)以及该工作流封装的作业和触发器。

在此解决方案中,所有 AWS Glue 工作流共享相同的逻辑,首先是用于处理计划的触发器,然后是运行 ETL 逻辑的作业。
正如 CreateWorkflowFailed 步骤所示,任何 AWS Glue 蓝图创建失败都会停止整个 Step Functions 工作流并将其标记为失败状态。请注意,不会发生回滚。修复错误并重新运行 Step Functions 工作流。这不会导致重复的 AWS Glue 资源,现有资源将在此过程中被清理。
限制
请注意此解决方案的以下限制:
- 每次运行 Step Functions 工作流都会删除在工作流目录中定义的所有相关 AWS Glue 作业,并创建带有不同(随机)后缀的新作业。因此,您将丢失 AWS Glue 中的作业运行历史记录。基础指标和日志保留在 Amazon CloudWatch 中。
清理
为避免将来产生费用,请执行以下步骤:
- 禁用已部署 AWS Glue 作业的计划:
- 打开 S3 存储桶(
s3://data-lake-raw-layer-123456789012-eu-west-1/data-lake-landing.json)中的工作负载配置文件,然后将所有工作流程定义的JobScheduleType值替换为OnDemand。 - 运行 Step Functions 工作流(
data-lake-landing)。 - 请注意,所有以
_starting_trigger结尾的 AWS Glue 触发器的触发器类型均为 On-demand(按需)而不是 Schedule(计划)。
- 打开 S3 存储桶(
- 清空 S3 存储桶并删除 CloudFormation 堆栈。
- 删除已部署的 AWS Glue 资源:
- 所有 AWS Glue 触发器以
_starting_trigger结尾。 - 所有 AWS Glue 作业以工作流目录中定义的
WorkflowName开头。 - 所有 AWS Glue 工作流以工作流目录中定义的
WorkflowName开头。 - AWS Glue 蓝图。
- 所有 AWS Glue 触发器以
结论
AWS Glue 蓝图允许数据工程师构建和维护 AWS Glue 作业,将数据从 RDBMS 大规模登陆到您的数据湖。采用这种标准化的可重复使用方法后,您现在无需维护数百个 AWS Glue 作业,而是只需跟踪工作流目录。当您有新表要登陆到数据湖时,只需将条目添加到工作流目录中,然后重新运行 Step Functions 工作流即可部署资源。
我们强烈建议您为多步骤数据管道自定义蓝图(例如,检测和处理敏感数据),并将其提供给您的组织和 AWS Glue 社区。要开始使用,请参阅使用 AWS Glue 中的蓝图和工作流执行复杂的 ETL 活动以及 GitHub 上的示例蓝图。如果您有任何问题,请发表评论。
关于作者
 Moustafa Mahmoud 是 AWS Data Lab 的解决方案架构师,对数据集成、数据分析、机器学习和 BI 充满热情。Moustafa 帮助客户将他们的想法转化为 AWS 上的生产就绪型数据产品。他拥有超过 10 年的数据工程师、机器学习从业者和软件开发经验。在业余时间,Moustafa 喜欢探索大自然、阅读以及与朋友和家人共度时光。
Moustafa Mahmoud 是 AWS Data Lab 的解决方案架构师,对数据集成、数据分析、机器学习和 BI 充满热情。Moustafa 帮助客户将他们的想法转化为 AWS 上的生产就绪型数据产品。他拥有超过 10 年的数据工程师、机器学习从业者和软件开发经验。在业余时间,Moustafa 喜欢探索大自然、阅读以及与朋友和家人共度时光。
 Corvus Lee 是 AWS Data Lab 的解决方案架构师。他喜欢参加各种与数据相关的讨论,并帮助客户使用 AWS 数据库、分析和机器学习服务构建 MVP。
Corvus Lee 是 AWS Data Lab 的解决方案架构师。他喜欢参加各种与数据相关的讨论,并帮助客户使用 AWS 数据库、分析和机器学习服务构建 MVP。