亚马逊AWS官方博客
Amazon Kinesis Data Analytics 无服务器流式数据处理服务简介
–写在Amazon Kinesis Data Analytics在中国区发布之际
1. 流式数据分析简介
流处理技术源于企业的实际需求,这些企业经历了数据量、数据产生速度和数据种类的巨大增长,并且迫切需要快速摄取和评估这些数据来进行业务决策。
与传统系统的批处理模式(“静态数据”)相比,处理和分析“运动”中数据的能力已是企业间的关键差异因素之一。尤其在企业进行数字化转型的今天,企业迫切需要对当下正在发生的事情进行分析的需求,而不是对昨天或上个月发生的事情进行分析。因此流式数据对企业越来越重要,因为它能让企业具有竞争优势。事件发生后,当下的见解会立即变得有价值,随着时间的流逝其价值会迅速下降。
从物联网、金融、网络安全到零售,实时分析、行动能力已经成为多个领域SLA的关键要素,企业正在将流式数据与数据处理引擎和框架结合在一起来创建流数据应用程序。这类名词有很多,实时分析、流分析、复杂事件处理(CEP)、实时流分析和事件处理等。

图一 : 数据的价值随着时间的推移而减少
引自: Perishable insights, Mike Gualtieri, Forrester
谈到流式处理,很多企业首先就想到一些单一的流式处理组件,诸如Flink、Nifi等。但是这并没有从全链路实现流式应该做哪些规划、准备的角度进行思考,在《2020 Planning Guide for Data Management》报告中, Gartner给出了一个很好的流数据处理的全链路参考架构和推荐组件,我们应该结合各自企业现在的场景或者未来可能遇到的挑战进行架构设计和组件选择,尽量选择相对成熟的组件和技术,降低风险以及使用和运维成本。Amazon Kinesis Data Analytics就是其中流式处理分析的推荐组件之一。
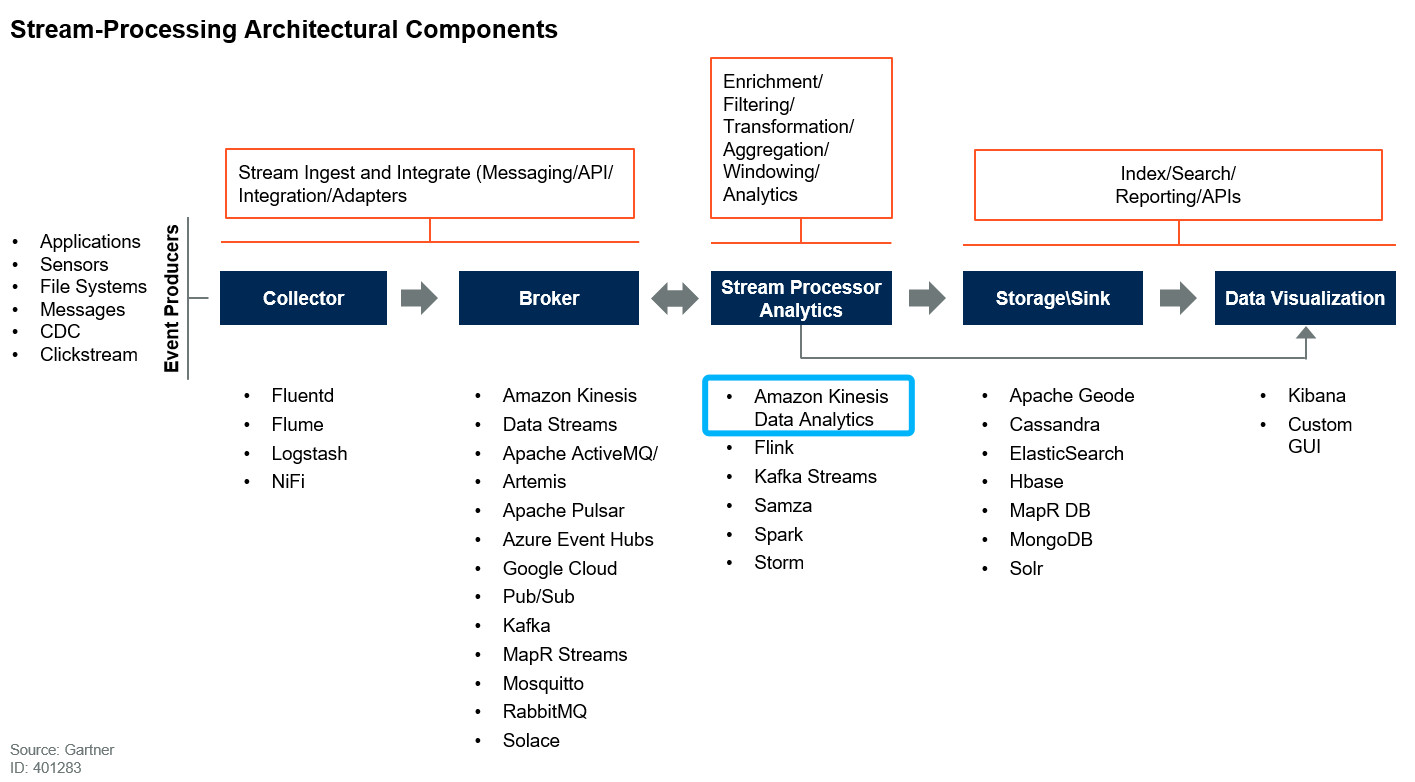
图二: Stream-Processing Architectural Components
(引自: https://www.gartner.com/en/documents/3970129/2020-planning-guide-for-data-management)
2. Amazon Kinesis Data Analytics简介及应用场景
Amazon Kinesis 是完全托管的云服务,用于对大型分布式数据流进行实时数据处理。Kinesis Data Streams可以捕获、处理和存储数据流,Kinesis Data Firehose将数据流加载到 AWS 数据存储、分析工具中(如S3、redshift、Elasticsearch),Kinesis Data Analytics使用 SQL 或 Java 分析数据流,可以提供亚秒级的端到端处理延迟。这三者可以高效的配合使用,提供完整的流式数据处理服务。Kinesis服务属于无服务器产品,不需要设置和管理复杂的基础设施,且会自动扩展以匹配传入数据的大小和吞吐量。使用时只需要为流应用程序消耗付费,没有最低消费和设置费用。
使用 Kinesis Data Analytics可以非常简便地分析流数据、获得对数据的洞察,对于没有编程经验的业务人员可通过SQL模板和交互式 SQL 编辑器快速实现业务目标,可针对各类应用场景,定义相应的计算规则,轻松查询流数据或构建整个流应用程序。对经验丰富的Java 开发人员可以使用开源 Java 库和 AWS 集成快速构建复杂的流应用程序,以转换和实时分析数据,而不用维护实时数据分析系统。
对于Kinesis Data Analytics来说,常见的三类应用是:
- 流式 ETL(数据管道)
- 持续指标生成
- 事件驱动型应用(实时响应分析)
2.1 流式 ETL(数据管道)
流式 ETL数据管道是以持续流模式运行,而非周期性触发,可以从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如:您可以连续读取存储在 Amazon Managed Streaming for Apache Kafka中的 IoT 传感器数据,按传感器类型组织数据,删除重复数据,按照指定架构规范化数据,然后将数据交付到 Amazon S3。
另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。您能够在加载数据仓库之前实时清理、扩充、组织和转换原始数据,减少或消除批处理 ETL 步骤。
例如下面链接中的说明,您具有一个可接收两种类型 (Order 和 Trade) 记录的流式传输源SOURCE_ STREAM,通过KDA将订单记录,并将订单保存到 Order_Stream,将Trade记录保存到Trade_Stream,并计算时长一分钟的滚动窗口中交易数,并将结果保存到另一个流 DESTINATION_ STREAM。
https://docs.thinkwithwp.com/zh_cn/kinesisanalytics/latest/dev/app-tworecordtypes.html
2.2 持续指标生成
借助持续指标生成应用程序,您可以监控和了解您的数据在一段时间内的趋势。您的应用程序可以将流数据聚合为关键信息,并将其与报表数据库和监测服务无缝集成,从而实时地为您的应用程序和用户服务。借助 Kinesis Data Analytics,您可以使用 SQL 或 Java 代码在一段时间内持续生成时间序列分析。例如,您可以通过计算每分钟的顶级玩家并将结果发送至 Amazon DynamoDB 来创建手机游戏的实时排行榜。或者,您可以每五分钟计算一次唯一身份网站访客的数量并将处理结果发送至 Amazon Redshift 来跟踪网站的流量。类似的应用还有网络质量监控、对消费者的实时数据即席分析等。下面就是两个应用的例子:
Gunosy是一个手机新闻阅读应用,他使用Amazon Kinesis Data Analytics、Amazon Kinesis Data Firehose实时处理用户活动日志,分析用户属性,例如性别和年龄,以及过去的活动日志,例如点击率(CTR)。并将此信息与文章属性结合起来,为用户提供趋势,个性化的新闻文章。
https://thinkwithwp.com/blogs/big-data/optimize-delivery-of-trending-personalized-news-using-amazon-kinesis-and-related-services/
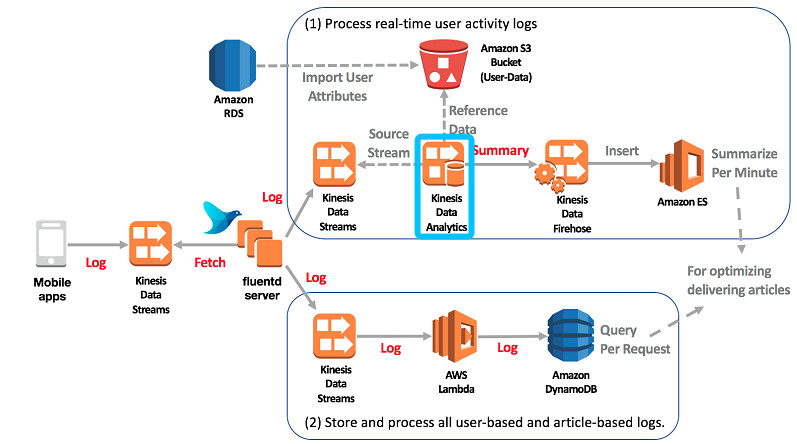
图三: Amazon Kinesis Analytics architecture at Gunosy
Palringo是聊天和游戏的结合应用程序开发商,使用Amazon Kinesis Analytics实时处理用户活动并将这些统计信息提供给客户来提高其应用参与度。客户可以更好地查看群聊统计信息,例如按类型随时间推移发送的消息数或总消息数。此外,关于哪些游戏在哪个聊天组中以及哪个组最活跃的内部度量标准为产品经理和游戏开发人员提供了更好的见解,从而增加了游戏的采用率和游戏时间。详见:https://thinkwithwp.com/solutions/case-studies/palringo/

图四: Amazon Kinesis Analytics architecture at Palringo
下面这个blog则介绍了使用Kinesis Data Analytics和QuickSight生成IOT设备仪表盘的方案,使用Kinesis Data Analytics编写 SQL查询,从传入的数据流中提取特定的数据并对其执行实时ETL,来汇总每分钟传感器的最低和最高温度值,之后将其加载到Amazon QuickSight中创建监视仪表板,来检查设备在使用过程中是否过热或冷却。还可以在分析中提取每个设备的位置、温度、湿度和时间等参数,以在可视化仪表板上展示。
2.3 事件驱动型应用(实时响应分析)
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。实时响应分析应用程序在某些指标达到预定义阈值时(或者更超前的情况是,在您的应用程序使用机器学习算法检测到异常情况时)发送实时警报或通知。这些应用程序让您能够即刻对业务变化做出响应,例如,预测移动应用的用户弃用趋势,以及识别降级系统。典型的事件驱动型应用有异常检测、反欺诈、基于规则的报警、业务流程监控等。下面就是几个应用的例子:
Autodesk是3D设计和工程软件的开发商,为确保确保其数百万的全球用户具有运行该软件的最佳体验,Autodesk在AWS上构建统一日志分析解决方案,目的是改善软件产品并为客户提供更好的服务。Kinesis Data Analytics用于发现实时监控指标,例如响应时间和错误率峰值。日志数据通过此管道后,将被发送到Amazon CloudWatch,显示在整个企业的标准化仪表板中。https://thinkwithwp.com/solutions/case-studies/autodesk-log-analytics/

图五: Amazon Kinesis Analytics architecture at Autodesk
数字营销人员需要监控点阅率以了解特定广告的效果,从而优化广告的展示位置。他们还对低点击率异常感兴趣,这个blog就给出了使用Kinesis Data Analytics进行实时分析点击流数据分析,并进行异常检测的说明,其中就使用了Kinesis Data Analytics内置的RANDOM_CUT_FOREST函数。
https://thinkwithwp.com/cn/blogs/big-data/real-time-clickstream-anomaly-detection-with-amazon-kinesis-analytics/

图六: Real-time Clickstream Anomaly Detection with Amazon Kinesis Analytics
在出租车车队的实时数据分析的案例中,通过构建可扩展且高度可用的流式架构来优化车队运营,当识别当前存在大量打车请求的区域时,就会将信息实时展现在企业运营仪表盘上,其中使用Kinesis Data Analytics for Java Applications 部署、操作和扩展 Flink 应用程序。
2.4 总结
下表从行业的维度给出一些典型应用的总结,Amazon Kinesis系列服务可以很好的满足这些需求。
| 行业 | 实时分析 | 近实时分析 | |
| 持续指标生成 | 实时响应分析 | 流式 ETL | |
| 广告和营销 | 广告覆盖率,收益率和转化率等指标 | 用户与广告互动,优化出价/购买引擎 | 发布者、投标者数据汇总 |
| IOT | 运作指标和仪表板 | 设备操作智能和警报(OTA车辆管理) | 传感器,设备遥测,数据摄取 |
| 游戏 | 大型多人在线游戏(MMOG)实时仪表板 | 排行榜,玩家技能匹配 | 在线数据汇总; 例如,前10名玩家 |
| 在线门户、电商 | 页面浏览量之类的指标 | 推荐引擎,A/B测试 | 点击流分析 |
| 运营监控 | 订阅Amazon CloudWatch日志并实时分析日志 | 异常检测 | 提取VPC流日志 |
3. 构建流式数据分析平台的考虑
在《2020 Planning Guide for Data Management》报告中, Gartner还给出了构建流数据平台需要考虑的因素,其中包括:
- 以敏捷的方式构建
- 协调数据
- 流数据质量和排序
- 故障恢复
- 动态扩展
- 减少延迟
这些因素在Kinesis Data Analytics服务中都有体现,说明如下:
(引自: https://www.gartner.com/en/documents/3970129/2020-planning-guide-for-data-management)
3.1 以敏捷的方式构建
“以敏捷的方式构建流处理管道,从而可以动态添加新的源和目标。考虑使用带有内置警报,监视和元数据管理支持的流水线和编排平台。”
这一点,Kinesis 服务和其他AWS服务一样都得到了很好的实现。利用 CloudFormation/AWS CDK 实现 AWS 资源编排可以将基础架构通过代码来管理,以安全且可重复的方式来部署 Kinesis Data Analytics 应用程序;
监控是保持Kinesis Data Analytics应用程序的可靠性、可用性和性能的重要组成部分。可以使用Cloudwatch来监控 Amazon Kinesis Data Analytics,并使用 CloudWatch Logs Insights 查询日志流以查找特定的事件或错误;
CloudTrail 可以将 Kinesis Data Analytics 的所有 API 调用作为事件捕获。通过使用 CloudTrail 收集的信息,可以确定向 Kinesis Data Analytics 发出了什么请求、发出请求的 IP 地址、何人发出的请求、请求的发出时间以及其他详细信息。
3.2 协调数据
“由于源系统可能有不同的数据格式,因此需要将数据统一为通用格式。可以将源数据转换为CSV文件,然后进一步将其优化为列格式,例如Apache ORC和Apache Parquet。”
在 Kinesis Data Analytics 中,可以使用AWS Lambda 函数预处理数据,将记录从其他格式(如 KPL 或 GZIP)转换为 JSON 或 CSV 数据格式。进一步还可以利用其他 AWS 服务进行数据扩充,包括使用S3中的数据丰富Stream数据。
3.3 流数据质量和排序
“提取管道需要考虑到迟到的数据和缺失值。还需要数据分析以识别敏感数据并应用公司策略。”
Kinesis Data Analytics 的应用程序内部流包含名为 ROWTIME 的特殊列。ROWTIME 反映的时间戳是指Amazon Kinesis Data Analytics 从流式传输源中读取后将记录插入到第一个应用程序内部流的时间。除了 ROWTIME 之外,在实时流式应用程序中还存在事件时间、接收时间、处理时间。对于基于时间的窗口式查询,可以选择上述时间戳。同时Kinesis Data Analytics 支持滚动窗口方式、滑动窗口方式还是交错窗口方式处理记录。交错窗口可以减少延迟或无序数据。
3.4 故障恢复
“通过确保在发生故障时可恢复状态来保持操作的原子性。如果摄取和负载是由不同的管道执行的,则需要恢复两者之间的数据流。需要对到达数据(可查询实时分析)进行隔离,以隔离从下游策展数据存储中缓存的数据。”
Kinesis Data Analytics 在无服务器模式中运行,通过执行自动迁移来处理主机降级、可用区可用性以及其他与基础设施相关的问题。同时,Kinesis Data Analytics 使用检查点checkpoints和快照snapshots来自动备份运行应用程序的状态。检查点是用于在 Amazon Kinesis Data Analytics for Java Applications 中实施容错功能的方法。检查点是运行的应用程序的最新备份,用于从意外的应用程序中断或故障转移中恢复。快照是手动创建和管理的应用程序状态备份。通过使用快照,可以调用 UpdateApplication 将应用程序还原到以前的状态。
3.5 动态扩展
“动态扩展以适应源和汇数量的增加。因此,当负载减少时,请按比例缩小资源。研究允许自动缩放以保持最佳吞吐量以保留所需延迟的产品。”
Kinesis Data Analytics 可对应用程序进行弹性扩展,以适应数据吞吐量和查询复杂性。您仅需为运行您的流式处理应用程序所使用的资源付费,无需担心预置基础设施,也无需为空闲容量付费。Kinesis Data Analytics 以 Amazon Kinesis 处理单元 (KPU) 的形式预置容量。一个 KPU 为您提供 1 个 vCPU 和 4GB 内存。
对于 Java 应用程序可以使用 API 中的 Parallelism 和 ParallelismPerKPU 参数,控制用于 Kinesis Data Analytics 的 Java 应用程序任务(例如从源中读取或执行运算符)的并行执行。Parallelism 使用该属性设置Apache Flink 应用程序并行度。所有操作符、源和接收器以该并行度执行。ParallelismPerKPU 使用该属性设置应用程序的每个KPU的并行任务数。
对于 SQL 应用程序可以指定输入并行机制参数来增加源映射到的应用程序内部流的数量,从而以更高效的方式使用 KPU。
3.6 减少延迟
“利用临时存储(缓存),并通过将数据缓存在本地区域来应对数据量意外增加的情况。”
Amazon Kinesis Data Analytics 提供亚秒级处理延迟,可以高效的进行流式数据分析。
4. 总结
Amazon Kinesis流式数据处理服务凭借强大的实时处理功能、无需预置或管理任何基础设施、按实际用量付费这些特点,可以帮助企业快速构建流式数据处理、分析平台,获得对企业业务运营的洞察,并帮助企业实时响应业务和客户的需求,加速企业的数字化转型。