亚马逊AWS官方博客
推出 Amazon Redshift Serverless – 能以任何规模运行分析,而无需管理数据仓库基础设施
我们看到,组织内的新受众(例如,开发人员和业务线分析师等没有专业知识或时间来管理传统数据仓库的用户)正在越来越多地使用数据分析。此外,一些客户的工作负载不断变化且无法预测峰值,因此他们很难对容量进行持续管理。
借助 Amazon Redshift,您可以使用 SQL 跨数据仓库、运营数据库和数据湖分析结构化和半结构化数据。今天,我很高兴向大家介绍 Amazon Redshift Serverless 的公开预览版,这是一项新功能,让您能够轻松地在云中以任何规模高性能地运行分析。只需加载数据然后开始查询即可。无需设置和管理集群。您需要为使用数据仓库的时长(以秒为单位)付费,例如,在查询或加载数据时。数据仓库空闲时不收取任何费用。
Amazon Redshift Serverless 会自动为您预置合适的计算资源,以便您开始使用。您的需求会随着并发用户的增加以及新工作负载的变化而变化,与此同时,您的数据仓库也会无缝自动扩展以适应变化。您可以根据需要指定基础数据仓库的大小,以进一步控制成本和特定于应用程序的 SLA。
借助新的无服务器选项,您可以继续查询其他 AWS 数据存储中的数据,例如 Amazon Simple Storage Service (Amazon S3) 数据湖以及 Amazon Aurora 和 Amazon Relational Database Service (RDS) 数据库。
Amazon Redshift Serverless 是非常适合难以预测计算需求的情况,例如可变工作负载、具有空闲时间的周期性工作负载以及具有峰值的稳态工作负载。这种方法也非常适合需要快速入门的临时分析需求以及测试和开发环境。
我们来看看该方法的实际应用。
使用 Amazon Redshift Serverless
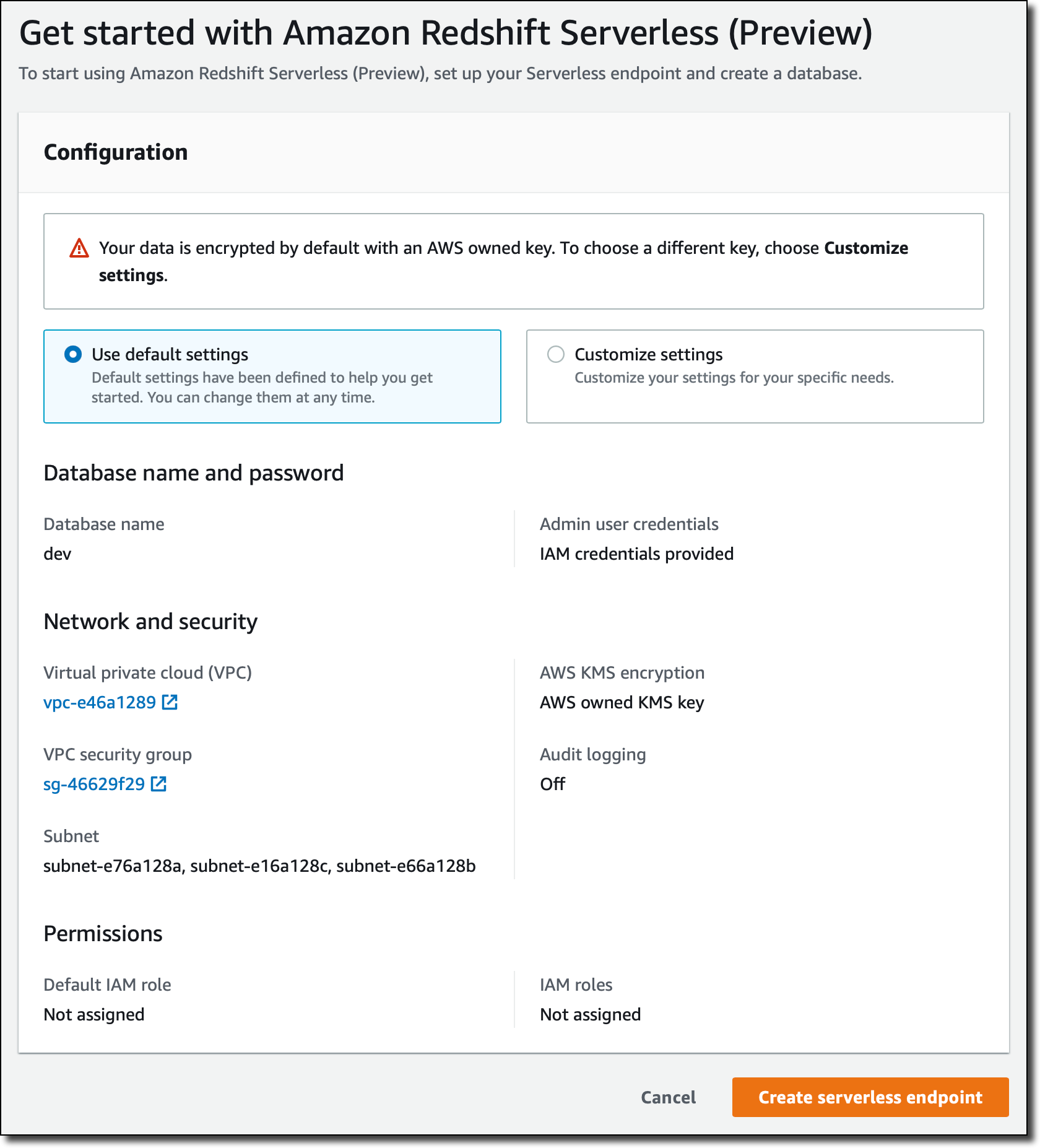
转到 Amazon Redshift 控制台,然后选择新的无服务器选项。第一次,我设置了无服务器端点并对网络和安全性进行了配置。
我确认使用默认 Amazon Virtual Private Cloud (VPC) 及其默认安全组中所有子网的默认设置。数据始终保持加密,我使用默认的 AWS 自有密钥。或者,我可以自定义所有设置。我可以立即或稍后关联 AWS Identity and Access Management (IAM) 角色,以授予访问其他 AWS 资源的权限(例如,能够从 S3 存储桶加载数据)。无服务器端点的配置将由我在同一 AWS 账户和区域中的所有无服务器数据仓库共享。
为了查询数据,我使用了 Amazon Redshift 查询编辑器 V2,这是我们几个月前推出的一款新的基于 Web 的免费工具。该查询编辑器提供对一些示例数据集的快速访问功能,以便轻松学习 Amazon Redshift 的 SQL 功能:TPC-H、TPC-DS 和 tickit(一个包含活动门票销售信息的数据集)。
为了快速进行测试,我使用了 tickit 示例数据集,因此我不需要加载任何数据。我准备了一个查询来获取每个日期售出的门票列表,并按销量由高到低的顺序为日期排序:
SELECT caldate, sum(qtysold) as sumsold
FROM tickit.sales, tickit.date
WHERE sales.dateid = date.dateid
GROUP BY caldate
ORDER BY sumsold DESC;通过使用基于 Web 的查询编辑器,我不需要配置 SQL 客户端或设置网络权限来访问无服务器端点。相反,我只需要编写 SQL 查询并运行它。

我是一个视觉化的人。我启用结果表右侧的图表选项并选择了一个条形图。

我对图表的清晰度感到满意,并将其导出为图像文件。通过这种方式,我可以快速共享它或将它包含在报告中。

Amazon Redshift Serverless 支持 Amazon Redshift 的所有丰富的 SQL 功能,例如半结构化数据支持。我可以使用任何兼容 JDBC/ODBC 的工具或 Amazon Redshift Data API 来查询我的数据。要迁移数据,我可以拍摄 Amazon Redshift 预置集群的快照并将其恢复为无服务器架构。然后,我只需要更新我的 SQL 应用程序即可使用新的无服务器端点。
可用性和定价
Amazon Redshift Serverless 现已在以下 AWS 区域推出公开预览版:美国东部(弗吉尼亚北部)、美国西部(加利福尼亚北部、俄勒冈)、欧洲(法兰克福、爱尔兰)、亚太地区(东京)。
使用 Amazon Redshift Serverless 时,您需要为使用的计算和存储服务单独付费。计算容量以 Redshift 处理单元 (RPU) 为单位,您可以按 RPU 小时为工作负载付费,并按秒计费。对于存储,您需要为存储在 Amazon Redshift 托管的存储空间以及用于快照的存储空间中的数据付费,这与为使用 RA3 实例的预置集群支付的费用类似。
为了控制成本,您可以指定使用限制并定义 Amazon Redshift 在达到这些限制时自动采取的操作。您可以以 RPU 小时为单位指定使用限制,并将其与每日、每周或每月的持续时间相关联。设置更高的使用限制可以提高系统的整体吞吐量,对于需要处理高并发性同时始终保持高性能的工作负载而言更是如此。
计算资源会在没有活动时自动在后台关闭,并在您加载数据或有查询传入时恢复。通过新的无服务器端点访问 S3 数据湖时,无需单独为 Amazon Redshift Spectrum 付费。您将获得统一的无服务器体验,并以 RPU 秒为单位支付数据湖查询费用。有关更多信息,请参阅 Amazon Redshift 定价页面。
无服务器端点在 AWS 账户级别配置。如果您有多个团队或项目并且希望单独管理成本,则可以使用单独的 AWS 账户。您可以在预置的集群和无服务器端点之间以及不同账户的无服务器端点之间共享数据。
为了帮助您进行练习,我们预先为您提供 500 USD 的 AWS 服务抵扣金,供您试用 Amazon Redshift Serverless 公开预览版。 首次使用 Amazon Redshift Serverless 创建数据库将获得服务抵扣金。这些服务抵扣金仅用于支付 Amazon Redshift Serverless 的计算、存储和快照使用费用。
立即开始使用 Amazon Redshift Serverless 运行和扩展分析,无需预置和管理数据仓库集群。
— Danilo