亚马逊AWS官方博客
推出 Amazon MemoryDB for Redis — 一款与 Redisis 兼容、持久的内存数据库服务
交互式应用程序需要非常快速地处理请求并做出响应,这一要求延伸到架构的所有组件。如果您采用了微服务,并且您的架构由许多相互通信的小型独立服务组成,这一点就更加重要了。
因此,数据库性能对应用程序的成功至关重要。为了将读取延迟减少到微秒,可以在持久数据库之前放置内存缓存。在缓存方面,许多开发人员使用 Redis,它是一种开源的内存数据结构存储。事实上,根据 Stack Overflow 2021 年开发者调查,Redis 是五年来最受喜爱的数据库。
要在 AWS 上实施此设置,您可以使用 Amazon ElastiCache for Redis,它是一项完全托管式内存缓存服务,提供了持久数据库服务(如 Amazon Aurora 或 Amazon DynamoDB)之前的低延迟缓存,可最大限度地减少数据丢失。但是,此设置要求您在应用程序中引入自定义代码,使缓存与数据库保持同步。此外,运行缓存和数据库会产生费用。
推出 Amazon MemoryDB for Redis
今天,我很高兴地宣布正式发布 Amazon MemoryDB for Redis,它是一款新的与 Redis 兼容、持久的内存数据库。MemoryDB 让您可以轻松且经济高效地构建需要微秒读取和个位数毫秒写入性能且具备数据持久性和高可用性的应用程序。
现在,您可以简化架构并将 MemoryDB 作为单一的主数据库,而无需在持久数据库之前使用低延迟缓存。使用 MemoryDB 之后,所有数据都存储在内存中,从而实现低延迟和高吞吐量的数据访问。MemoryDB 使用跨多个可用区 (AZ) 存储数据的分布式事务日志,可实现高持久性的快速故障转移、数据库恢复和节点重启。
MemoryDB 维持与开源 Redis 的兼容性,并支持您熟悉的同一组 Redis 数据类型、参数和命令。这意味着您目前与开源 Redis 一起使用的代码、应用程序、驱动程序和工具可以与 MemoryDB 一起使用。作为开发人员,您可以立即访问许多数据结构,例如字符串、哈希、列表、集合、包含范围查询的排序集合、位图、超日志、地理空间索引和流。您还可以访问高级功能,例如内置复制、最近最少使用 (LRU) 的移出、事务和自动分区。MemoryDB 与 Redis 6.2 兼容,并将支持在开源中发布的较新版本。
此时,您可能有一个疑问,即 MemoryDB 与 ElastiCache 相比如何,因为这两种服务都可以让您访问 Redis 数据结构和 API:
- MemoryDB 可成为应用程序的安全的主数据库,因为它提供了数据持久性、微秒读取和个位数毫秒写入延迟。MemoryDB 使您无需在数据库之前添加缓存,即可实现交互式应用程序和微服务架构所需的低延迟。
- 另一方面,ElastiCache 为读取和写入提供了微秒延迟。它非常适合用于缓存您希望加快从现有数据库访问数据的工作负载。对于可能接受数据丢失的用例(例如,您可以从另一个源快速重建数据库),ElastiCache 也可用作主数据存储。
创建 Amazon MemoryDB 集群
在 MemoryDB 控制台中,我使用左侧导航窗格中的链接转到集群部分,然后选择创建集群。这将打开集群设置,我在其中输入集群的名称和描述。

所有 MemoryDB 集群都在虚拟私有云 (VPC) 中运行。在子网组中,我选择我的一个 VPC 并提供子网列表(集群将使用此列表分配其节点),从而创建子网组。

在集群设置中,我可以更改网络端口、控制节点和集群的运行时属性的参数组、节点类型、分片数量以及每个分片的副本数量。存储在集群中的数据在分片之间进行分区。分片数量和每个分片的副本数量决定了我的集群中的节点数量。考虑到每个分片都有一个主节点及其副本,我预计这个集群将有八个节点。
为实现与 Redis 版本的兼容性,我选择 6.2。我将所有其他选项保留为默认值,然后选择下一步。

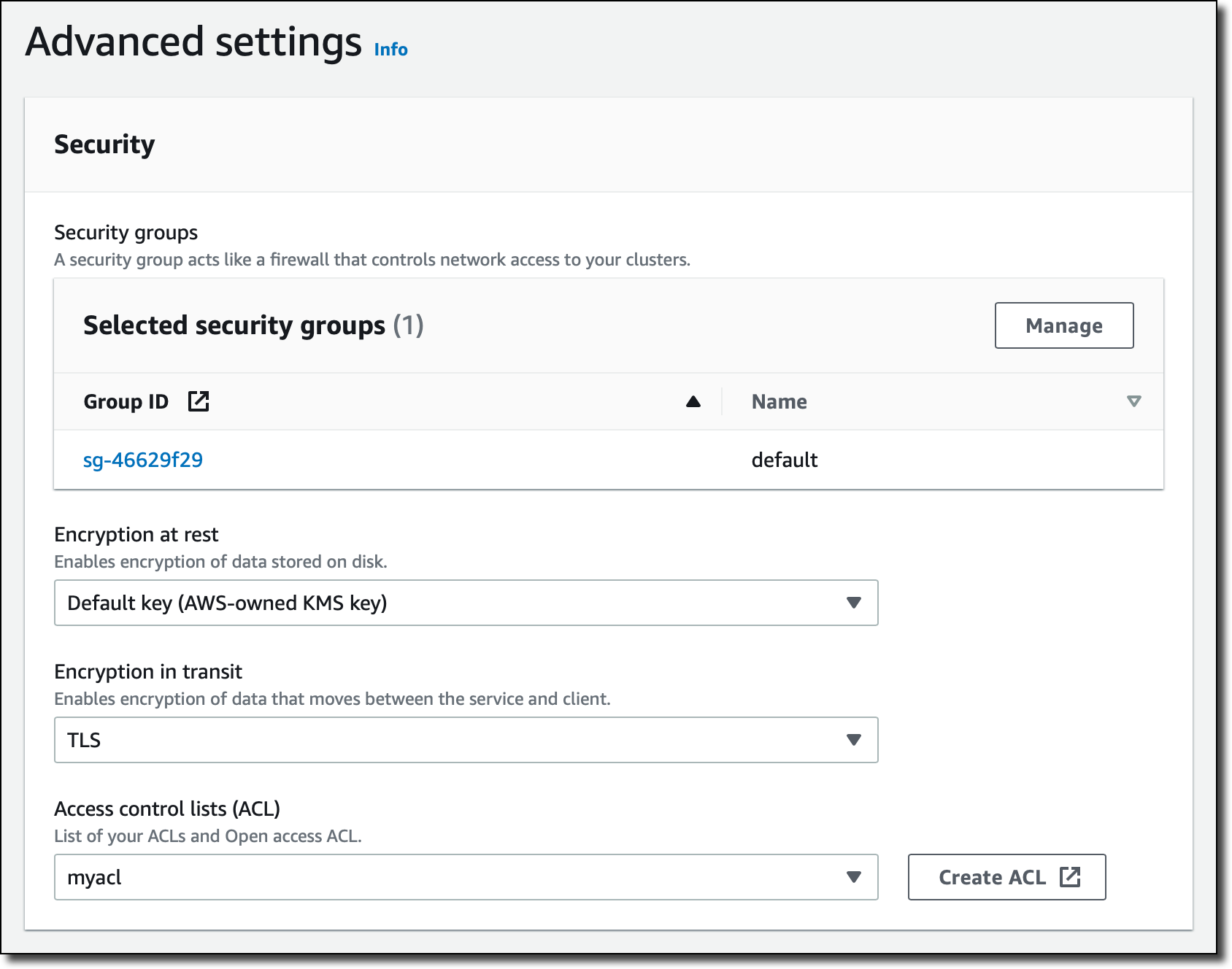
在高级设置 的安全部分,我为用于子网组的 VPC 添加默认安全组,然后选择我之前创建的访问控制列表 (ACL)。MemoryDB ACL 基于 Redis ACL,并提供用于连接到集群的用户凭证和权限。
在快照部分,我保留默认值,使 MemoryDB 自动创建每日快照,并选择 7 天的保留期。

对于维护,我保留默认值,然后选择创建。在这一部分,我还可以提供 Amazon Simple Notification Service (SNS) 主题,以便收到重要集群事件的通知。
几分钟后,集群运行,我可以使用 Redis 命令行界面或任何 Redis 客户端进行连接。
使用 Amazon MemoryDB 作为主数据库
管理客户数据是许多业务流程的关键组件。为测试我的新 Amazon MemoryDB 集群的持久性,我想将其用作客户数据库。为简单起见,让我们在 Python 中构建一个简单的微服务,使我能够使用 REST API 从 Redis 集群中创建、更新、删除和获取一个或所有客户数据。
这是我的 server.py 实现的代码:
from flask import Flask, request
from flask_restful import Resource, Api, abort
from rediscluster import RedisCluster
import logging
import os
import uuid
host = os.environ['HOST']
port = os.environ['PORT']
db_host = os.environ['DBHOST']
db_port = os.environ['DBPORT']
db_username = os.environ['DBUSERNAME']
db_password = os.environ['DBPASSWORD']
logging.basicConfig(level=logging.INFO)
redis = RedisCluster(startup_nodes=[{"host": db_host, "port": db_port}],
decode_responses=True, skip_full_coverage_check=True,
ssl=True, username=db_username, password=db_password)
if redis.ping():
logging.info("Connected to Redis")
app = Flask(__name__)
api = Api(app)
class Customers(Resource):
def get(self):
key_mask = "customer:*"
customers = []
for key in redis.scan_iter(key_mask):
customer_id = key.split(':')[1]
customer = redis.hgetall(key)
customer['id'] = customer_id
customers.append(customer)
print(customer)
return customers
def post(self):
print(request.json)
customer_id = str(uuid.uuid4())
key = "customer:" + customer_id
redis.hset(key, mapping=request.json)
customer = request.json
customer['id'] = customer_id
return customer, 201
class Customers_ID(Resource):
def get(自我,ustomer_id):
key = "customer:" + customer_id
customer = redis.hgetall(key)
print(customer)
if customer:
customer['id'] = customer_id
return customer
else:
abort(404)
def put(self, customer_id):
print(request.json)
key = "customer:" + customer_id
redis.hset(key, mapping=request.json)
return '', 204
def delete(self, customer_id):
key = "customer:" + customer_id
redis.delete(key)
return '', 204
api.add_resource(Customers, '/customers')
api.add_resource(Customers_ID, '/customers/<customer_id>')
if __name__ == '__main__':
app.run(host=host, port=port)这是 requirements.txt 文件,它列出了应用程序所需的 Python 模块:
同样的代码适用于 MemoryDB、ElastiCache 或任何 Redis 集群数据库。
我在 MemoryDB 集群所在的 VPC 中启动 Amazon Elastic Compute Cloud (Amazon EC2) 实例。为了能够连接到 MemoryDB 集群,我分配了默认安全组。我还添加了另一个安全组,为我提供了对实例的 SSH 访问权限。
我将 server.py 和 requirements.txt 文件复制到实例中,然后安装依赖项:
现在,我开始微服务:
在另一个终端连接中,我使用 curl 在我的数据库中创建一个客户,并在 /customers 资源中使用 HTTP POST:
结果确认数据已存储并且已向字段添加了唯一 ID(由 Python 代码生成的 UUIDv4):
所有字段都存储在 Redis Hash 中,密钥是 customer:<id>。
我重复几次上一个命令,以创建三个客户。客户数据是相同的,但每个数据都有一个唯一 ID。
现在,我获得了一份列表,列出了所有具有到 /customers 资源 HTTP GET 的客户:
在代码中,有一个使用 SCAN 命令的匹配键上的 iterator。 在响应中,我看到了三位客户的数据:
其中一位客户花费了所有余额。我用包含 ID (/customers/<id>) 的客户资源 URL 上的 HTTP PUT 更新该字段:
该代码正在使用请求数据更新 Redis Hash 的字段。在这种情况下,它将余额设置为零。我按 ID 获取客户数据,从而验证更新:
在响应中,我看到余额已更新:
这就是 Redis 的力量! 我只需几行代码就能够创建微服务的框架。最重要的是,MemoryDB 为我提供了生产环境中所需的持久性和高可用性,而无需在后端添加另一个数据库。
根据我的工作负载,我可以通过添加或删除节点来横向扩展我的 MemoryDB 集群,或者通过移动到更大或更小的节点类型进行纵向扩展。MemoryDB 支持使用分片进行写入扩展以及通过添加副本进行读取扩展。我的集群将继续保持在线状态,并在调整运维期间支持读取和写入操作。
可用性和定价
Amazon MemoryDB for Redis 现已在美国东部(弗吉尼亚北部)、欧洲(爱尔兰)、亚太地区(孟买)和南美洲(圣保罗)推出,而且即将在更多 AWS 区域推出。
您可以使用 AWS 管理控制台、AWS 命令行界面 (CLI) 或 AWS 开发工具包在几分钟内创建 MemoryDB 集群。即将提供 AWS CloudFormation 支持。对于节点,MemoryDB 目前支持 R6g Graviton2 实例。
要从 ElastiCache for Redis 迁移到 MemoryDB,您可以备份 ElastiCache 集群并将其还原到 MemoryDB 集群。您还可以从存储在 Amazon Simple Storage Service (Amazon S3) 上的 Redis Database Backup (RDB) 文件创建新集群。
通过 MemoryDB,您可以根据每个节点的按需实例小时数、写入集群的数据量以及快照存储为实际使用量付费。 有关更多信息,请参阅 MemoryDB 定价页面。
了解详情
观看以下视频,获得快速概述。
立即将 Amazon MemoryDB for Redis 作为您的主数据库。
– Danilo