亚马逊AWS官方博客
使用 QLoRA 在 Amazon SageMaker Studio notebook 上对 Falcon-40B 和其他 LLM 进行交互式微调
使用 notebook 微调 LLM
SageMaker 提供了两个选项,可以启动完全托管的 notebook,用于探索数据和构建机器学习(ML)模型。第一种选项是快速启动,也就是在 Amazon SageMaker Studio(用于机器学习的完全集成式开发环境(IDE))中访问协作 notebook。您可以在 SageMaker Studio 中快速启动 notebook,在不中断工作的情况下上调或下调底层计算资源,甚至可以在 notebook 上实时共同编辑和协作。除了创建 notebook 外,您还可以在 SageMaker Studio 的单一管理面板中执行所有机器学习开发步骤,以构建、训练、调试、跟踪、部署和监控模型。第二种选项是 SageMaker notebook 实例,这是一个在云端运行 notebook 的完全托管式机器学习计算实例,可让您对 notebook 配置进行更多控制。
在这篇文章的其余部分,我们使用 SageMaker Studio notebook,因为我们希望利用 SageMaker Studio 的托管 TensorBoard 实验跟踪功能和 Hugging Face Transformer 对 TensorBoard 的支持。不过,整个示例代码中显示的概念同样适用于使用 conda_pytorch_p310 内核的 notebook 实例。值得注意的是,SageMaker Studio 的 Amazon Elastic File System(Amazon EFS)卷意味着您不需要预置 Amazon Elastic Block Store(Amazon EBS)卷的大小,考虑到 LLM 中的模型权重较大,这一点非常有用。
使用由大型 GPU 实例支持的 notebook,可以在不冷启动容器的情况下实现快速原型设计和调试。不过,这也意味着您需要在使用完 notebook 实例后关闭这些实例,以避免额外费用。Amazon SageMaker JumpStart 和 SageMaker Hugging Face 容器等其他选项可用于微调,建议您参考以下关于上述方法的文章,选择最适合您和您团队的选项:
- 根据财务数据对 Amazon SageMaker JumpStart 中的基础模型进行域自适应微调
- 使用 Hugging Face 和 LoRA 在单个 Amazon SageMaker GPU 上训练大型语言模型
先决条件
如果您是第一次使用 SageMaker Studio,首先需要创建 SageMaker 域。我们还使用托管的 TensorBoard 实例进行实验跟踪,但这在本教程中是可选的。
此外,您可能需要为相应的 SageMaker Studio KernelGateway 应用程序申请增加服务限额。为了对 Falcon-40B 进行微调,我们使用 ml.g5.12xlarge 实例。
要申请增加服务限额,请在 AWS 服务限额控制台上导航到 AWS 服务、Amazon SageMaker,然后选择在 ml.g5.12xlarge 实例上运行的 Studio KernelGateway Apps。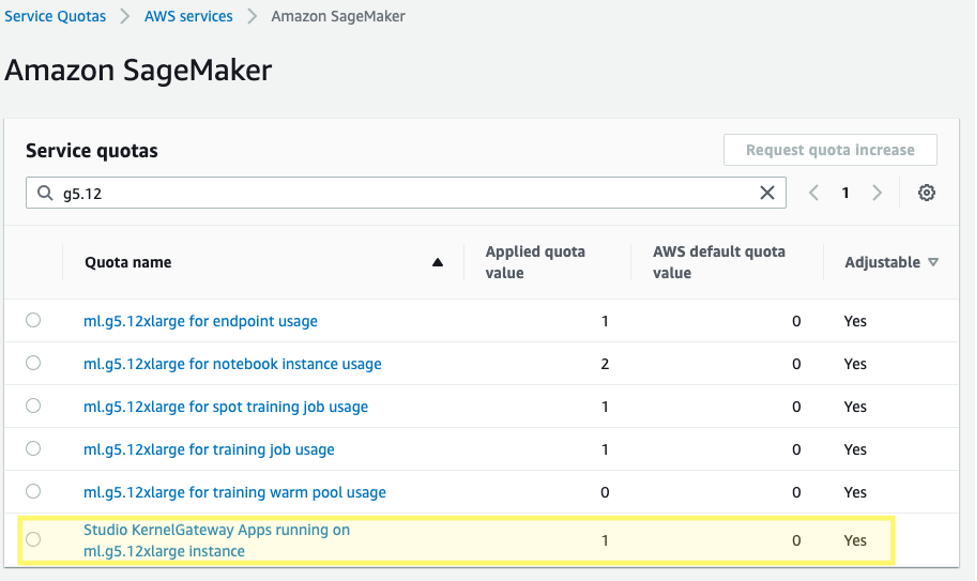
开始使用
这篇文章的代码示例可以在以下 GitHub 存储库中找到。首先,我们从 SageMaker Studio 中选择 Data Science 3.0 映像和 Python 3 内核,这样我们就有了一个最新的 Python 3.10 环境来安装软件包。

我们安装 PyTorch 以及所需的 Hugging Face 和 bitsandbytes 库:
接下来,我们使用已安装的 CUDA 设置 CUDA 环境路径,CUDA 是 PyTorch 安装的一个依赖项。这是 bitsandbytes 库正确查找和加载正确的 CUDA 共享对象二进制文件的必要步骤。
加载预训练的基础模型
我们使用 bitsandbytes 将 Falcon-40B 模型量化为 4 位精度,这样就能利用 Hugging Face Accelerate 的原始管道并行技术将模型加载到 4 个 A10G GPU 的内存中。如前面提到的 Hugging Face 帖子所述,由于模型权重以 4 位 NormalFloat 格式存储,但会根据需要在前向和后向传递时去量化为计算 bfloat16,因此 QLoRA 调整在大量实验中都能与 16 位微调方法相媲美。
在加载预训练的权重时,我们指定 device_map=”auto",这样 Hugging Face Accelerate 就会自动决定将模型的每一层放在哪个 GPU 上。这一过程称为模型并行。
利用 Hugging Face 的 PEFT 库,您可以冻结大部分原始模型权重,并通过训练一组更小的额外参数来替换或扩展模型层。这就大大降低了训练所需的计算成本。我们在 LoRA 配置中将要微调的 Falcon 模块设置为 target_modules:
请注意,我们只对 0.26% 的模型参数进行了微调,这使得微调在合理的时间内是可行的。
加载数据集
我们使用 samsum 数据集进行微调。Samsum 收集了 16000 条类似信使的对话,并附有标签摘要。以下是该数据集的示例:
在实践中,您需要使用与您希望调整模型的任务相关的特定知识的数据集。使用 Amazon SageMaker Ground Truth Plus 可以加快构建此类数据集的过程,详情请参见 Amazon SageMaker Ground Truth Plus 为您的生成式人工智能应用程序提供高质量的人类反馈。
微调模型
在微调之前,我们定义要使用的超参数并训练模型。我们还可以通过定义 logging_dir 参数并请求 Hugging Face transformer report_to="tensorboard",将指标记录到 TensorBoard:
监控微调
有了上述设置,我们就可以实时监控我们的微调。要实时监控 GPU 的使用情况,我们可以直接从内核容器中运行 nvidia-smi。要启动在映像容器上运行的终端,只需选择 notebook 顶部的终端图标即可。

在这里,我们可以使用 Linux watch 命令每半秒重复运行一次 nvidia-smi:
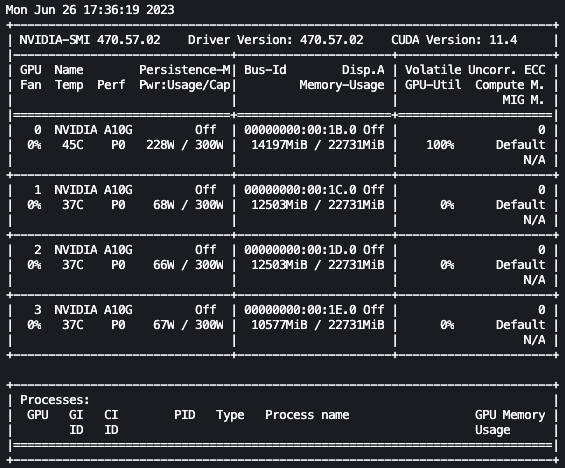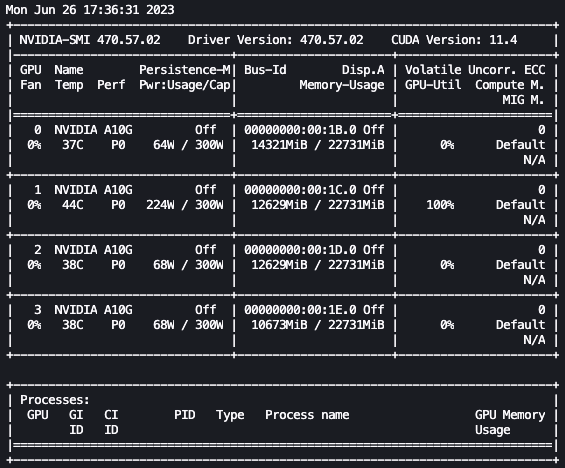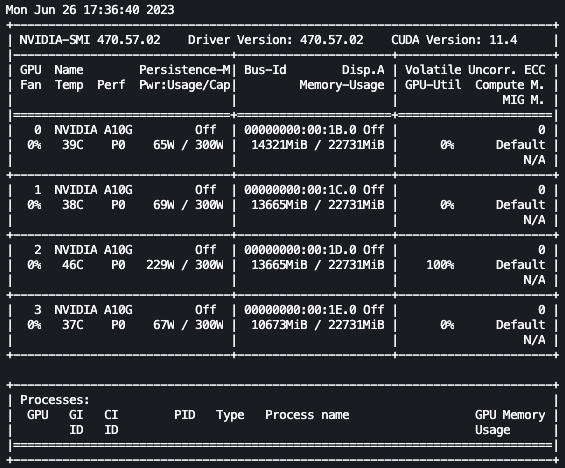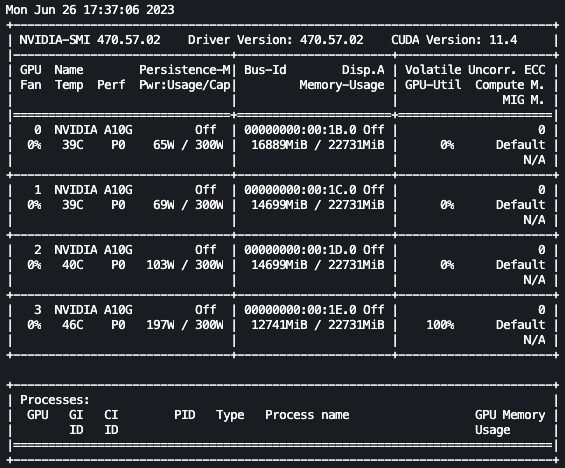
在前面的动画中,我们可以看到模型权重分布在 4 个 GPU 上,并且随着层的串行处理,计算也分布在这些 GPU 上。
为了监控训练指标,我们利用写入指定 Amazon Simple Storage Service(Amazon S3)存储桶的 TensorBoard 日志。我们可以从 AWS SageMaker 控制台启动 SageMaker Studio 域用户的 TensorBoard:
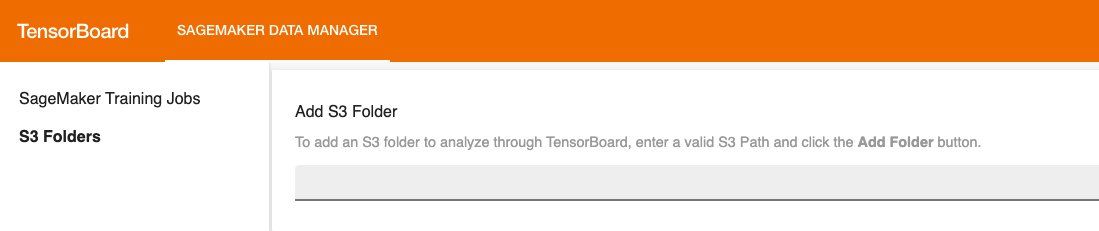
加载后,您可以指定指示 Hugging Face transformer 登录的 S3 存储桶,以便查看训练和评估指标。
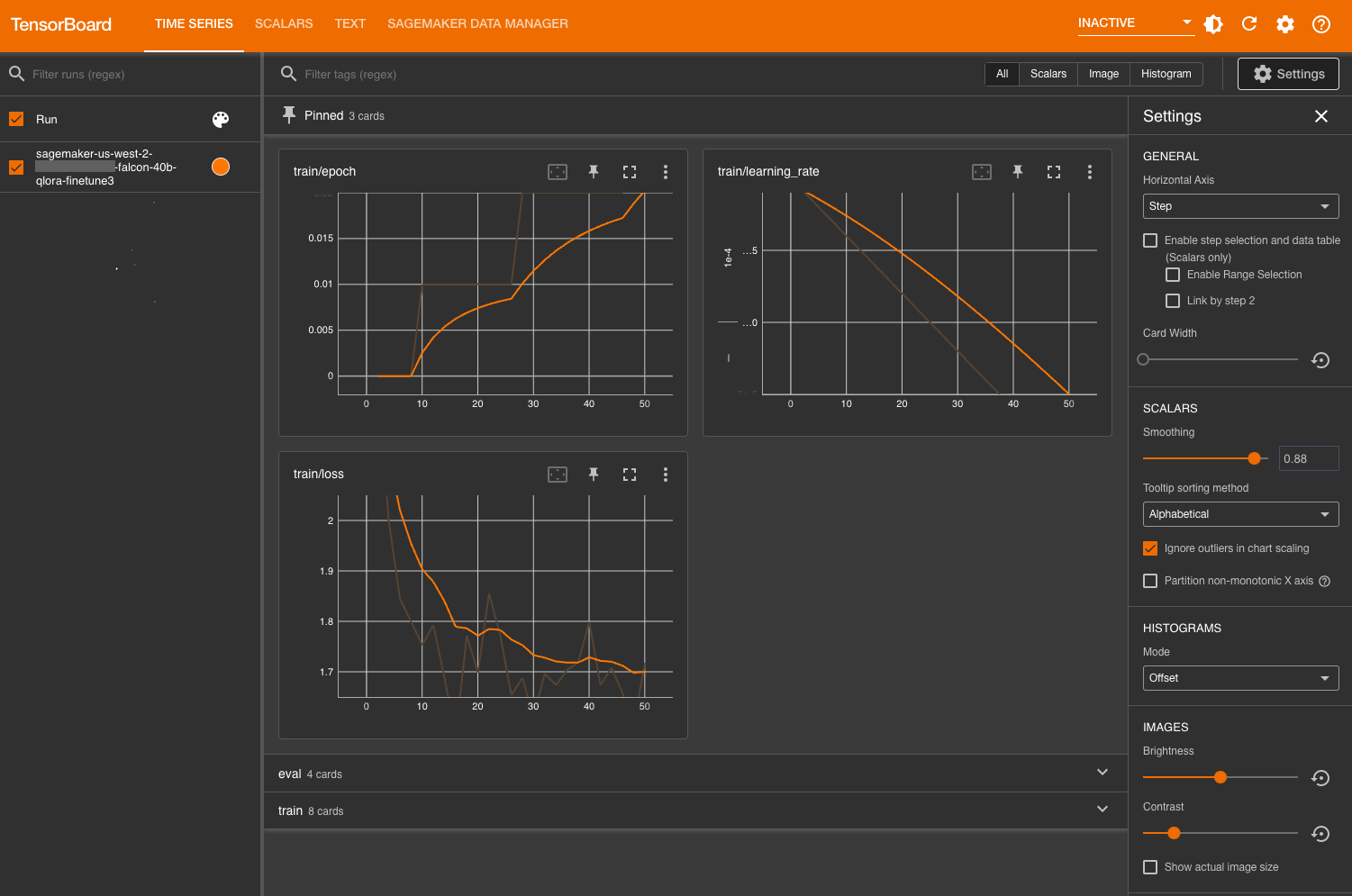
评估模型
模型训练完成后,我们可以进行系统评估或直接生成响应:
对模型的性能感到满意后,可以保存模型:
您也可以选择将模型托管在专用的 SageMaker 端点中。
清理
完成以下步骤清理资源:
- 关闭 SageMaker Studio 实例以避免产生额外费用。
- 关闭 TensorBoard 应用程序。
- 通过清除 Hugging Face 缓存目录来清理 EFS 目录:
总结
通过 SageMaker notebook,可以在交互式环境中快速有效地微调 LLM。在这篇文章中,我们展示了如何使用 Hugging Face PEFT 和 bitsandbtyes 在 SageMaker Studio notebook 上通过 QLoRA 微调 Falcon-40B 模型。
我们还鼓励您通过探索 SageMaker JumpStart、Amazon Titan 模型和 Amazon Bedrock,了解有关 Amazon 生成式人工智能功能的更多信息。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
关于作者
 Sean Morgan 是 AWS 的高级机器学习解决方案架构师。他在半导体和学术研究领域拥有丰富的经验,并利用自己的经验协助客户在 AWS 上实现目标。在空闲时间,Sean 是一位活跃的开源贡献者和维护者,也是 TensorFlow Addons 特别兴趣小组的负责人。
Sean Morgan 是 AWS 的高级机器学习解决方案架构师。他在半导体和学术研究领域拥有丰富的经验,并利用自己的经验协助客户在 AWS 上实现目标。在空闲时间,Sean 是一位活跃的开源贡献者和维护者,也是 TensorFlow Addons 特别兴趣小组的负责人。
 Lauren Mullennex 是 AWS 的高级人工智能/机器学习专业解决方案架构师。她在 DevOps、基础设施和机器学习领域拥有十年的经验。她还撰写了一本关于计算机视觉的书籍。她关注的其他领域包括 MLOps 和生成式人工智能。
Lauren Mullennex 是 AWS 的高级人工智能/机器学习专业解决方案架构师。她在 DevOps、基础设施和机器学习领域拥有十年的经验。她还撰写了一本关于计算机视觉的书籍。她关注的其他领域包括 MLOps 和生成式人工智能。
 Philipp Schmid 是 Hugging Face 的技术主管,其使命是通过开源代码和开放科学使良好的机器学习大众化。Philipp 热衷于生产尖端的生成式人工智能机器学习模型。他喜欢在 AWS 上的数据科学等各种聚会上以及他的技术博客上分享自己在人工智能和 NLP 方面的知识。
Philipp Schmid 是 Hugging Face 的技术主管,其使命是通过开源代码和开放科学使良好的机器学习大众化。Philipp 热衷于生产尖端的生成式人工智能机器学习模型。他喜欢在 AWS 上的数据科学等各种聚会上以及他的技术博客上分享自己在人工智能和 NLP 方面的知识。