亚马逊AWS官方博客
通过 EMR Notebooks 在运行的集群上安装 Python 库
Original URL:https://thinkwithwp.com/blogs/big-data/install-python-libraries-on-a-running-cluster-with-emr-notebooks/
本博文将讨论如何通过 EMR Notebook 直接在正在运行的集群上安装笔记本范围的Python库。在此功能推出之前,您必须依赖Bootstrap引导操作或使用自定义 AMI 来安装预置 EMR AMI 没有预先打包的其他库。接下来,博文还将讨论如何使用 EMR Notebooks 中本地可用的预安装 Python 库来分析结果并绘制图表。此功能在您无法访问 PyPI 存储库但需要分析和可视化数据集的情况下非常有用。
在EMR Notebooks中使用笔记本范围的Python库的优势
笔记本范围的库可为您提供以下优势:
- 运行时安装 – 您可以从 PyPI 存储库导入您需要的 Python 库,并在需要时立即将它们安装到远程集群上。这些库可立即用于 Spark 运行时环境,无需重新启动笔记本会话或重新创建集群。
- 隔离依赖关系 – 使用 EMR Notebooks 安装的库是笔记本会话范围隔离的,不会干扰集群引导操作安装的库或从其他笔记本会话安装的库。这些笔记本范围的库会优先于引导操作的库被集群使用。多个笔记本用户可以各自导入和使用不同版本的库,而不会在同一集群上发生依赖关系冲突。
- 便携的库环境 – 库的安装将在您的笔记本文件中进行。这样一来,当您将笔记本切换到另一个集群时,就可以通过重新执行笔记本代码来重新创建库环境。当笔记本会话结束时,通过 EMR Notebooks 安装的库将自动从托管 EMR 集群中删除。
准备工作
要在 EMR Notebooks 中使用此功能,您需要将一个笔记本连接到运行 EMR 5.26.0 或更高版本的集群。该集群应具有访问您要从中导入库的公共或私有 PyPI 存储库的权限。有关更多信息,请参阅创建笔记本。
配置 VPC 网络以允许 VPC 内部的集群连接到外部存储库的方法有多种。有关更多信息,请参阅 Amazon VPC 用户指南中的场景和示例。
使用笔记本范围的库
本博文将通过分析公开的关于图书评论的 Amazon Customer Reviews 数据集,展示 EMR Notebooks 的笔记本范围的库功能。有关更多信息,请参阅Registry of Open Data on AWS上的 Amazon Customer Reviews 数据集。
打开您的笔记本,确保笔记本内核设置为 PySpark。在笔记本单元格中运行以下命令:
您将获得以下输出:
您可以通过运行以下命令来检查当前笔记本的会话配置:
您将获得以下输出:

默认情况下,笔记本会话将Python环境配置为 Python 3(通过 spark.pyspark.python)。如果您希望使用 Python 2,请通过在笔记本单元格中运行以下命令来重新配置笔记本会话:
您将获得以下输出:
![]()
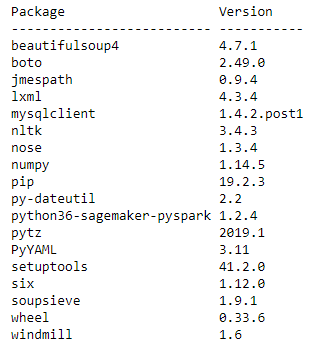
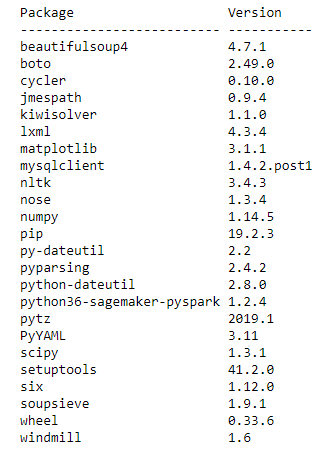
开始分析之前,请检查集群上已有的库。您可以使用PySpark API中的 list_packages()执行此操作,结果会列出了集群上的所有 Python 库。运行以下代码:
您将获得与以下代码类似的输出,其中显示了集群上所有可用的 Python 3 兼容的包:
通过以下代码将Amazon Customer Reviews图书评论数据加载到Spark DataFrame:
您现在已准备好数据可以进行浏览。使用以下代码确定数据集的 Schema 和列数:
以下代码为输出:

此数据集共有 15 列。您还可以通过运行以下代码来检查数据集的总行数:
您将获得以下输出:
![]()
使用以下代码检查图书总数:
您将获得以下输出:
![]()
您还可以按年分析图书评论的数量,并查看顾客评分的分布情况。要执行此操作,请从公共 PyPI 存储库导入0.25.1 版本的 Pandas 库和最新的 Matplotlib 库。使用 install_pypi_package API 将它们安装到已连接到笔记本的集群上。请参阅以下代码:
您将获得以下输出:
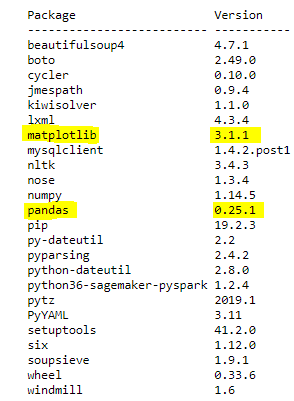
PySpark API 中的install_pypi_package 将安装库以及任何关联的依赖。默认情况下,它会安装与您正在使用的 Python 版本兼容的最新版本的库。您还可以参考上面的Pandas 例子通过指定库版本来安装特定版本的库。
通过运行以下代码,验证包是否已成功安装:
您将获得以下输出:
您还可以分析数年来评论数的趋势。使用 to Pandas()将 Spark Data Frame转换为 Pandas Data Frame,然后可以使用 Matplotlib 进行可视化。请参阅以下代码:
上述命令将在连接的 EMR 集群上渲染图像,要想在笔记本中查看图像,请使用 %matplot 魔法函数。请参阅以下代码:
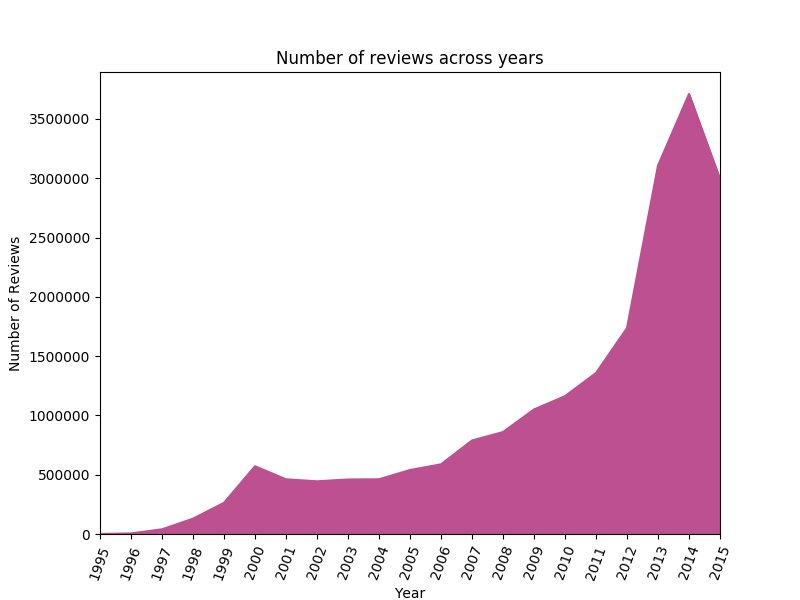
下图显示了从 1995 年到 2015 年,顾客评论的数量呈指数级增长。一个有趣的现象是,2001 年、2002 年和 2015 年的结果有些异常,评论数量相比前一年有所下降。
您也可以分析星级评分的分布并使用饼图进行可视化。请参阅以下代码:
使用 %matplot 魔法函数打印饼图,并使用以下代码在笔记本中进行可视化:
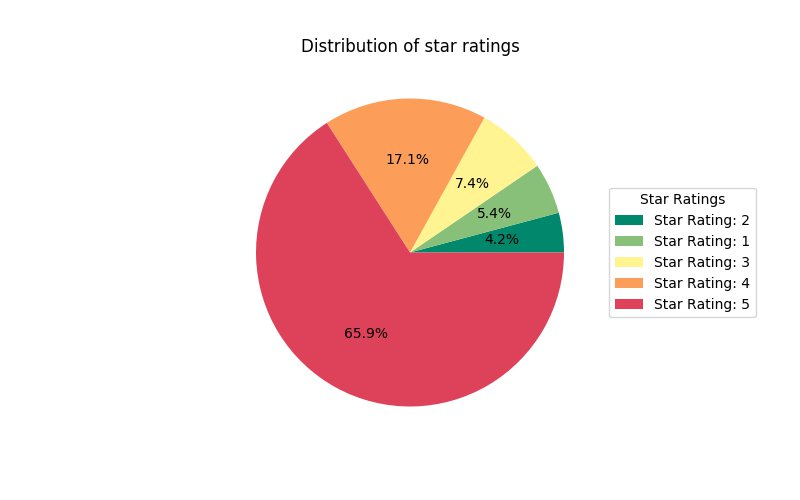
下图显示 80% 的用户给出的评分为 4 分或更高。大约 10% 的用户对其图书评分为 2 分或更低。总体而言,顾客对从 Amazon 购买的图书感到满意。
最后,使用 Pyspark API 中的uninstall package 卸载您使用 install_package API 安装的 Pandas 库。当您想要使用与以前通过 EMR Notebooks 安装的库的不同版本时,这非常有帮助。请参阅以下代码:
您将获得以下输出:

接下来,运行以下代码:
您将获得以下输出:
关闭笔记本后,使用 install_pypi_package API 在集群上安装的 Pandas 和 Matplot 库将被丢弃并从集群中删除。
在 EMR Notebooks 中使用本地 Python 库
前面讨论的笔记本范围的库要求您的 EMR 集群能够访问 PyPI 存储库。如果无法将 EMR 集群连接到存储库,可以使用 EMR Notebooks 预先打包的 Python 库,在笔记本本地分析和可视化您的结果。与笔记本范围的库不同,这些本地库仅可用于 Python 内核,不可用于集群上的 Spark 环境。要使用这些本地库,请将您集群上的 Spark 计算结果导出至您的笔记本,并使用笔记本魔法函数在本地绘制结果图表。由于您正在使用笔记本而不是集群来分析和绘制图形,因此导出到笔记本的数据集要尽量小一些(建议小于 100MB)。
要查看本地库列表,请在笔记本单元格中运行以下命令:
您将获得笔记本中所有可用库的列表。因列表过长,这里就不列出结果。
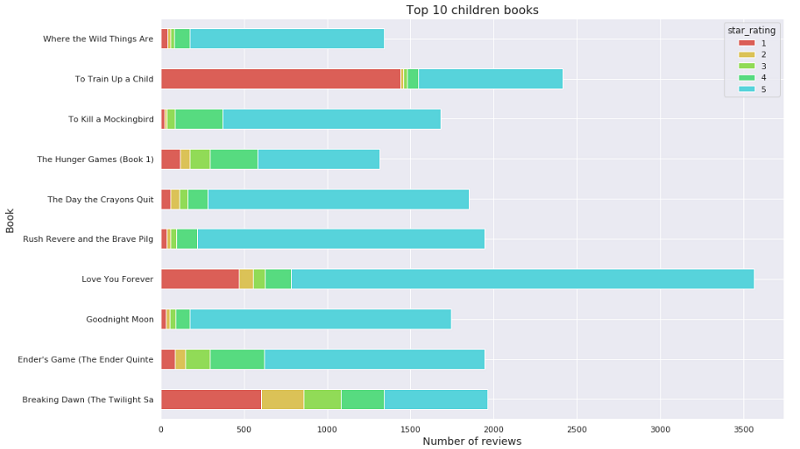
下面的分析将从您的图书评论数据集中找出排名前 10 的儿童图书,并分析这些儿童图书的星级评分的分布情况。
通过以下代码,您可以使用顾客的书面评论来识别儿童图书:
使用以下代码按顾客评论数量绘制排名前 10 的儿童图书的图表:
您将获得以下输出:

使用以下代码分析这些图书的顾客评分分布情况:
您将获得以下输出:

要在笔记本中本地绘制这些结果的图表,请从 Spark driver 中导出数据,并将其作为 Pandas DataFrame 缓存在本地笔记本中。要实现此目的,请先使用以下代码注册一个临时表:
使用本地 SQL 魔法函数通过以下代码从此表中提取数据:
有关这些魔法函数命令的详细信息,请参阅 GitHub 存储库。
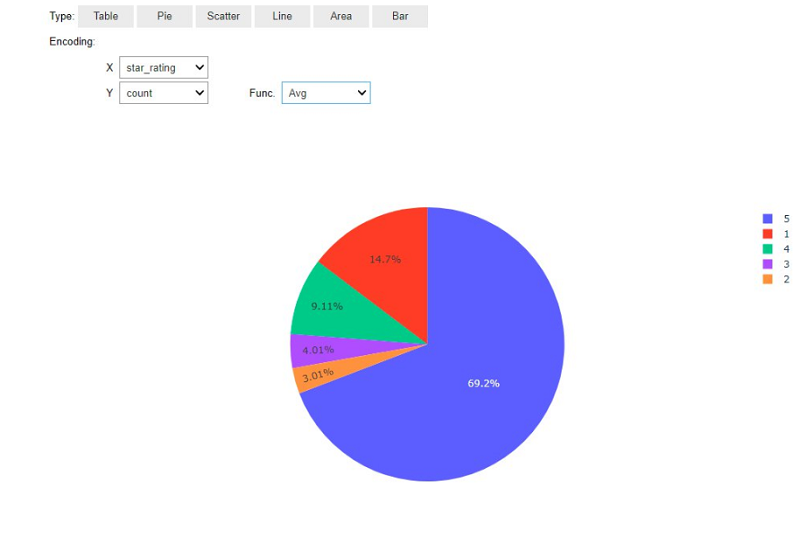
执行代码后,您将会看到一个用户界面,它可以通过交互方式绘制结果图表。以下饼图显示了评分的分布情况:
您还可以使用 EMR Notebooks 提供的本地 Matplot 和 Seaborn 库绘制更复杂的图表。请参阅以下代码:
您将获得以下输出:
小结
本博文展示了如何使用 EMR Notebooks 管理笔记本范围的库,该功能可以帮助您在 EMR 集群运行时导入和安装需要的 Python 库,您可以使用这些库增强数据分析然后通过各种图表将结果可视化。本博文还演示了如何使用 EMR Notebook 中提供的预先打包的本地 Python 库来分析结果并绘制图表。
关于作者
 Parag Chaudhari 是 AWS 的一名软件开发工程师。
Parag Chaudhari 是 AWS 的一名软件开发工程师。