亚马逊AWS官方博客
AWS Data Lab 如何帮助 BMW Financial Services 设计和构建多账户的现代化数据架构
在这篇博文中,我们将讨论 AWS Data Lab 如何使用 AWS 上的云数据中心,帮助 BMW Financial Services 为欧洲 BMW 市场之一构建监管报告应用程序。
解决方案概览
在监管报告背景下,BMW Financial Services 处理包含个人身份信息(PII)的关键金融服务数据。我们需要每月向欧洲国家监管机构之一提供针对我们财务数据的深入分析,而且在处理 PII 数据时,我们还需要遵守 Schrems II 和 GDPR 法规。这要求在将 PII 加载到云数据中心时对其进行假名化,并且必须以假名的形式对其进行进一步处理。有关假名化过程的概述,请查看 Build a pseudonymization service on AWS to protect sensitive data(在 AWS 上构建假名化服务以保护敏感数据)。
为了精确高效地满足这些要求,BMW Financial Services 决定与 AWS Data Lab 合作。AWS Data Lab 有两种服务:Design Lab 和 Build Lab。
Design Lab
Design Lab 是一项 1 到 2 天的活动,适用于需要真实架构建议但尚未准备好构建的客户,这些建议基于 AWS 专业知识。以 BMW Financial Services 为例,在开始构建阶段之前,关键是让所有利益相关方聚集在一起,记录各方(从各种数据来源的所有者到将使用该平台进行分析并获得业务见解的最终用户等)提出的可能影响数据平台的所有功能性和非功能性要求。在 Design Lab 的工作范围内,我们讨论了三个使用案例:
- 监管报告 – BMW Financial Services 最重要的任务是监管报告使用案例,这涉及到收集与计算向国家监管机构申报的数据和报告。
- 本地数据仓库 – 对于此使用案例,我们需要计算和存储项目期间将会定义的所有关键绩效指标(KPI)和关键价值指标(KVI)。我们需要存储历史数据,但需要遵守 GDPR 指令应用假名化流程。此外,每天都必须通过 Tableau 可视化工具访问历史数据。关于结构,有必要定义两个级别(至少):一个是合同级别,用于证明所有关键绩效指标的计算是合理的,另一个是汇总级别,用于优化修复。在应用程序中限制使用个人数据,但对于获得授权的使用模式,必须可以进行重新识别。
- 会计明细 – 此使用案例基于 BMW 的会计工具 IFT,该工具在合同级别提供来自所有当地市场应用程序的会计余额。它必须每月至少进行一次。但是,如果在结算期间发现了 IFT 上的一些问题,我们必须能够重启并删除之前的结果。月末结算完成后,此使用案例必须保留当月生成的最后一个会计余额版本并进行存储。同时,所有会计余额版本都必须可供其他应用程序访问以进行查询,并且能够检索 24 个月内的信息。

基于这些要求,我们在 Design Lab 期间开发了以下架构。
此解决方案包含以下组件:
- 为我们的三个使用案例提供数据的主数据来源已经在云数据中心中公布。云数据中心使用 AWS Lake Formation 资源链接向使用者账户授予对数据集的访问权限。
- 对于标准的定期提取、转换和加载(ETL, Extract, Transform, and Load)作业,如果涉及到转换数据类型、根据数值数据创建标签或者根据标签创建布尔值标记等操作,我们使用 AWS Glue ETL 作业。
- 对于历史的 ETL 作业或更复杂的计算,例如账户详细信息使用案例(可能涉及与自定义配置和调整的大量关联),我们建议使用 Amazon EMR。这使您可以在精细级别上控制集群配置。
- 要存储可以实现重新处理输入或重新运行失败作业等功能的作业元数据,我们建议构建数据注册表。数据注册表的目标是为提取到数据湖中的所有数据创建集中清单。您可以触发基于计划的 AWS Lambda 函数,在集中式元数据存储中云数据中心的语义层上注册数据登陆。我们建议为数据注册表使用 Amazon DynamoDB。
- Amazon Simple Storage Service(Amazon S3)用作存储机制,支持使用数据管理框架 Apache Hudi 的监管报告使用案例。Apache Hudi 对我们的使用案例很有用,因为我们需要开发数据管道,满足对记录级别的插入、更新、更新插入和删除功能的需求。Amazon EMR 和 AWS Glue 作业通过 Hudi 连接器以及 Amazon Athena 和 Amazon Redshift Spectrum 等查询引擎支持 Hudi 表。
- 在监管报告 S3 存储桶的数据存储过程中,我们可以在 AWS Glue Data Catalog 中填充所需的元数据。
- Athena 提供了一个临时查询环境,用于使用标准 SQL 对存储在 Amazon S3 中的数据进行交互式分析。它与 AWS Glue Data Catalog 进行了集成,具备开箱即用的特点。
- 对于数据仓库使用案例,我们需要首先对数据进行反规范化,以创建支持优化分析查询的维度模型。为了进行这种转换,我们使用 AWS Glue ETL 作业。
- Amazon Redshift 中的维度数据集市可以支持我们的控制面板和自助报告需求。Amazon Redshift 中的数据根据业务需求划分为多个主题区域,通过维度模型可以进行跨主题区域分析。
- 作为创建 Amazon Redshift 集群的副产品,我们可以使用 Redshift Spectrum 访问该架构的监管报告存储桶中的数据。它充当了访问更精细数据的前端,而无需将其实际加载到 Amazon Redshift 集群中。
- 提供给云数据中心的数据包含假名化的个人数据。但是,在 Tableau 上可视化数据或者在生成 CSV 报告时,我们需要能够对假名化的列重新进行个性化设置。Athena 和 Amazon Redshift 均支持 Lambda UDF,它可用于访问云数据中心 PII API,以便在将假名化的列呈现给最终用户之前对其重新进行个性化设置。
- Athena 和 Amazon Redshift 均可通过 JDBC(Java Database Connectivity,Java 数据库连接)进行访问,为数据使用者提供访问权限。
- 我们可以在 AWS Glue 中使用 Python shell 作业,对我们的任一分析解决方案运行查询,将结果转换为所需的 CSV 格式,然后将它们存储到 BMW 受保护的文件夹中。
- 在本地部署的任何商业智能(BI)工具都可以连接到 Athena 和 Amazon Redshift,并可利用它们的查询引擎执行任何繁重的计算,然后再接收提供给控制面板的最终数据。
- 对于数据管道编排,我们建议使用 AWS Step Functions,因为它具有低代码开发体验,并且与讨论的所有其他组件全面集成。
以上述架构为长期目标状态,我们结束了 Design Lab,并决定返回 Build Lab 以加快解决方案的开发。
为 Build Lab 做好准备
继 Design Lab 之后的 Build Lab 的典型准备工作包括确定一些常见使用案例模式示例,通常是更复杂的示例。为了最大限度地确保 Build Lab 的成功,我们将长期目标架构缩减为一部分组件,它们能够满足这些示例的要求,并且可以通过 3 到 5 天的紧张冲刺实现。
为了 Build Lab 的成功,我们还需要确定和解决任何外部依赖关系,例如与数据来源和目标的网络连接。如果这不可行,那么我们需要找到有意义的方法来模拟这些情况。例如,为了使原型更接近生产环境的情况,我们决定根据 BMW 现有的团队结构,为每个使用案例使用单独的 AWS 账户,并使用消费者级别的 S3 存储桶而不是 BMW 的网络附属存储(NAS)。
Build Lab
BMW 团队为他们的 Build Lab 设定了 4 天时间。在此期间,他们的专职 Data Lab 架构师与团队携手,帮助他们构建了以下原型架构。
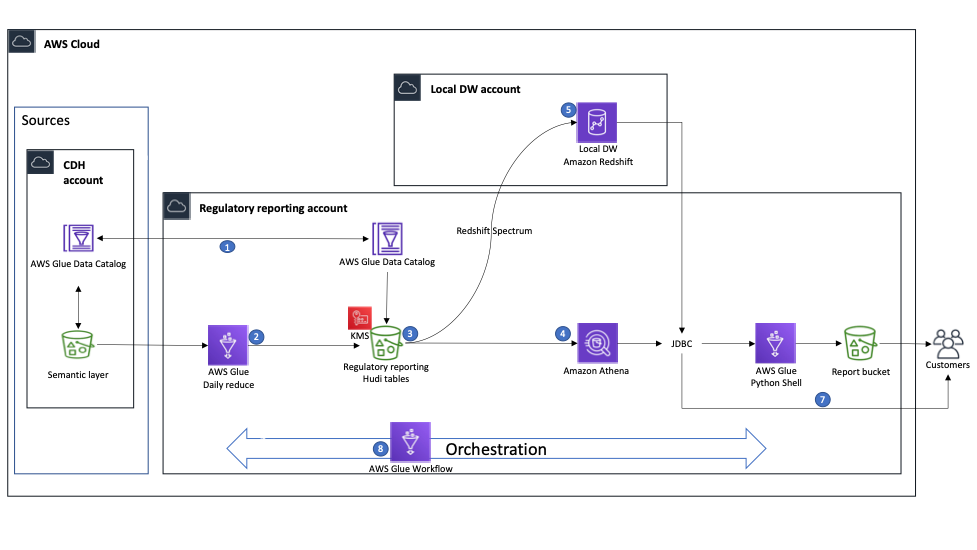
此解决方案包括以下组成部分:
- 第一步是将云数据中心的 AWS Glue Data Catalog 与监管报告账户同步。
- 在监管报告账户上运行的 AWS Glue 作业可以访问云数据中心资源账户中的数据。在 Build Lab 期间,BMW 团队为六张表实施了 ETL 作业,使用 Hudi 解决了插入、更新和删除记录的要求。
- ETL 作业的结果存储在数据湖层中,以 Hudi 表的形式存储在监管报告 S3 存储桶中,这些表已在 AWS Glue Data Catalog 中编目,可供多个 AWS 服务使用。存储桶使用 AWS Key Management Service(AWS KMS)进行加密。
- Athena 用于在数据湖上运行探索性查询。
- 为了演示跨账户使用模式,我们在其上创建了一个 Amazon Redshift 集群,从 Data Catalog 创建了外部表,并使用 Redshift Spectrum 来查询数据。为了在监管报告账户 Data Catalog 的子网组与本地数据仓库账户上的 Amazon Redshift 集群子网组之间实现跨账户连接,我们必须启用 VPC 对等连接。为了在 Build Lab 期间加速和优化这些配置的实现,我们获得了一位 AWS 网络专家的支持,他主持了一次有价值的会议,BMW 团队在会上了解了架构的网络连接详情。
- 关于数据使用,BMW 团队实施了一个 AWS Glue Python Shell 作业(该作业使用 JDBC 连接来连接到 Amazon Redshift 或 Athena),运行了查询,并将结果以 CSV 文件形式存储在报告存储桶中,以后可供最终用户访问该文件。
- 最终用户还可以使用 JDBC 连接直接连接到 Athena 和 Amazon Redshift。
- 我们决定使用 AWS Glue 工作流来编排 AWS Glue ETL 作业。我们将最终的工作流用于实验结束时的演示。
这样,我们就完成了设定的所有目标,并结束了为期 4 天的 Build Lab。
结论
在这篇博文中,我们向您介绍了 BMW Financial Services 团队与 AWS Data Lab 团队合作的旅程,他们一起参与 Design Lab 来确定最适合其使用案例的架构,以及在随后的 Build Lab 中实施了用于一个欧洲 BMW 市场的监管报告原型。
要了解有关 AWS Data Lab 如何帮助您将想法转化为解决方案的更多信息,请访问 AWS Data Lab。
特别感谢为 Design Lab 和 Build Lab 的成功做出贡献的所有人:Lionel Mbenda/Mario Robert Tutunea、Marius Abalarus、Maria Dejoie。
关于作者
 Martin Zoellner 是 BMW Group 的 IT 专家。他在该项目中担任 DevOps 和 ETL/SW 架构的主题专家。
Martin Zoellner 是 BMW Group 的 IT 专家。他在该项目中担任 DevOps 和 ETL/SW 架构的主题专家。
 Thomas Ehrlich 是一个欧洲 BMW 市场的监管报告应用程序的功能维护经理。
Thomas Ehrlich 是一个欧洲 BMW 市场的监管报告应用程序的功能维护经理。
 Veronika Bogusch 是 BMW 的 IT 专家。她通过云数据中心启动了 Financial Services Batch Integration Layer 的重建。提取的数据资产是本文中介绍的监管报告使用案例的基础。
Veronika Bogusch 是 BMW 的 IT 专家。她通过云数据中心启动了 Financial Services Batch Integration Layer 的重建。提取的数据资产是本文中介绍的监管报告使用案例的基础。
 George Komninos 是 Amazon Web Services(AWS)Data Lab 的解决方案架构师。他帮助客户将他们的想法转化为生产就绪型数据产品。在加入 AWS 之前,他在 Alexa Information Domain 担任了三年的数据工程师。工作之余,George 是一名足球迷,他支持世界上最伟大的球队 Olympiacos Piraeus 队。
George Komninos 是 Amazon Web Services(AWS)Data Lab 的解决方案架构师。他帮助客户将他们的想法转化为生产就绪型数据产品。在加入 AWS 之前,他在 Alexa Information Domain 担任了三年的数据工程师。工作之余,George 是一名足球迷,他支持世界上最伟大的球队 Olympiacos Piraeus 队。
 Rahul Shaurya 是 AWS Professional Services 高级大数据架构师。他帮助客户并与企业客户密切合作,在 AWS 上构建数据湖和分析应用程序。工作之余,Rahul 喜欢和他的狗 Barney 一起散步。
Rahul Shaurya 是 AWS Professional Services 高级大数据架构师。他帮助客户并与企业客户密切合作,在 AWS 上构建数据湖和分析应用程序。工作之余,Rahul 喜欢和他的狗 Barney 一起散步。