1.前言
AWS Well-Architected Framework 描述了用于在云中设计和运行工作负载的关键概念、设计原则和架构最佳实践。其中可持续性支柱作为目前 Well-Architected Framework 中的最新一员侧重于减少运行的云工作负载对环境的影响。在正确的时间以正确的数量提供正确的资源,以满足明确定义的业务需求。以Reuse,Recycle,Reduce,Rearchitect 四个方面为准则构建最佳架构。本系列博客将以在EKS上的部署Flink作业为例,通过 Karpenter, Spot, Graviton 等技术,遵循Reuse,Recycle,Reduce,Rearchitect 四大原则,从零开始构建最佳架构。

在上一篇博客中,我们介绍了遵循Reuse,Recycle原则,通过容器化应用和 Spot 实例实现云应用的交付和优化,结合 Karpenter 弹性伸缩工具最大限度地提高利用率和资源效率。在这一篇博客中,我们将:
- 遵循 Rearchitect 原则,引入 Graviton,实现从 x86 到 arm 架构的转变的同时,进一步推进成本节省和持续的基础设施优化。
- 亚马逊云科技设计的 AWS Graviton 处理器为 Amazon EC2 中运行的云工作负载提供最佳性价比。与当前一代基于 x86 的实例相比,采用亚马逊云科技 Graviton2 处理器的通用可突发性能型(T4g)、通用型(M6g)、计算优化型(C6g) 和内存优化型(R6g、X2gd)EC2 实例,及其具有基于 NVMe 的 SSD 存储的变体,为广泛的工作负载(如应用程序服务器、微服务、视频编码、高性能计算、电子设计自动化、压缩、游戏、开源数据库、内存缓存和基于 CPU 的机器学习推理)提供高达 40% 的性价比提升。除此之外,Graviton 提供在Amazon EC2 实例家族中每瓦能源使用的最佳性能,详细的 SPECint2017 benchmark 数据请参考下图:

- 遵循 Reduce 原则,除了EKS集群层面的优化,我们可以借助 Kubecost 工具,下沉到应用级别,深入地监控 Kubernetes 成本资源级别的成本。不仅提升 Kubernetes 集群的成本可见性,还提示节省成本的机会。例如帮助您定位未使用的存储卷、过度配置的副本或废弃的工作负载等。
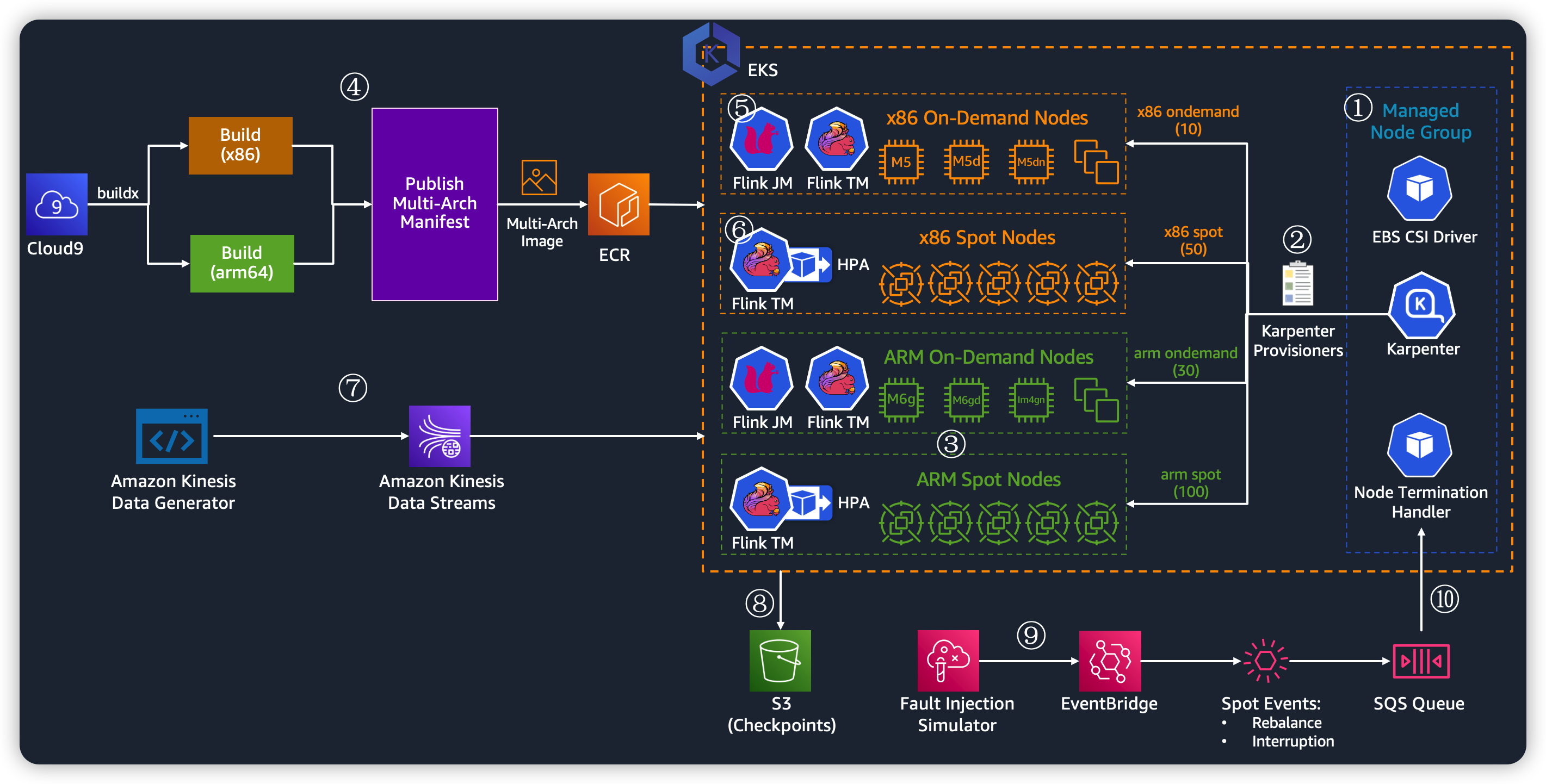
实验架构回顾:

架构概要说明:
1. 创建 EKS 集群时,添加一个托管按需节点组(默认一个节点),用于部署系统组件例如 EBS CSI 驱动程序等。
2. 借助 Karpenter 动态拉起 Flink 作业需要的计算资源,通过配置多个Provisioner,每个 Provisioner 设置不同 weight,实现精细化协同控制。
3. ARM 节点主动打上 Taints,配合使用 Tolerations,以确保 Flink 作业调度到合适的节点上。
4. 利用 docker buildx 工具一键打包 Multi-Arch 镜像并推送到镜像仓库。
5. Flink Job Manager (Flink JM) 利用 nodeSelector 主动调度到由按需节点(包括部署系统组件的按需节点组和 Karpenter拉起的节点)。
6. Flink Task Manager (Flink TM) 默认不加任何限定条件(nodeSelector/ nodeAffinity),并且配置HPA(基于CPU)。当资源不够时,由 Provisioner 按优先级协调拉起合适节点。
7. 利用 Kinesis Data Generator 生成大量模拟数据,打到 Kinesis Data Stream 数据。随着数据的增加,配置了 HPA 的 Task Manager 自动弹出更多Pod。
8. Flink 作业启用检查点,并将作业检查点数据写入 S3,从而允许 Flink 保存状态并具备容错性。
9. 使用 Fault Injection Simulator 模拟 Spot 回收事件。
10. Node Termination Handler 配合 Spot,让应用运行更平稳。
上一篇我们已经搭建好 EKS 集群,并将 Flink 作业运行在 x86 节点上。接下来首先通过切换到基于 Graviton 的实例来提高计算工作负载的能效。同时综合运用 Karpenter 的优先级策略,实现对 Flink 作业计算资源的精细化管理。

从CPU架构和容量类型,我们一共设置了四个Provisioner,注意为保证部署在按需节点上的Job Manager的高可用性,我们仅对*-spot-provisioner 启用consolidation:
| Provisioner |
优先级 |
Taint(污点) |
Consolidation |
| arm-spot-provisioner |
100 |
cpu-architecture:arm64:NoSchedule |
Yes |
| x86-spot-provisioner |
50 |
无 |
Yes |
| arm-ondemand-provisioner |
30 |
cpu-architecture:arm64:NoSchedule |
No |
| x86-ondemand-provisioner |
10 |
无 |
No |
注意:不能保证 Karpenter 在特定要求下始终选择最高优先级的Provisioner。例如有2种场景:
1. 遵循上一篇提到的“Reuse”原则,如果现有容量可用,kube-scheduler 将直接调度 pod,不会触发 Karpenter 拉起新节点。
2. 根据 Karpenter 执行 pod 批处理和 bin 打包的方式,如果一个 pod 无法使用最高优先级的配置器进行调度,它将强制使用较低优先级的配置器创建一个节点,这可能允许该批次中的其他 pod 也可以在该节点上进行调度。
如果您希望保持简单,不要求最大化已有托管节点组利用率,对统一的 capacity 类型标签(eks.amazonaws.com/capacityType)也没有要求,可以设置Flink 作业只使用 Kaprenter 节点。Karpenter 已经内置了优先选择 Spot 然后按需的机制,这样初始只需配置二个 Provisioner (x86/arm)。对于 Flink Job Manager 等必须使用按需实例的任务,只需利用 nodeSelector 通过原生标签 karpenter.sh/capacity-type 指定即可。后期如果作业容器镜像已经都是 multi-arch,则可以进一步将x86和arm实例放在同一个 Provisioner 中,Karpenter会分别按照spot capacity优先、按需成本优先的原则自动选择x86和arm。您可以权衡考虑,如果单一 Provisioner可以满足需求,则可以大幅简化目前多个 Provisioner的配置和选择。
2.构建多CPU架构镜像
2.1 准备buildx工具
打开 Cloud9 控制台:
https://us-east-1.console.thinkwithwp.com/cloud9/home?region=us-east-1。
进入到IDE环境,前面一篇已经安装好docker buildx工具,如果有问题请下载prepareCloud9IDE.sh:
wget https://raw.githubusercontent.com/BWCXME/cost-optimized-flink-on-kubernetes/main/prepareCloud9IDE.sh
然后打开查看 buildx 部分,复制到命令行手动安装:
2.2 配置build
创建并使用flink-build:
docker buildx create --name flink-build --use
docker buildx inspect --bootstrap
docker buildx ls
2.3 一键打包多CPU架构镜像
首先进入代码目录:
cd ~/environment/flink-demo
登录仓库:
aws ecr get-login-password --region ${AWS_REGION} | docker login --username AWS --password-stdin ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com
借助buildx插件,一条命令同时编译、打包、推送x86和arm架构镜像:
docker buildx build --platform linux/amd64,linux/arm64 --tag ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:latest --push .
查看 Dockerfile,内容如下所示:
FROM maven:3.8.6-jdk-8-slim AS builder
COPY src/ /home/app/src
COPY pom.xml /home/app/
RUN ls -l /home/app
RUN mvn -f /home/app/pom.xml clean package -Dflink.version=1.15.1
FROM flink:1.15.1
RUN mkdir -p $FLINK_HOME/usrlib
COPY --from=builder /home/app/target/aws-kinesis-analytics-java-apps-1.0.jar $FLINK_HOME/usrlib/aws-kinesis-analytics-java-apps-1.0.jar
RUN mkdir $FLINK_HOME/plugins/s3-fs-hadoop
COPY /lib/flink-s3-fs-hadoop-1.15.1.jar $FLINK_HOME/plugins/s3-fs-hadoop/
如果您要更改基础镜像maven 或 flink的版本,请确保指定tag下有arm的版本,不然buildx会报错。
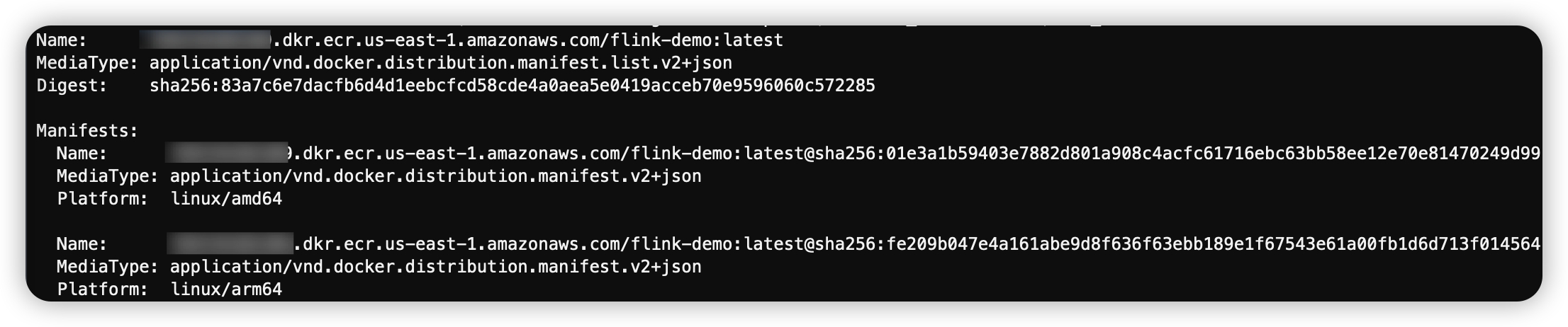
推送完成后,检查镜像信息:
docker buildx imagetools inspect ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:latest
返回类似如下:

简单3步,Flink作业的ARM镜像就打好了,即不用更改Dockerfile,也不用单独设置Tag。
2.4 构建自定义版本的 Flink多CPU架构镜像
在 Docker Hub 上 Flink 的官方镜像仓库中只有 1.14 及以上的版本有支持 arm64/v8 即支持 Graviton 的镜像,如前面所说的如果镜像不支持arm64/v8,那么通过 buildx 打包的时候会报错。但是在有些场景下,客户依然想要使用 1.13 版本的 Flink, 或者希望使用除了 openjdk 以外的其他 JDK,比如针对 Graviton 优化的 Amazon Corretto JDK,这时候就需要我们自己编译构建一个自定义的 Flink 多CPU架构镜像。
作为示例,下面我们构建一个 1.13 版本并且基于 Amazon Corretto 11 JDK 的自定义镜像,并且同样构建成多CPU架构镜像。
因为涉及编译 arm64 架构的 Flink, 这里推荐启动一台Amazon linux 2 操作系统的 Graviton 实例(比如 t4g.large)编译构建 Flink 镜像。
在 Graviton 实例上拉取代码:
sudo yum groupinstall "Development Tools"
git clone -b DIYflink https://github.com/BWCXME/cost-optimized-flink-on-kubernetes flink-private-demo
cd flink-private-demo
参考文档【2】,使用脚本构建1.13 版本的 Flink
sudo sh build_flink.sh -f 1.13 -j 11 -s 2.11
上述命令会直接构建一个支持 Graviton 的1.13 版本的Flink 镜像,然后需要将镜像上传到私有镜像仓库中,并且打上自定义 tag,后面会使用这个镜像构建多 CPU架构镜像。
转到 cloud9 开发环境下,拉取代码:
cd ~/environment
git clone -b DIYflink https://github.com/BWCXME/cost-optimized-flink-on-kubernetes flink-private-demo
cd flink-private-demo
使用上面的私有仓库地址和 tag代替 Dockerfile中的 <private_repo_address>和<tag>
将 Amazon Corretto 11 JDK 的压缩文件下载到当前目录下
wget https://corretto.aws/downloads/latest/amazon-corretto-11-aarch64-linux-jdk.tar.gz
接下来使用 buildx 构建多 CPU架构镜像
登录仓库:
aws ecr get-login-password --region ${AWS_REGION} | docker login --username AWS --password-stdin ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com
借助buildx插件,一条命令同时编译、打包、推送x86和arm架构镜像:
docker buildx build --platform linux/amd64,linux/arm64 --tag ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:private --push .
在后续的部署过程中,可以用 tag 为private 的 flink-demo 镜像代替默认的 latest达到部署自定义 JDK 和 Flink 版本的目的,结果如下图所示:


3.部署ARM Provisioner
当我们有一个具有多架构 vcpus 的集群时,我们可以配合使用k8s里的 Taints 和 Tolerations,以确保 pod 调度到合适的节点上。
例如,默认我们可以给 gravtion 节点都打上 taint,确保不会有 x86 应用程序部署到 graviton 节点上。 只有经过测试,加上了 toleration 的应用才可以调度到 gravtion 节点。
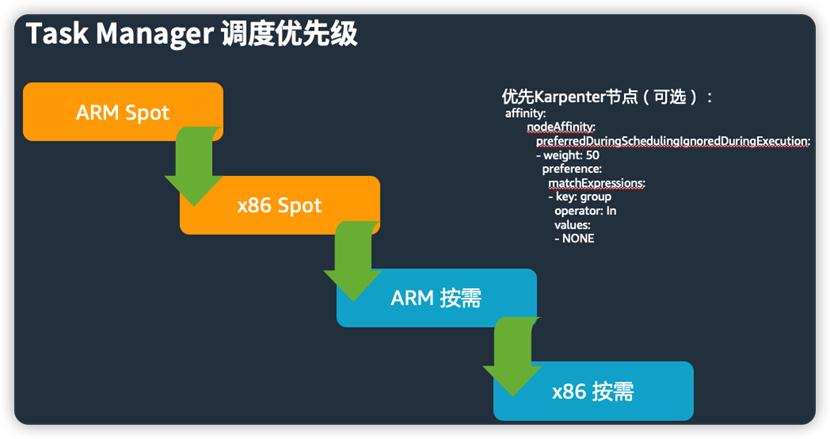
同样我们为arm节点,分别设置 Spot和按需 Provisioner。一个能容忍“cpu-architecture:arm64:NoSchedule”污点的应用,尝试的优先顺序依次如下:
1. arm-spot-provisioner (100), arm 和 spot 两大成本优化利器的组合拳
2. x86-spot-provisioner (50),如果arm的spot资源不足,退回到 x86 spot
3. arm-ondemand-provisioner (30),如果spot资源总体紧张,再退到arm 按需
4. x86-ondemand-provisioner (10),最后由x86按需兜底
3.1 筛选机型
借助ec2-instance-selector 工具快速搜索arm机型:
ec2-instance-selector --memory 16 --vcpus 4 --cpu-architecture arm64 --gpus 0
返回类似如下:
im4gn.xlarge
m6g.xlarge
m6gd.xlarge
t4g.xlarge
3.1 创建ARM Provisioner
创建 arm provisioner 配置文件 provisioner-arm.yaml:
cat > provisioner-arm.yaml <<EOF
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: arm-spot-provisioner
spec:
consolidation:
enabled: true
ttlSecondsUntilExpired: 2592000 # 30 Days = 60 * 60 * 24 * 30 Seconds;
weight: 100 # 值越大,优先级越高
taints:
- key: cpu-architecture
value: "arm64"
effect: NoSchedule
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m6g.xlarge", "m6gd.xlarge", "im4gn.xlarge"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["${AWS_REGION}a", "${AWS_REGION}b", "${AWS_REGION}c"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64"]
kubeletConfiguration:
systemReserved:
cpu: 1
memory: 5Gi
ephemeral-storage: 10Gi
maxPods: 20
limits:
resources:
cpu: 1000
memory: 2000Gi
providerRef: # optional, recommended to use instead of provider
name: flink
labels:
eks.amazonaws.com/capacityType: 'SPOT'
cpu-architecture: arm64
network: private
group: 'NONE'
---
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: arm-ondemand-provisioner
spec:
consolidation:
enabled: false
ttlSecondsAfterEmpty: 60
ttlSecondsUntilExpired: 2592000 # 30 Days = 60 * 60 * 24 * 30 Seconds;
weight: 30 # 值越大,优先级越高
taints:
- key: cpu-architecture
value: "arm64"
effect: NoSchedule
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m6g.xlarge", "m6gd.xlarge", "im4gn.xlarge"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["${AWS_REGION}a", "${AWS_REGION}b", "${AWS_REGION}c"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64"]
kubeletConfiguration:
systemReserved:
cpu: 1
memory: 5Gi
ephemeral-storage: 10Gi
maxPods: 20
limits:
resources:
cpu: 1000
memory: 2000Gi
providerRef:
name: flink
labels:
eks.amazonaws.com/capacityType: 'ON_DEMAND'
cpu-architecture: arm64
network: private
group: 'NONE'
EOF
执行部署:
k apply -f provisioner-arm.yaml
检查部署:
k apply -f provisioner-arm.yaml
4.部署Flink到Graviton节点
4.1 清理原x86部署
如果原x86还未删除,请先执行:
cd ~/environment/flink-demo/x86
k delete -f .
cd ..
4.2 提交任务(YAML)
您即可以通过明确定义YAML文件来部署,也可以利用命令行快捷部署。这里为了方便理解,我们主要演示基于完整的YAML文件部署,您也可以参考后面一节的命令行提交方式。
准备目录:
cd ~/environment/flink-demo/
mkdir arm
cd arm
生成配置文件:
cat > flink-configuration-configmap.yaml <<EOF
apiVersion: v1
kind: ConfigMap
metadata:
name: flink-config
labels:
app: flink
data:
flink-conf.yaml: |+
kubernetes.cluster-id: flink-demo
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
high-availability.storageDir: s3a://${FLINK_S3_BUCKET}/recovery
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 100000
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 1
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
queryable-state.proxy.ports: 6125
jobmanager.memory.process.size: 2048m
taskmanager.memory.process.size: 2048m
scheduler-mode: reactive
parallelism.default: 4
rest.flamegraph.enabled: true
log4j-console.properties: |+
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = ConsoleAppender
rootLogger.appenderRef.rolling.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = DEBUG
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
# Log all infos to the console
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = \${sys:log.file}
appender.rolling.filePattern = \${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
EOF
我们增加tolerations 配置,使得Job Manager能够容忍arm64:

生成jobmanager部署文件:
cat > jobmanager-application-ha.yaml <<EOF
apiVersion: batch/v1
kind: Job
metadata:
name: flink-jobmanager
spec:
parallelism: 1 # Set the value to greater than 1 to start standby JobManagers
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
serviceAccountName: ${FLINK_SA}
nodeSelector:
'eks.amazonaws.com/capacityType': 'ON_DEMAND'
tolerations:
- key: "cpu-architecture"
operator: "Equal"
value: "arm64"
effect: "NoSchedule"
restartPolicy: OnFailure
containers:
- name: jobmanager
image: ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:latest
imagePullPolicy: Always
env:
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
args: ["standalone-job", "--host", "\$(POD_IP)","--job-classname", "com.amazonaws.services.kinesisanalytics.S3StreamingSinkJob","--inputStreamName", "${FLINK_INPUT_STREAM}", "--region", "${AWS_REGION}", "--s3SinkPath", "s3a://${FLINK_S3_BUCKET}/data", "--checkpoint-dir", "s3a://${FLINK_S3_BUCKET}/recovery"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob-server
- containerPort: 8081
name: webui
livenessProbe:
tcpSocket:
port: 6123
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
serviceAccountName: flink-service-account # Service account which has the permissions to create, edit, delete ConfigMaps
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
EOF
在上述的配置中,通过nodeSelector,强制往按需节点上调度,同时遵循“Reuse”原则,托管节点组或者Karpenter拉起的按需节点都可以。如果您希望限定到没有自动伸缩组的节点(由Karpenter拉起),请手动添加:
nodeSelector:
'group': 'NONE'

生成taskmanager部署文件:
cat > taskmanager-job-deployment.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
spec:
replicas: 1
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
serviceAccountName: flink-service-account
tolerations:
- key: "cpu-architecture"
operator: "Equal"
value: "arm64"
effect: "NoSchedule"
containers:
- name: taskmanager
image: ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:latest
imagePullPolicy: Always
resources:
requests:
cpu: 250m
memory: "4096Mi"
limits:
cpu: 500m
memory: "8192Mi"
env:
args: ["taskmanager"]
ports:
- containerPort: 6122
name: rpc
- containerPort: 6125
name: query-state
livenessProbe:
tcpSocket:
port: 6122
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf/
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
EOF
我们遵循“Reuse”原则,上述配置中,没有添加nodeSelector或nodeAffinity,优先利用现有计算资源,不够时再按照前面配置的provisioner优先级,依次尝试直到成功拉起资源。

如果您需要限定托管按需节点组优先部署集群管理相关组件,或者稳定性要求高的应用,可以参考以下配置,让 Task Manager 优先运行在 Karpenter 拉起的节点上(如果需要,请手动添加到前面生成的 taskmanager-job-deployment.yaml):
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 50
preference:
matchExpressions:
- key: group
operator: In
values:
- NONE
准备服务部署文件:
cat > jobmanager-svc.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager
spec:
type: ClusterIP
ports:
- name: rpc
port: 6123
- name: blob-server
port: 6124
- name: webui
port: 8081
selector:
app: flink
component: jobmanager
---
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager-web
annotations:
service.beta.kubernetes.io/aws-load-balancer-security-groups: "${EKS_EXTERNAL_SG}"
spec:
type: LoadBalancer
ports:
- name: web
port: 80
targetPort: 8081
selector:
app: flink
component: jobmanager
EOF
注意这里为了方便测试,使用LoadBalancer将服务暴露出来,并且绑定了安全组ExternalSecurityGroup,请确保:
- 这个安全组允许您的本机IP访问80端口。
- 如果您修改了暴露端口80,例如用的8081,请相应在安全组中放开8081端口。
执行部署(请先确认在arm目录下):
检查部署:
当Pod都拉起来以后,检查机器,利用预设好的别名:

如我们的预期,分别拉起了一台Graviton的按需和Spot实例,实现了非常好的性价比。
检查机器的taints:
kubectl get nodes -o json | jq '.items[].spec.taints'
获取服务地址:
k get svc flink-jobmanager-web
拿到地址后在浏览器中打开:

一切正常,至此我们很轻松的就将一个Flink作业从x86迁移到了arm。
4.3 提交任务(命令行)
您也可以使用命令行提交任务,目前flink 1.13+以上 支持pod模板,我们可以自定义JM跟TM的启动方式。这允许直接支持 Flink Kubernetes 配置选项不支持的高级功能。
定义任务名称:
export kubernetes_cluster_id=your-flink-job-name
使用参数 kubernetes.pod-template-file 指定包含 pod 定义的本地文件。它将用于初始化 JobManager 和 TaskManager。
指定 job manager 运行在按需节点上并且能够容忍 arm64:
cat > arm-jobmanager-pod-template.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: jobmanager-pod-template
spec:
nodeSelector:
'eks.amazonaws.com/capacityType': 'ON_DEMAND'
tolerations:
- key: "cpu-architecture"
operator: "Equal"
value: "arm64"
effect: "NoSchedule"
EOF
配置 task manager能够容忍 arm64:
cat > arm-taskmanager-pod-template.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: taskmanager-pod-template
spec:
tolerations:
- key: "cpu-architecture"
operator: "Equal"
value: "arm64"
effect: "NoSchedule"
containers:
# Do not change the main container name
- name: flink-main-container
env:
- name: HADOOP_USER_NAME
value: "hdfs"
EOF
使用命令行提交任务, 注意指定参数 kubernetes.pod-template-file.jobmanager 和 kubernetes.pod-template-file.taskmanager:
flink run-application -p 2 -t kubernetes-application \
-Dkubernetes.cluster-id=${kubernetes_cluster_id} \
-Dkubernetes.container.image=${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:latest \
-Dkubernetes.container.image.pull-policy=Always \
-Dkubernetes.jobmanager.service-account=flink-service-account \
-Dkubernetes.pod-template-file.jobmanager=./arm-jobmanager-pod-template.yaml \
-Dkubernetes.rest-service.exposed.type=LoadBalancer \
-Dkubernetes.rest-service.annotations=service.beta.kubernetes.io/aws-load-balancer-security-groups:${EKS_EXTERNAL_SG} \
-Dhigh-availability=org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory\
-Dhigh-availability.cluster-id=${kubernetes_cluster_id} \
-Dhigh-availability.storageDir=s3://${FLINK_S3_BUCKET}/recovery \
-Dstate.savepoints.dir=s3://${FLINK_S3_BUCKET}/savepoints/${kubernetes_cluster_id} \
-Dkubernetes.taskmanager.service-account=flink-service-account \
-Dkubernetes.taskmanager.cpu=1 \
-Dtaskmanager.memory.process.size=4096m \
-Dtaskmanager.numberOfTaskSlots=2 \
-Dkubernetes.pod-template-file.taskmanager=./arm-taskmanager-pod-template.yaml \
local:///opt/flink/usrlib/aws-kinesis-analytics-java-apps-1.0.jar \
--inputStreamName ${FLINK_INPUT_STREAM} --region ${AWS_REGION} --s3SinkPath s3://${FLINK_S3_BUCKET}/data --checkpoint-dir s3://${FLINK_S3_BUCKET}/recovery
4.4 配置HPA
首先安装 metrics-server:
k apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
检查部署:
k get apiservice v1beta1.metrics.k8s.io -o json | jq '.status'
Autoscaling 基于Fink的“Reactive Mode”。通过设置Horizontal Pod Autoscaler,监控 CPU 负载并进行相应的缩放:
k autoscale deployment flink-taskmanager --min=1 --max=25 --cpu-percent=35
检查当前 Task Manager Pod数量:
kgp -l component=taskmanager
目前只有一个:

5.集成测试
我们在上一篇中已经设置好输入/输出,接下来我们模拟生成数据,测试整个端到端流程。

5.1 配置数据生成器
这里示例,我们使用Kinesis Data Generator,打https://awslabs.github.io/amazon-kinesis-data-generator/web/help.html 页面。
点击通过 CloudFormation 配置测试用户(跳转后注意切换到自己所在区域):

下一步设置用户名和密码,其他参数保持默认,创建即可。
接着从 CloudFormation 输出堆栈里找到 URL,跳转到Kinesis Data Generator页面。

输入前面创建堆栈时设置的用户名和密码完成登录:

5.2 准备数据模板
示例模板如下:
{"EVENT_TIME": "{{date.now("dddd, MMMM Do YYYY, h:mm:ss a")}}",
"TICKER": "{{random.arrayElement(
["ABCD", "CDEF", "IJKL", "MNOP", "QRST"]
)}}",
"PRICE": "{{random.number(
{
"min":500,
"max":1000
}
)}}",
"ID": "{{random.uuid}}"
}
5.3 注入测试数据
切到所在区域,然后选择之前准备的输入流,替换模板后,点击发送数据:
注意:请确保 Kinesis Data Generator 仍然保持在登录状态,开始发送后先切到 Kinesis 控制台检查监控指标,确保有数据写入。

观察HPA变化:
k get hpa flink-taskmanager -w

观察Task Manager Pod 数量:
kgp -l component=taskmanager

6.混沌测试
您可以借助AWS Fault Injection Simulator 模拟Spot事件,例如提前5分钟发出通知,然后观察节点变化和Flink的行为。
6.1 配置FIS模板
打开Fault Injection Simulator控制台https://us-east-1.console.thinkwithwp.com/fis/home?region=us-east-1。
创建新实验,参数如下:
- 实验名称,例如“flink-spot-experiment”
- Action 名称:spot-interruptions
- Action 类型:aws:ec2:send-spot-instance-interruptions
- 提前通知时间:时间在2~15分钟之内,例如设置5分钟
- Target标签筛选:Resource tags, filters and parameters
- Key: karpenter.sh/provisioner-name
- Value: arm-spot-provisioner
- Target 资源筛选:Resource filters
- Target选择模式:
6.2 监控Job Manager日志
可以通过kubectl命令:
k logs -f <job-manager-pod-name>
或者利用预装的k9s工具进行跟踪:
然后选择 Job Manager,按下 “l”键查看日志:
6.3 启动实验
回到FIS控制台,启动前面创建的实验。然后详细查看 JobManager 日志,发现 JobManager 恢复作业的过程:

如果出现中断,则将使用检查点数据重新启动 Flink 应用程序。 JobManager 将恢复作业。受影响的节点将被自动替换。
7.成本可见性
前面我们主要在集群层面进行优化,下面我们将视角切到应用/作业层面,遵循“Reduce”原则,将成本管理进行到底。
从2022年8月25号开始,Amazon EKS 客户可以部署 EKS 优化且免费的 Kubecost 包,以实现集群成本可见性。通过 Kubecost 可以查看按 Kubernetes 资源(包括 pod、节点、命名空间、标签等)细分的成本。Kubernetes 平台管理员和财务负责人可以使用 Kubecost 可视化其 Amazon EKS 费用明细和分配成本等。
Kubecost 还能根据其基础设施环境和集群内的使用模式获得定制的成本优化建议,例如设置合适的节点规模,容器资源申请建议等。
检查可安装版本:
https://gallery.ecr.aws/kubecost/cost-analyzer
准备安装参数:
cat > kubecost-values.yaml <<EOF
service:
type: LoadBalancer
port: 80
targetPort: 9090
# nodePort:
annotations:
service.beta.kubernetes.io/aws-load-balancer-security-groups: "${EKS_EXTERNAL_SG}"
EOF
这里为方便演示,使用LoadBalancer将服务暴露出来,并且绑定了安全组ExternalSecurityGroup,请确保:
- 这个安全组允许您的本机IP访问80端口。
- 如果您修改了暴露端口80,例如用的9090,请相应在安全组中放开9090端口。
安装kubecost(以1.96.0为例):
helm upgrade -i kubecost oci://public.ecr.aws/kubecost/cost-analyzer --version 1.96.0 \
--namespace kubecost --create-namespace \
-f kubecost-values.yaml
获取服务地址:
k get svc kubecost-cost-analyzer -n kubecost
拿到地址后在浏览器中打开,查看节省建议类似如下:
如果提示还在收集数据,可以等待15分钟左右再刷新页面:
Kubecost is collecting data. Data should be ready for viewing within 15 minutes.

总结
在本文中,我们遵循AWS Well-Architected Framework的可持续性支柱,从Rearchitect的角度,我们介绍了通过buildx 工具,一条命令同时编译、打包、推送x86和arm架构镜像,平滑的实现从 x86 实例迁移到 Graviton实例,同时通过自定义 Flink 镜像让使用者可以自由选择 Flink, Java, Scala 等组件的版本以适应业务需求。从Reduce 角度,通过部署 Kubecost 实现成本管理和持续的基础设施优化。
参考文档
【1】Optimizing Apache Flink on Amazon EKS using Amazon EC2 Spot Instances:
https://thinkwithwp.com/blogs/compute/optimizing-apache-flink-on-amazon-eks-using-amazon-ec2-spot-instances/
【2】https://github.com/frego-dev/flink-docker-image-build
本篇作者