亚马逊AWS官方博客
使用 AWS Glue 提取 Salesforce.com 中的数据并使用 Amazon Athena 进行分析
准备数据
我注册了一个免费的 Salesforce.com 账户,该账户带有一些记录示例,其中填充了许多 Salesforce.com 对象。您可以使用您的组织的开发测试 Salesforce.com 账户,并通过修改 AWS Glue 代码中的 SOQL 查询同时从多个对象中提取数据。为了使查询简单易懂,这里在从这些对象中提取数据时仅使用 Account 对象。
为了演示如何使用Amazon Athena把 Salesforce.com数据与另一个系统的数据结合在一起,我们需要创建一个示例数据文件,显示来自订单管理系统的订单。
设置 AWS Glue 作业
使用开源 springml 库让 Apache Spark 可以连接 Salesforce.com 数据源。该库具有许多方便的功能,使您可以使用 Apache Spark 框架读取、写入和更新 Salesforce.com 对象。
您可以从 springml GitHub 下载代码并编译 成jar,也可以从 Maven 存储库中下载完整的依赖。将这些 JAR 文件上传到 S3 存储桶,并记下每个文件的完整路径。
在 AWS 管理控制台中,在要运行服务的区域中选择 AWS Glue。选择作业,添加作业。填写必要信息,并按照向导进行操作。
在安全配置、脚本库和作业参数(可选)部分下,对于从属 JAR 路径,列出前面列出的四个 JAR 文件的路径,以逗号分隔。
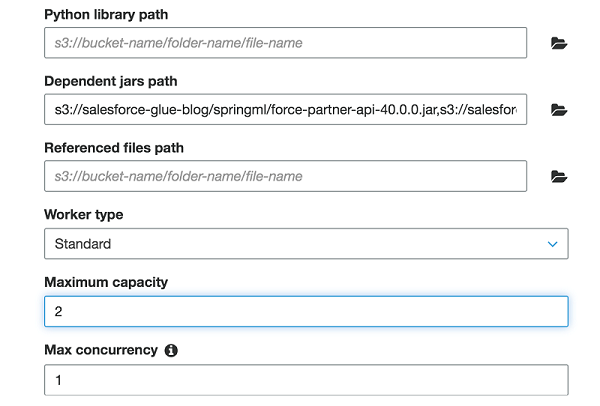
在此作业中,我将 Maximum Capacity 设置为“2”。 该字段定义运行此作业时系统可分配的 AWS Glue 数据处理单元 (DPU) 的数量。DPU 是处理能力的相对度量,一个DPU由四个具有计算能力的 vCPU 和 16 GB 内存组成。指定 Apache Spark ETL 作业时,可以分配 2–100 个 DPU。默认值为 10 个 DPU。
执行 AWS Glue 作业以从 Salesforce.com 对象提取数据
以下 Scala 代码从 Salesforce.com 的 Account 对象中提取一些字段,并生成一个以Apache Parquet格式存储在S3的表。
该代码依赖于一些关键组件:
该代码示例建立 Salesforce.com 连接,提交对Account对象的 SOQL兼容查询语句,并将返回的记录加载到 Spark DataFrame 中。不要忘记使用您的 Salesforce.com 用户名替换 username,使用密码和配置文件的安全令牌的组合替换 password+securitytoken。
最佳实践建议使用 AWS Secrets Manager 存储和检索密码,而不是明文写在代码里。为了简单起见,在此示例中将其保留为明文。
请记住,此为简单查询,仅返回少量记录。对于大量数据,您可能希望限制查询返回的结果,或使用其他技术,例如批量查询和分块。查看 springml 页面,以了解有关 Salesforce.com 支持的功能的更多信息。
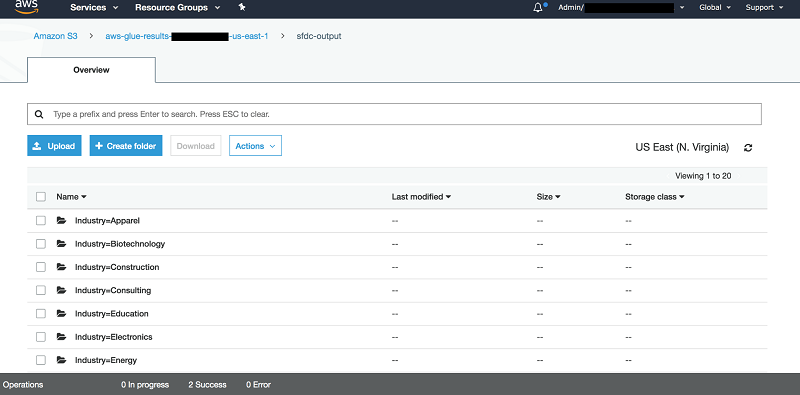
此代码会将所有内容写入 S3 存储桶。在此示例中,我们按照 Industry 汇总数据。因此,我们按照 Industry 字段对数据进行分区。
另外,S3数据将以 Parquet 格式存储。Athena 会根据每个查询扫描的数据量向您收费。对数据进行分区、压缩数据或将其转换为 Parquet 等列式存储格式,可以节省成本并获得更好的性能。
在 AWS Glue 中运行此代码后,可以转到接收器指向的 S3 存储桶,并找到类似以下结构的内容:
使用 Athena 查询数据
在代码以正确的分区和格式将 Salesforce.com 数据放入 S3 存储桶后,AWS Glue 就可以对数据集进行爬取。它会在 AWS Glue 数据目录中创建适当的表格结构。等待 AWS Glue 完成表的创建。然后,Athena 可以查询该表并将其与目录中的其他表联接。
首先,使用 AWS Glue 爬网程序发现先前存储在 S3 存储桶中的 Salesforce.com 的 Account 数据。有关如何使用爬网程序的详细信息,请参阅填充 AWS Glue 数据目录。
在此示例中,将爬网程序指向存储 Salesforce.com 的 Account 数据的 S3 输出前缀,然后运行它。爬网程序在最终停止之前会创建一个新的目录表。
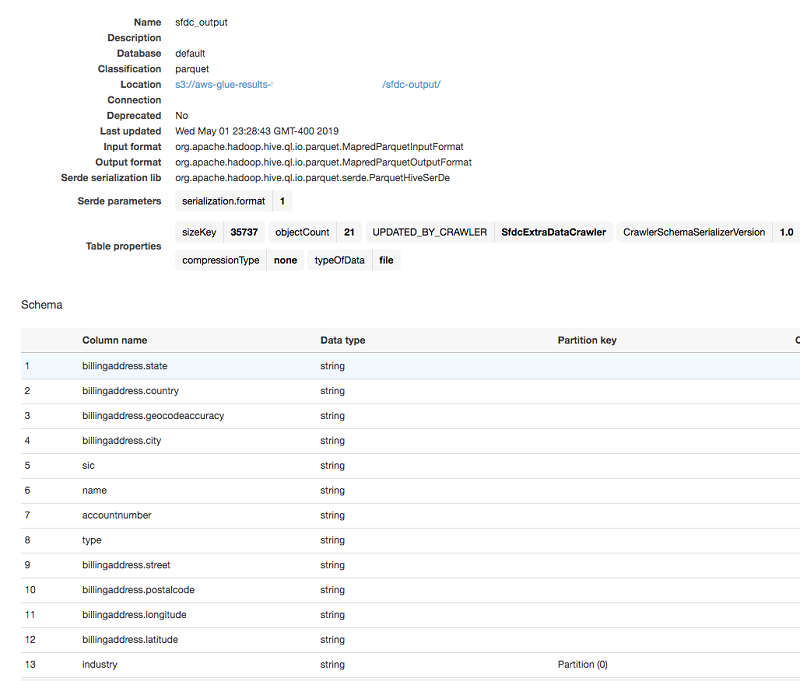
AWS Glue 数据目录表会自动捕获所有使用的列名、类型和分区列,并将所有内容以 Parquet 文件格式存储在 S3 存储桶中。现在可以使用 Athena 查询该表了。在该表上进行简单的 SELECT 查询,可显示 S3 存储桶中的数据的扫描结果。

现在,Salesforce.com 数据可供 Athena 查询了。对于此示例,将此数据与来自此 S3 中的示例订单管理系统的订单样本相结合。在 AWS Glue 爬网程序完成对示例订单数据的编目后,Athena 就可以对其进行查询。
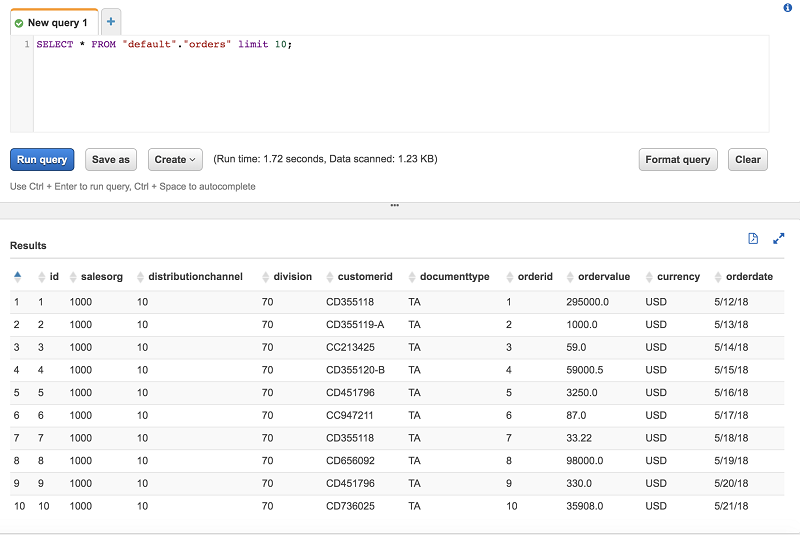
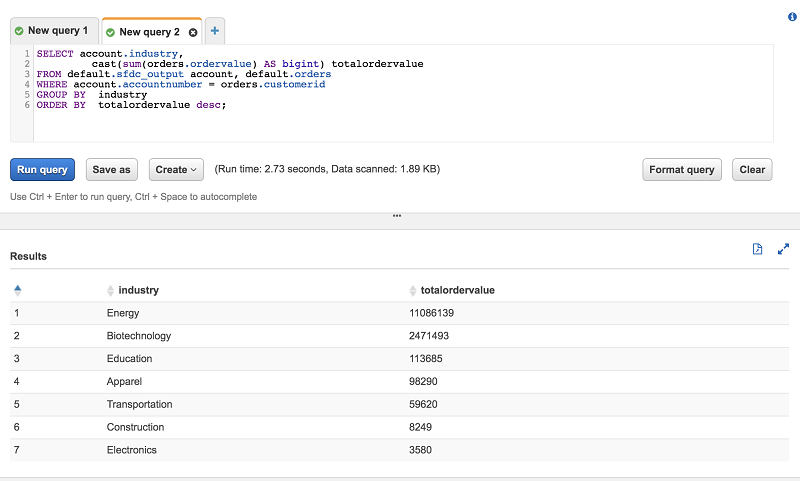
最后,使用 Athena 在聚合查询中联接两个表。
小结
在本文中,我展示了使用 AWS Glue 和 Apache Spark 提取 Salesforce.com 中的任何对象数据,并将其保存到 S3 的简单例子。然后,您可以在 AWS Glue 数据目录中对 S3 数据进行编目,从而允许 Athena 对其进行查询。通过这种方式,您可以轻松地将 Salesforce 数据合并到基于 AWS 的数据湖中。
如果您有任何意见或反馈,请在下面留言。
关于作者

Behram Irani 是 Amazon Web Services 的数据架构师。