亚马逊AWS官方博客
在对话式体验中探索生成式人工智能:Amazon Lex、Langchain 和 SageMaker Jumpstart 简介
在当今快节奏的世界里,客户希望企业提供快速高效的服务。但是,当咨询量超过了处理这些咨询所需的人力资源时,提供优质客户服务就会面临巨大挑战。然而,借助由大型语言模型(LLM)支持的生成式人工智能(生成式 AI)的进步,企业可以应对这一挑战,同时提供个性化和高效的客户服务。
生成式人工智能聊天机器人因其模仿人类智力的能力而声名鹊起。不过,与面向任务的机器人不同,这些机器人使用 LLM 进行文本分析和内容生成。LLM 基于 Transformer 架构,这是 2017 年 6 月推出的一种深度学习神经网络,可以在海量未标记的文本语料库上进行训练。这种方法创造了一种更像人类的对话体验,并且可以容纳多个主题。
截至本文撰写之时,各种规模的公司都想使用这项技术,但在如何开始使用方面需要帮助。如果您想开始使用生成式人工智能以及在对话式人工智能中使用 LLM,那么这篇文章就是为您准备的。我们提供了一个示例项目,用于快速部署使用预训练的开源 LLM 的 Amazon Lex 机器人。该代码还包括实现自定义内存管理器的起点。这种机制可以让 LLM 回想之前的互动,以保持对话的语境和节奏。最后,有必要强调对提示和 LLM 随机性和确定性参数进行微调实验以获得一致结果的重要性。
解决方案概览
该解决方案将 Amazon Lex 机器人与 Amazon SageMaker JumpStart 的流行开源 LLM 集成在一起,可通过 Amazon SageMaker 端点进行访问。我们还使用 LangChain,这是一种流行的框架,可简化基于 LLM 的应用程序。最后,我们使用 QnABot 为聊天机器人提供用户界面。

首先,我们对上图中的每个组件进行描述:
- JumpStart 为各种问题类型提供预训练的开源模型。这使您能够快速开始机器学习(ML)。此组件包括 FLAN-T5-XL 模型,这是一种部署在深度学习容器中的 LLM。此组件在包括文本生成在内的各种自然语言处理(NLP)任务中表现出色。
- SageMaker 实时推理端点支持快速、可扩展地部署机器学习模型以预测事件。由于能够与 Lambda 函数集成,此端点支持构建自定义应用程序。
- AWS Lambda 函数使用来自 Amazon Lex 机器人或 QnABot 的请求来准备有效负载,以便使用 LangChain 调用 SageMaker 端点。LangChain 是一种框架,开发人员可以使用此框架创建由 LLM 支持的应用程序。
- Amazon Lex V2 机器人内置了
AMAZON.FallbackIntent意图类型。当用户的输入与机器人中的任何意图都不匹配时,就会触发此意图类型。 - QnABot 是一种开源 AWS 解决方案,旨在为 Amazon Lex 机器人提供用户界面。我们为
CustomNoMatches项配置了 Lambda hook 函数,当 QnABot 找不到答案时,此解决方案就会触发 Lambda 函数。我们假定您已经部署了此解决方案,并在以下各节中包含了配置步骤。
下面的序列图对此解决方案进行了详细描述。
解决方案执行的主要任务
在本节中,我们将介绍在解决方案中执行的主要任务。此解决方案的整个项目源代码可在此 GitHub 存储库中查阅。
处理聊天机器人回退
Lambda 函数通过 Amazon Lex V2 中的 AMAZON.FallbackIntent 和 QnABot 中的 CustomNoMatches 项处理“don’t know”答案。触发后,此函数会查看会话请求和回退意图。如果有匹配项,此函数会将请求移交给 Lex V2 调度程序;否则,QnABot 调度程序将使用该请求。请参阅以下代码:
为 LLM 提供内存
为了在多轮对话中保留 LLM 内存,Lambda 函数包含一个 LangChain 自定义内存类机制,该机制使用 Amazon Lex V2 Sessions API 来跟踪正在进行的多轮对话消息的会话属性,并通过之前的交互为对话模型提供上下文。请参阅以下代码:
下面是我们为在 LangChain ConversationChain 中引入自定义内存类而创建的示例代码:
提示定义
LLM 的提示是为生成的响应定下基调的问题或陈述。提示作为一种情境形式,有助于引导模型生成相关的响应。请参阅以下代码:
使用 Amazon Lex V2 会话来支持 LLM 内存
当用户与机器人互动时,Amazon Lex V2 会启动会话。除非手动停止或超时,否则会话会随着时间的推移而持续存在。会话存储元数据和应用程序特定的数据,即会话属性。当 Lambda 函数添加或更改会话属性时,Amazon Lex 会更新客户端应用程序。QnABot 包含一个在 Amazon Lex V2 基础上设置和获取会话属性的接口。
在我们的代码中,我们使用这种机制在 LangChain 中构建了一个自定义内存类,以跟踪对话历史记录并使 LLM 能够调用短期和长期的互动。请参阅以下代码:
先决条件
要开始部署,您需要满足以下先决条件:
- 通过可以启动 AWS CloudFormation 堆栈的用户访问 AWS 管理控制台
- 熟悉 Lambda 和 Amazon Lex 控制台的导航功能
部署解决方案
要部署解决方案,请继续执行以下步骤:
- 选择启动堆栈,在
us-east-1区域启动解决方案:

- 对于堆栈名称,输入唯一的堆栈名称。
- 对于 HFModel,我们使用 JumpStart 上提供的
Hugging Face Flan-T5-XL模型。 - 对于 HFTask,输入
text2text。 - 保持 S3BucketName 不变。
这些信息用于查找部署解决方案所需的 Amazon Simple Storage Service(Amazon S3)资产,并且可能会随着这篇文章的更新发布而发生变化。

- 确认能力。
- 单击 Create stack(创建堆栈)。
应该有四个成功创建的堆栈。

配置 Amazon Lex V2 机器人
对于 Amazon Lex V2 机器人,无需配置任何内容。我们的 CloudFormation 模板已经完成了繁重的工作。
配置 QnABot
我们假设您的环境中已经部署了现有的 QnABot。但如果您需要帮助,请按照这些说明进行部署。
- 在 AWS CloudFormation 控制台上,导航到您部署的主堆栈。
- 在输出选项卡上,记下
LambdaHookFunctionArn,因为稍后需要将此项插入 QnABot 中。

- 以管理员身份登录 QnABot Designer 用户界面(UI)。
- 在问题用户界面中,添加一个新问题。

- 输入以下值:
- ID –
CustomNoMatches - 问题 –
no_hits - 答案 –“don’t know”的任何默认答案
- ID –
- 选择高级,然后转到 Lambda Hook 部分。
- 输入您之前记下的 Lambda 函数的 Amazon 资源名称(ARN)。
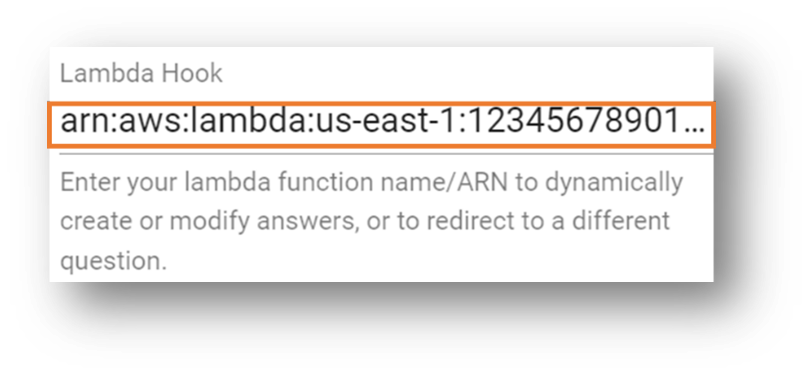
- 向下滚动到该部分的底部,然后选择创建。
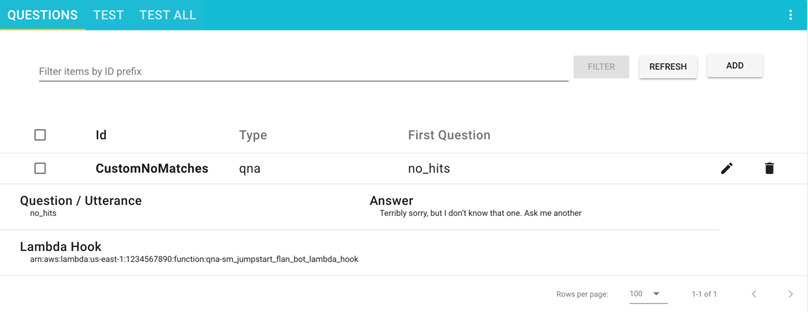
您会看到一个显示成功消息的窗口。

您的问题现已显示在问题页面上。
测试解决方案
让我们继续测试解决方案。首先,值得一提的是,我们部署的是 JumpStart 提供的 FLAN-T5-XL 模型,没有进行任何微调。这可能会有一些不可预测性,导致响应略有不同。
使用 Amazon Lex V2 机器人进行测试
本节有助于您测试 Amazon Lex V2 机器人与 Lambda 函数的集成,该函数调用部署在 SageMaker 端点中的 LLM。
- 在 Amazon Lex 控制台上,导航到名为
Sagemaker-Jumpstart-Flan-LLM-Fallback-Bot的机器人。
此机器人已配置为在没有其他意图匹配时调用 Lambda 函数,该函数调用托管 LLM 的 SageMaker 端点作为回退意图。 - 在导航窗格中选择意图。

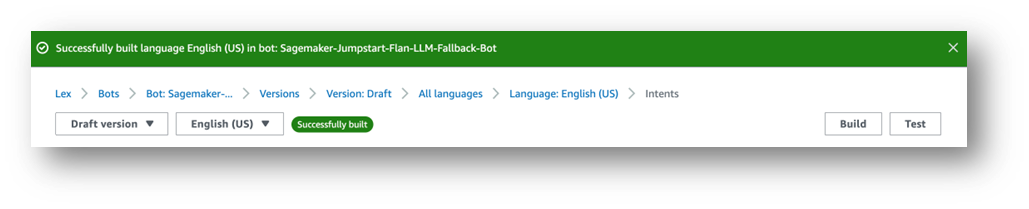
右上方显示“英语(美国)尚未生成更改”消息。
- 选择构建。
- 等待构建完成。
最后,您会看到一条成功消息,如以下屏幕截图所示。
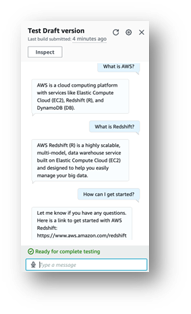
- 选择测试。
此时会出现一个聊天窗口,您可以在其中与模型进行交互。
我们建议探索 Amazon Lex 机器人与 Amazon Connect 之间的内置集成。此外,还有消息平台(Facebook、Slack、Twilio SMS)或使用 Amazon Chime SDK 和 Genesys Cloud 的第三方联络中心等。
使用 QnABot 实例进行测试
本节测试 AWS 上的 QnABot 与 Lambda 函数的集成,该函数调用部署在 SageMaker 端点中的 LLM。
- 打开左上角的工具菜单。
- 选择 QnABot 客户端。
- 选择以管理员身份登录。

- 在用户界面中输入任何问题。
- 评估响应。

清理
为避免将来产生费用,请按照以下步骤删除我们的解决方案创建的资源:
- 在 AWS CloudFormation 控制台上,选择名为
SagemakerFlanLLMStack的堆栈(或您为堆栈设置的自定义名称)。 - 选择 Delete(删除)。
- 如果您为测试目的部署了 QnABot 实例,请选择 QnABot 堆栈。
- 选择 Delete(删除)。
总结
在这篇文章中,我们探讨了在面向任务的机器人中添加开放域功能的问题,该机器人会将用户请求路由到开源的大型语言模型。
我们鼓励您:
- 将对话历史记录保存到外部持久机制中。例如,您可以将对话历史记录保存到 Amazon DynamoDB 或 S3 存储桶,然后在 Lambda hook 函数中检索记录。这样,您就无需依赖 Amazon Lex 提供的内部非持久会话属性管理。
- 尝试摘要 – 在多轮对话中,生成摘要很有帮助,您可以在提示中使用摘要来添加上下文并限制对话历史记录的使用。这有助于削减机器人会话大小并保持较低的 Lambda 函数内存消耗。
- 尝试不同的提示 – 修改原始的提示描述,以符合您的实验目的。
- 调整语言模型以获得最佳结果 – 您可以根据自己的应用程序,通过微调随机性(
temperature)和确定性(top_p)等高级 LLM 参数来实现这一目标。我们使用带样本值的预训练模型演示了一个集成示例,但您也可以根据自己的使用案例调整样本值。
在下一篇文章中,我们计划协助您了解如何使用自己的数据微调预训练的 LLM 支持的聊天机器人。
您是否正在 AWS 上尝试使用 LLM 聊天机器人? 在评论中告诉我们更多信息!
资源和参考资料
- 这篇文章的配套源代码
- Amazon Lex V2 开发指南
- AWS 解决方案库:AWS 上的 QnABot
- 使用 FLAN T5 模型生成 Text2Text
- LangChain – 使用 LLM 构建应用程序
- 使用 Jumpstart 根基模型的 Amazon SageMaker 示例
- Amazon BedRock – 使用根基模型构建和扩展生成式人工智能应用程序的最简单方法
- 使用 Amazon Kendra、LangChain 和大型语言模型根据企业数据快速构建高精度的生成式人工智能应用程序
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
关于作者
 Marcelo Silva 是一位经验丰富的技术专家,擅长设计、开发和实施尖端产品。在 Cisco 开始职业生涯时,Marcelo 参与了各种备受瞩目的项目,包括部署有史以来第一个运营商路由系统和成功推出 ASR9000。在加入 GenAI 之前,他曾在 Cisco、Cape Networks 和 AWS 等多家公司担任高级经理,专业领域涉及云技术、分析和产品管理。Marcelo 目前担任对话式人工智能/GenAI 产品经理,在为各行各业提供创新解决方案方面继续表现出色。
Marcelo Silva 是一位经验丰富的技术专家,擅长设计、开发和实施尖端产品。在 Cisco 开始职业生涯时,Marcelo 参与了各种备受瞩目的项目,包括部署有史以来第一个运营商路由系统和成功推出 ASR9000。在加入 GenAI 之前,他曾在 Cisco、Cape Networks 和 AWS 等多家公司担任高级经理,专业领域涉及云技术、分析和产品管理。Marcelo 目前担任对话式人工智能/GenAI 产品经理,在为各行各业提供创新解决方案方面继续表现出色。
 Victor Rojo 是一位经验丰富的技术专家,他对人工智能、机器学习和软件开发的最新技术充满热情。凭借他的专业知识,他在将 Amazon Alexa 推向美国和墨西哥市场方面发挥了关键作用,同时带头向 AWS 合作伙伴成功推出 Amazon Textract 和 AWS Contact Center Intelligence(CCI)。作为对话式人工智能能力合作伙伴计划的现任首席技术负责人,Victor 致力于推动创新并提供尖端解决方案,以满足行业不断变化的需求。
Victor Rojo 是一位经验丰富的技术专家,他对人工智能、机器学习和软件开发的最新技术充满热情。凭借他的专业知识,他在将 Amazon Alexa 推向美国和墨西哥市场方面发挥了关键作用,同时带头向 AWS 合作伙伴成功推出 Amazon Textract 和 AWS Contact Center Intelligence(CCI)。作为对话式人工智能能力合作伙伴计划的现任首席技术负责人,Victor 致力于推动创新并提供尖端解决方案,以满足行业不断变化的需求。
 Justin Leto 是Amazon Web Services 的高级解决方案架构师,专门研究机器学习。他热衷于协助客户利用机器学习和人工智能的力量推动业务增长。Justin 曾在包括 AWS 峰会在内的全球人工智能会议上发表演讲,并在大学讲课。他是纽约市机器学习和人工智能聚会的负责人。在业余时间,他喜欢海上航行和演奏爵士乐。他与妻子和宝贝女儿住在纽约市。
Justin Leto 是Amazon Web Services 的高级解决方案架构师,专门研究机器学习。他热衷于协助客户利用机器学习和人工智能的力量推动业务增长。Justin 曾在包括 AWS 峰会在内的全球人工智能会议上发表演讲,并在大学讲课。他是纽约市机器学习和人工智能聚会的负责人。在业余时间,他喜欢海上航行和演奏爵士乐。他与妻子和宝贝女儿住在纽约市。
 Ryan Gomes 是 AWS Professional Services Intelligence Practice 的数据和机器学习工程师。他热衷于通过云端的分析和机器学习解决方案协助客户取得更好的成果。工作之余,他喜欢健身、烹饪,也喜欢与朋友和家人共度美好时光。
Ryan Gomes 是 AWS Professional Services Intelligence Practice 的数据和机器学习工程师。他热衷于通过云端的分析和机器学习解决方案协助客户取得更好的成果。工作之余,他喜欢健身、烹饪,也喜欢与朋友和家人共度美好时光。
 Mahesh Birardar 是Amazon Web Services 的高级解决方案架构师,专门研究 DevOps 和可观测性。他乐于协助客户实施具有成本效益的可扩展架构。工作之余,他喜欢看电影和徒步旅行。
Mahesh Birardar 是Amazon Web Services 的高级解决方案架构师,专门研究 DevOps 和可观测性。他乐于协助客户实施具有成本效益的可扩展架构。工作之余,他喜欢看电影和徒步旅行。
 Kanjana Chandren 是 Amazon Web Services(AWS)的解决方案架构师,对机器学习充满热情。她协助客户设计、实施和管理 AWS 工作负载。工作之余,她喜欢旅行、阅读,也喜欢与家人和朋友共度时光。
Kanjana Chandren 是 Amazon Web Services(AWS)的解决方案架构师,对机器学习充满热情。她协助客户设计、实施和管理 AWS 工作负载。工作之余,她喜欢旅行、阅读,也喜欢与家人和朋友共度时光。