亚马逊AWS官方博客
大道至简-使用Athena对数据ETL处理
1. 概览
在数据ETL(extract,transform and load)的过程中,我们通常会需要使用一些数据处理分析工具,在AWS平台中,我们通常会使用EMR或者Glue对大量数据进行ETL处理,这时需要启用一个EMR集群或在Glue任务中编写程序代码以进行数据处理.如果面对数据量不是非常巨大或只是进行一定范围数据的处理工作,使用Athena即可完成对数据湖中数据的抽取转换及优化的全部工作,这篇文章使用一个简单数据集演示在Athena上如何完成数据的格式化,处理以及数据分区.
Amazon Athena 是一种交互式查询服务,让您可以轻松使用标准 SQL 语言在 Amazon S3 中直接分析数据。只需在 AWS 管理控制台中点击几下,客户便可以将 Athena 指向其存储在 S3 中的数据,并开始使用标准 SQL 运行临时查询并在几秒钟内获取结果。通过使用CATS(CREATE TABLE AS SELECT)方法我们可以通过查询的 SELECT 语句的结果创建新表,也可以将由 CTAS 语句创建的数据文件存储在 Amazon S3 中的指定位置,详细的语法可以参考CREATE TABLE AS

2. 样本数据说明
我们使用样本数据是一个模拟数据集,里面包括2015年1月份31天的的ELB模拟数据,原始数据位于’s3://aws-tc-largeobjects/AWS-200-BIG/v3.1/lab-2-athena/raw/’存储在31个子目录下的186个TXT文件中(月/每天一个), 内容如下:
2015-01-01T00:00:00.022719Z elb_demo_005 244.218.91.244:2255 172.36.231.239:443 0.000878 0.000803 0.000891 200 200 0 1886 “GET https://www.example.com/jobs/376 HTTP/1.1” “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36” DHE-RSA-AES128-SHA TLSv1.2
在S3中存储的结构如下:
581201753 raw/year=2015/month=1/day=1/part-r-00000.txt
569297436 raw/year=2015/month=1/day=1/part-r-00001.txt
518914338 raw/year=2015/month=1/day=1/part-r-00002.txt
84349071 raw/year=2015/month=1/day=1/paart-r-00003.txt
516079109 raw/year=2015/month=1/day=1/part-r-00004.txt
475690426 raw/year=2015/month=1/day=1/part-r-00005.txt
每个文件包含大约500MB的未压缩数据,整个存储桶大小约90.7GB,存储为多个文件的一个重要原因是可以让Amazon Athena cluster 实现并发文件读取,从而加快文件的读取速度.
3.数据处理过程
3.1 原始数据处理
在对数据集进行后续操作前,我们先使用Athena处理一下原始数据并简单测试一下查询性能.
在Athena 控制台中使用如下语句创建一个数据库.
CREATE DATABASE demodb
运行成功后,我们可以在Athena控制台左侧看到创建完成的数据库,选中这个数据库,完成后续的操作. 然后使用以下语句创建一个外表:
CREATE EXTERNAL TABLE IF NOT EXISTS elb_logs_raw (
request_timestamp string,
elb_name string,
request_ip string,
request_port int,
backend_ip string,
backend_port int,
request_processing_time double,
backend_processing_time double,
client_response_time double,
elb_response_code string,
backend_response_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
url string,
protocol string,
user_agent string,
ssl_cipher string,
ssl_protocol string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1','input.regex' = '([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*):([0-9]*) ([.0-9]*) ([.0-9]*) ([.0-9]*) (-|[0-9]*) (-|[0-9]*) ([-0-9]*) ([-0-9]*) \\\"([^ ]*) ([^ ]*) (-|[^ ]*)\\\" (\"[^\"]*\") ([A-Z0-9-]+) ([A-Za-z0-9.-]*)$' )
LOCATION 's3://wh-bigdata-bucket/athena/raw/';
创建完成后,我们会在Athena的数据库中看到新创建的表 elb_logs_raw
使用以下测试脚本查看运行时间和数据扫描大小:
SELECT elb_name,elb_response_code, count(*) AS count FROM elb_logs_raw WHERE request_timestamp LIKE '2015-01-01%' GROUP BY elb_name,elb_response_code ORDER BY elb_name;

Athena会返回脚本运行的时间和扫描的数据量,如:运行时间: 18.16 秒, 数据已扫描: 90.72 GB,注意到,即使只请求一个ELB一天的数据,此查询也会扫描所有90GB的数据。
在接下来的步骤中,我们会使用Athena 数据进行格式压缩等操作对数据进行进一步处理.
3.2 对原始数据进行格式化和压缩和分区
没有经过格式和压缩的数据查询效率低,扫描数据量大,而且由于Athena是按照扫描数据量进行收费,因此也会增加成本,下面我们使用Athena 的CTAS方法对数据进行一些优化处理.
- 压缩数据,压缩数据可以将S3的存储成本进一步压缩,传输速度更快(因为传输的数据更少)和处理成本更低,也会降低Athena从Amazon S3扫描的数据量。
- 列式文件格式,Apache Parquet 和 ORC 是针对快速检索数据进行了优化的列式存储格式,按列压缩,针对列数据类型选择压缩算法,可以节省 Amazon S3 中的存储空间,并减少查询处理期间的磁盘空间和 I/O,同时Apache Parquet 和 ORC的数据拆分也使得 Athena可以将数据读取拆分为多个读进程,在查询处理期间增加并行度。
- 分区,通过分区数据,您可以限制每个查询扫描的数据量,从而提高性能并降低成本,Athena 利用 Hive 来对数据进行分区,Athena可按任何数据列进行分区,但常见的做法是根据时间对数据进行分区,或者二级分区.
我们使用以下语句,将原始数据使用ZIP压缩并转换为Parquet格式,而且基于时间进行分区
CREATE TABLE IF NOT EXISTS elb_logs_parquet_Optimized
WITH (format='parquet', partitioned_by=ARRAY['year','month','day'],external_location='s3://wh-bigdata-bucket/athena/Optimized/') AS
SELECT request_timestamp,
elb_name,
request_ip,
request_port,
backend_ip,
request_processing_time,
backend_processing_time,
client_response_time,
elb_response_code,
backend_response_code,
received_bytes,
sent_bytes,
request_verb,
url,
protocol,
user_agent,
ssl_cipher,
ssl_protocol,
substr("request_timestamp",1,4) AS year,
substr("request_timestamp",6,2) AS month,
substr("request_timestamp",9,2) AS day
FROM elb_logs_raw
WHERE cast(substr("request_timestamp",9,2) AS bigint)>=01
AND cast(substr("request_timestamp",9,2) AS bigint)<15
说明:我们在这里parquet格式,并使用Gzip格式(默认参数,也可以选择SNAPPY压缩),使用年月日做分区,你也可以根据需要选择部分字段数据进行数据筛选,此外我们这里也做了范围的限定,你也可以根据实际情况对数据进行过滤.
命令执行成功后,在控制台左侧可以看到新增加的表elb_logs_parquet_Optimized,我们可以使用 ’show partitions elb_logs_parquet_Optimized’查看具体的分区情况
year=2015/month=01/day=04
year=2015/month=01/day=02
year=2015/month=01/day=09
year=2015/month=01/day=14
year=2015/month=01/day=01
year=2015/month=01/day=07
year=2015/month=01/day=05
year=2015/month=01/day=06
year=2015/month=01/day=13
year=2015/month=01/day=12
year=2015/month=01/day=08
year=2015/month=01/day=03
year=2015/month=01/day=11
year=2015/month=01/day=10
在S3 中 使用命令aws s3 ls s3://wh-bigdata-bucket/athena/Optimized/ --recursive --human-readable | head -3可以查看到文件已经被写入到相应的分区中
2020-08-23 21:15:47 0 Bytes athena/Optimized/
2020-08-23 21:57:22 6.5 MiB athena/Optimized/year=2015/month=01/day=01/20200823_135610_00001_8q3xu_01014f82-1d26-464a-b669-7ee6684d1b8e
2020-08-23 21:57:22 8.6 MiB athena/Optimized/year=2015/month=01/day=01/20200823_135610_00001_8q3xu_047aa037-3d52-46dd-a7ac-cffecfb4ce4f
3.3 对数据进行丰富操作
目前我们只有半个月的数据,如果我们需要向表中增加数据,可以使用CTAS的INSERT INTO命令向表中增加数据,我们使用如下语句,将后15天的数据增加到表中
INSERT INTO elb_logs_parquet_Optimized
SELECT request_timestamp,
elb_name,
request_ip,
request_port,
backend_ip,
request_processing_time,
backend_processing_time,
client_response_time,
elb_response_code,
backend_response_code,
received_bytes,
sent_bytes,
request_verb,
url,
protocol,
user_agent,
ssl_cipher,
ssl_protocol,
substr("request_timestamp",1,4) AS year,
substr("request_timestamp",6,2) AS month,
substr("request_timestamp",9,2) AS day
FROM elb_logs_raw
where cast(substr("request_timestamp",9,2) AS bigint)>=15
在实际场景中,我们可以在这个过程中增加更复杂的操作,例如修改映射关系,增加字段等具体支持的语法可以参考CTAS语法.
再次使用’show partitions elb_logs_parquet_Optimized’查看分区信息,已经可以看到15日以后的分区信息数据了.
现在已经和原始表的数据内容一致了,我们现在再来运行一次同样查询(注意这里使用了基于时间分区的查询),看看性能有没有提升.
SELECT elb_name,elb_response_code,
count(*) AS count
FROM elb_logs_parquet_optimized
WHERE year='2015' AND month='01' AND day='01'
GROUP BY elb_name,elb_response_code
ORDER BY elb_name;
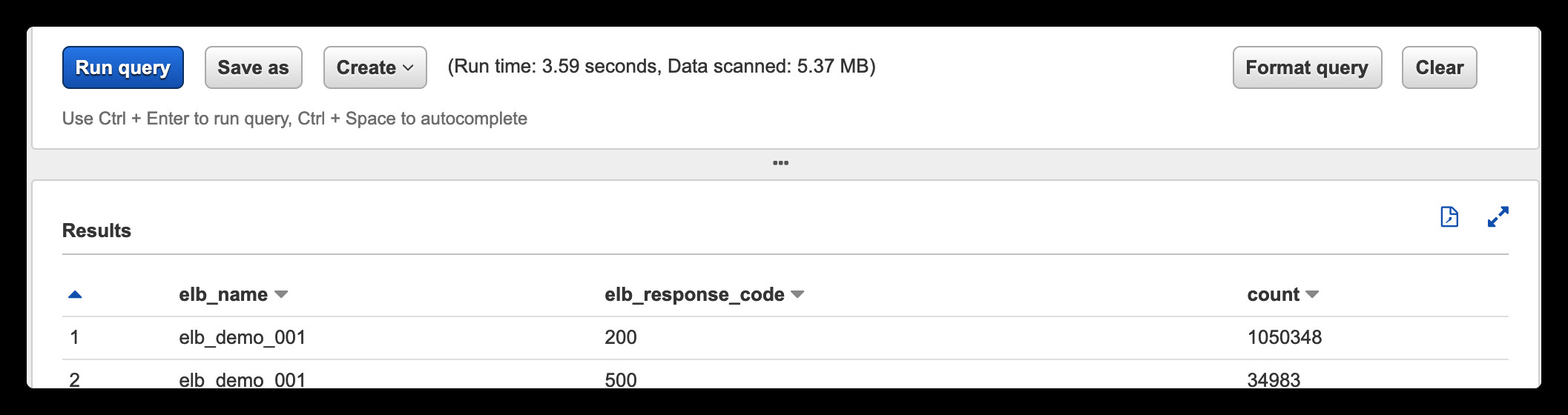
可以看到查询数据的扫描量大幅度下降,查询速度有了很大的提升. 即使查询半个月的数据,整体扫描数据量和时间也没有大幅度增加,这是因为通过分区我们使得查询需要扫描的数据限定在S3中指定的分区内,扫描的时候只需要查询特定的分区就可以快速返回结果. 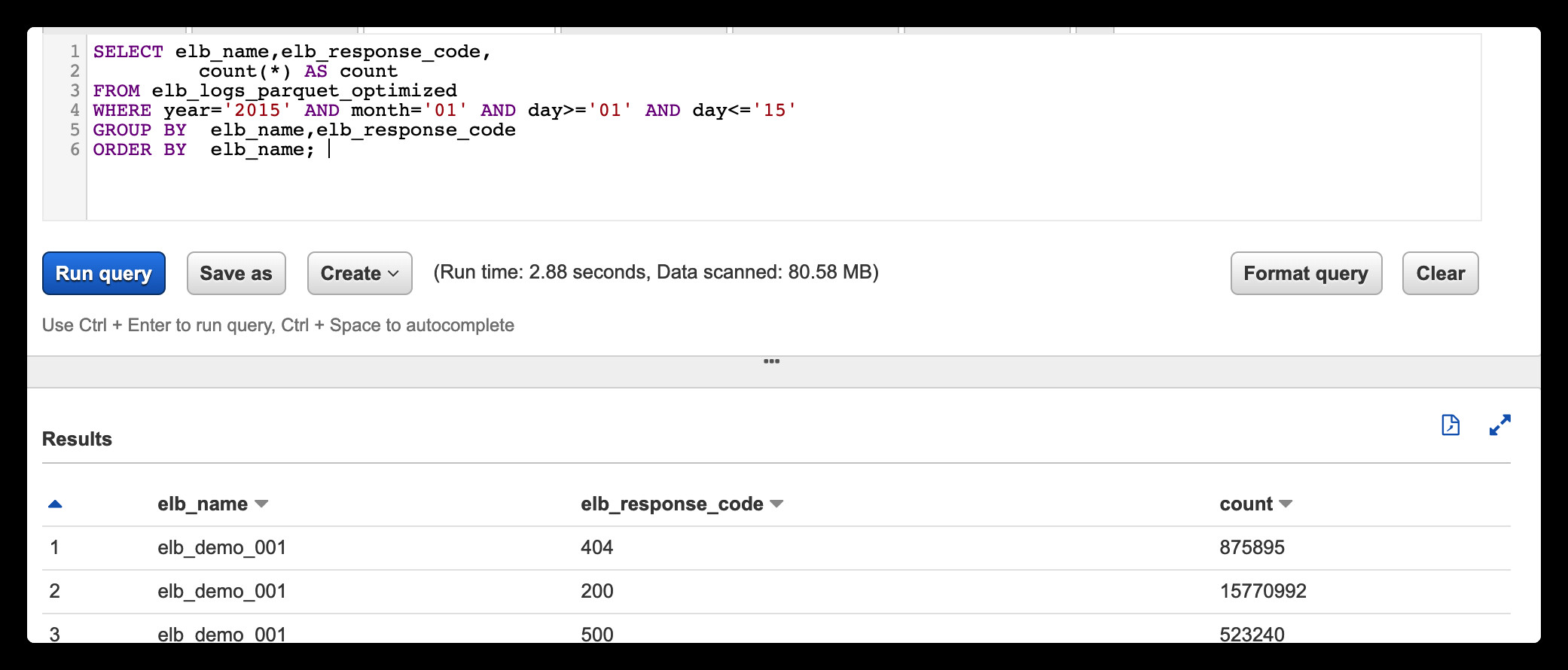
3.4 对数据进行再分区
通常来说,我们一般会将数据以时间的方式进行分区,例如年/月/日,但有的时候我们需要在时间维度之外对数据进行基于其他维度的分区,例如在本例中,我们希望可以很快查询出基于日期,ELB名称和ELB response code的数据,就可以使用CTAS对这些数据进行再分区 以下是示例代码
CREATE TABLE elb_logs_parquet_datapartition
WITH (partitioned_by = ARRAY['day','elb_name','elb_response_code'] , format='parquet', parquet_compression = 'GZIP',external_location = 's3://wh-bigdata-bucket/athena/datapartition') AS
SELECT request_timestamp string,
request_ip,
request_port,
backend_ip,
request_processing_time,
backend_processing_time,
client_response_time,
backend_response_code,
received_bytes,
sent_bytes,
request_verb,
url,
protocol,
user_agent,
ssl_cipher,
ssl_protocol,
substr("request_timestamp",9,2) AS day,
elb_name,
elb_response_code
FROM elb_logs_parquet_Optimized
where cast(substr("request_timestamp",9,2) AS bigint)>=01 AND cast(substr("request_timestamp",9,2) AS bigint)<3
我们再通过 Show Partitions,可以查看,我们已经基于我们想要的数据做好了分区.

这样如果我们通过,基于ElB名称和日期作为筛选条件进行查询时,就可以很快通过Athena返回结果了

做基于数据分区的时候有几点需要注意:
- 以上代码只是一个演示需要的一个示例,实际场景中需要根据查询条件,频率和数据分区难度具体分析.
- 需要进行数据分区的字段建议放在Select部分的后端
- 创建的表格是有分区数量限制的,默认为每个查询100个分区,如果增加更多分区,可以通过INSERT INTO继续插入更多分区(但每次插入的分区也被限定为100个)
- 一些其他限制可以参考Amazon Athena 中 SQL 查询的注意事项和限制
4. 总结
这篇文章向您展示了如何使用Athena CTAS 方法执行ETL操作,您可以使用Athena CTAS语句执行数据转换丰富和格式转换工作,将非分区数据集转换为分区数据集,减小数据集的总体大小,降低了在Athena中运行查询的成本并提升性能。因此,在一些特定场景中,我们无需启动EMR集群或者复杂的编码也可以通过Athena对数据进行快速的ETL.
5. 参考资源
将 CTAS 和 INSERT INTO 用于 ETL 和数据分析 https://docs.thinkwithwp.com/zh_cn/athena/latest/ug/ctas-insert-into-etl.html
从查询结果创建表 (CTAS) https://docs.thinkwithwp.com/zh_cn/athena/latest/ug/ctas.html
CTAS 查询的注意事项和限制 https://docs.thinkwithwp.com/zh_cn/athena/latest/ug/considerations-ctas.html
使用 CTAS 和 INSERT INTO 创建带 100 多个分区的表 https://docs.thinkwithwp.com/zh_cn/athena/latest/ug/ctas-insert-into.html