亚马逊AWS官方博客
为 Amazon FSx for Lustre 增强了 Amazon S3 集成功能
我们宣布推出 Amazon FSx for Lustre 的另外两项功能。首先,能够使用 Amazon Simple Storage Service (Amazon S3) 对文件系统进行完全双向同步,包括已删除的文件和对象。其次,能够将文件系统与多个 S3 存储桶或前缀同步。
Lustre 是大规模的分布式并行文件系统,为大多数最大型超级计算机的工作负载提供支持。它因气象、生命科学和工程模拟等领域的高性能计算工作负载而受到 AWS 客户的广泛欢迎。该系统还用于媒体和娱乐以及金融服务行业。
首次就职于 Sun Microsystems 时,我有了第一个动手实践的 Lustre 文件系统。我是一名售前工程师,曾参与过一些向金融服务公司出售价值数百万美元的计算和存储基础实施的交易。当时,能够访问 Lustre 文件系统是一种奢侈的行为。它需要具备昂贵的计算、存储和网络硬件。几周之后,我们才等到硬件的送达。此外,我们花费了几天的时间安装和配置集群。
快速推进到 2021 年,我可以创建一个 PB 级的 Lustre 集群,然后按需将文件系统附加到在 AWS 云中运行的计算资源,而且只需按使用量付费。我无需了解存储区域网络 (SAN)、光纤通道 (FC) 结构和其他底层技术。
现代应用程序为不同的工作负载使用不同的存储选项。通常使用 S3 对象存储执行数据转换、准备或导入/导出任务。其他工作负载可能需要 POSIX 文件系统才能访问数据。FSx for Lustre 可让您将存储在 S3 上的对象与 Lustre 文件系统同步,从而满足这些要求。
将 S3 存储桶链接到文件系统时,FSx for Lustre 会透明地将 S3 对象显示为文件,并可让您将结果写回 S3。
与多个 S3 存储桶进行完全双向同步
如果您的工作负载需要快速、符合 POSIX 标准的文件系统来访问 S3 存储桶,则可以使用 FSx for Lustre 将 S3 存储桶链接到文件系统,同时使文件系统和 S3 之间的数据在两个方向上保持同步。但是,直到今天仍然有一些限制。首先,必须手动配置一个任务,以将数据从 FSx for Lustre 导出并传回 S3。其次,S3 上已删除的文件不会自动从文件系统中删除。第三点是,一个 FSx for Lustre 文件系统仅与一个 S3 存储桶同步。我们通过本次发布来应对这三项挑战。
从今天开始,当您为数据存储库关联配置自动导出策略时,FSx for Lustre 文件系统上的文件将自动导出到 S3 上的数据存储库。接下来,S3 上已删除的对象现在将自动从 FSx for Lustre 文件系统中删除。同样存在反向操作:删除 FSx for Lustre 上的文件会触发删除 S3 上的相应对象。最后,现在可以将 FSx for Lustre 文件系统与多个 S3 存储桶同步。每个存储桶在 Lustre 文件系统的根目录中都有不同的路径。例如,S3 存储桶日志可能映射到 /fsx/logs,而另一个 financial_data 存储桶可能映射到 /fsx/finance。
如果必须同时使用基于文件和基于对象的工作流并行处理 S3 存储桶中的数据,以及在这些工作流之间近乎实时地共享结果,这些新功能就非常有用。例如,访问文件数据的应用程序可以通过使用链接到 S3 存储桶的 FSx for Lustre 文件系统执行处理,而在 Amazon EMR 上运行的另一个应用程序可能会处理来自 S3 的相同文件。
此外,您可以将多个 S3 存储桶或前缀链接到单个 FSx for Lustre 文件系统,从而实现跨多个数据集的统一视图。现在,您可以创建单个 FSx for Lustre 文件系统,并轻松链接多个 S3 数据存储库(S3 存储桶或前缀)。当您使用多个 S3 存储桶或前缀来组织和管理对数据湖的访问,从公有 S3 存储桶(例如这几百个公有数据集)访问文件并将任务输出写入不同的 S3 存储桶,或者想要使用更大的 FSx for Lustre 文件系统链接到多个 S3 数据集以实现更出色的横向扩展性能时,此功能可带来便利。
工作原理
接下来创建一个 FSx for Lustre 文件系统,并将其附加到 Amazon Elastic Compute Cloud (Amazon EC2) 实例。确保文件系统和实例位于同一个 VPC 子网中,以最大限度地降低数据传输成本。文件系统安全组必须授予实例访问权限。
打开 AWS 管理控制台,导航到 FSx,然后选择创建文件系统。接下来,选择 Amazon FSx for Lustre。此处未介绍创建文件系统的所有选项,您可以参考文档以了解如何创建文件系统。确保选择从 S3 导入数据和将数据导出到 S3。
 创建文件系统需要几分钟时间。状态为 ✅ 可用后,导航到数据存储库选项卡,然后选择创建数据存储库关联。
创建文件系统需要几分钟时间。状态为 ✅ 可用后,导航到数据存储库选项卡,然后选择创建数据存储库关联。
选择数据存储库路径(源 S3 存储桶)和文件系统路径(将在文件系统中导入该存储桶的位置)。
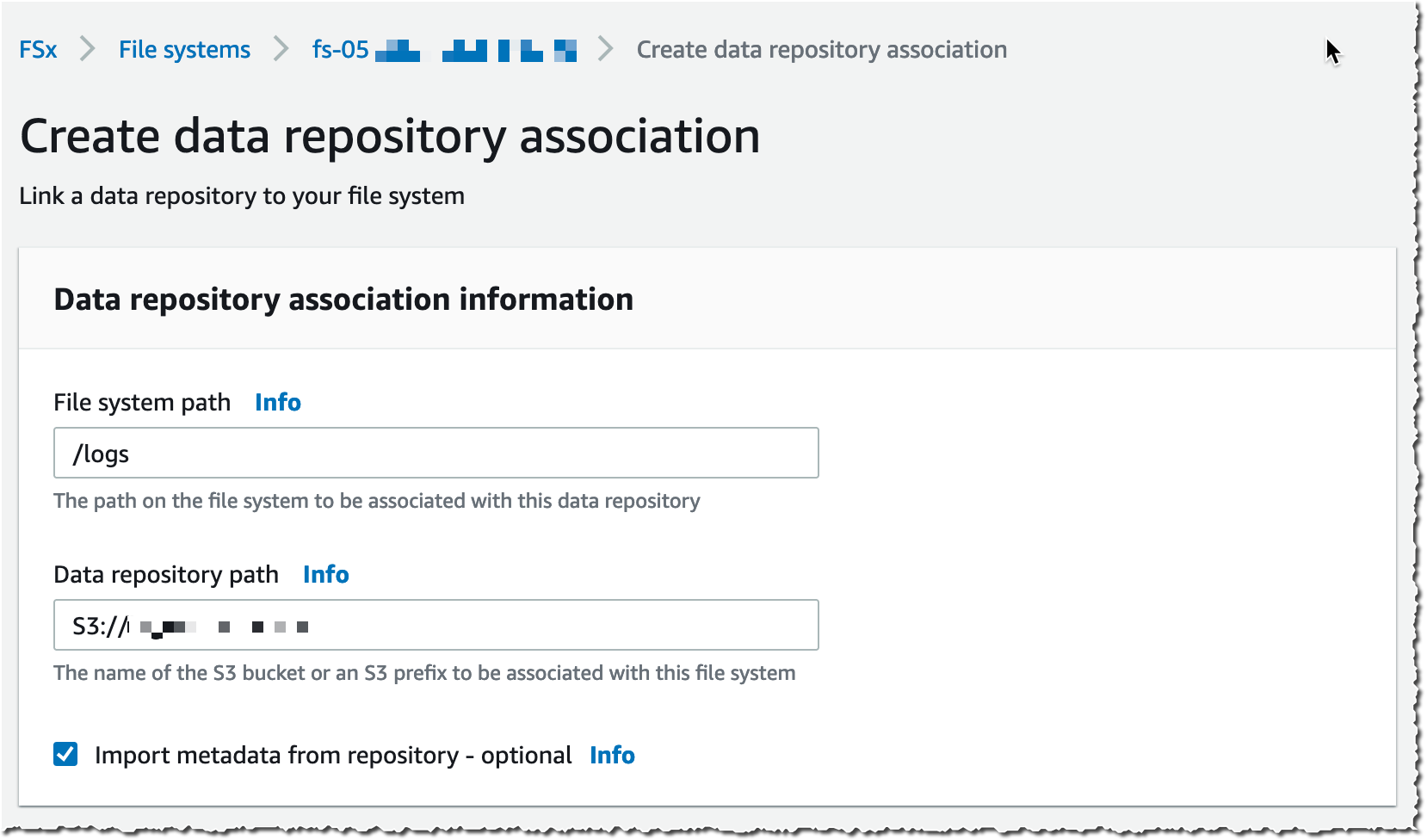
然后,选择导入策略和导出策略。可以同步文件/对象的创建、更新以及删除时间。选择创建。

使用自动导入时,还要确保在与 FSx for Lustre 集群相同的 AWS 区域中提供 S3 存储桶。FSx for Lustre 支持链接到不同 AWS 区域中的 S3 存储桶,以实现自动导出和所有其他功能。
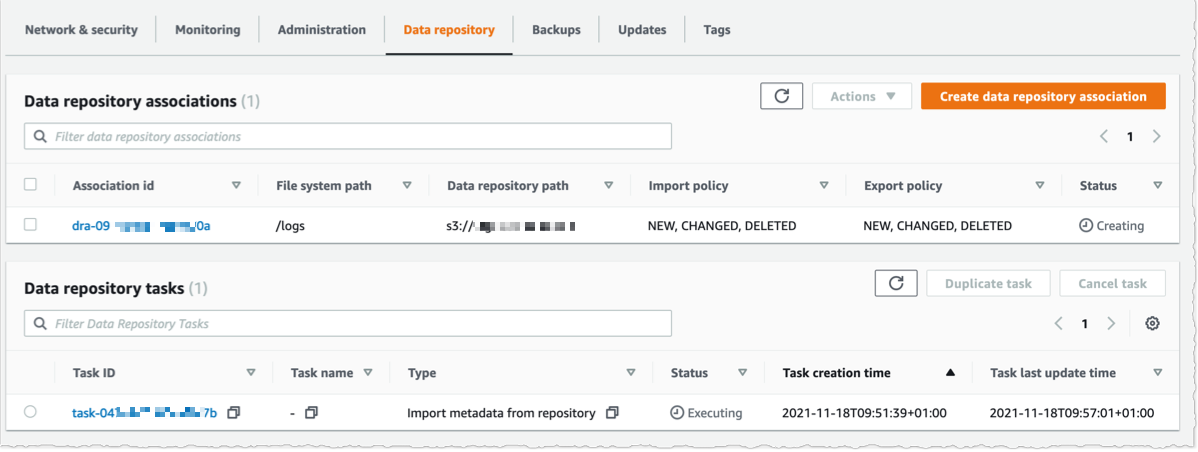
使用控制台,可以查看数据存储库关联的列表。等待导入任务状态变为 ✅ 成功。如果将文件系统链接到包含大量对象的 S3 存储桶,则可以选择在创建数据存储库关联时跳过从存储库导入元数据,然后使用导入任务从 S3 存储桶中选定的前缀(工作负载需要这些前缀)加载元数据。
在同一 VPC 子网中创建一个 EC2 实例。此外,确保 FSx for Lustre 集群安全组授权来自 EC2 实例的进站流量。使用 SSH 连接到实例,然后键入以下命令(以 shell 提示符中的 $ 符号作为命令前缀)。
# 检查内核版本,所需最低版本为 4.14.104-95.84
$ uname-r
4.14.252-195.483.amzn2.aarch64
# 安装 Lustre 客户端
$ sudo amazon-linux-extras install -y lustre2.10
Installing lustre-client
...
Installed:
lustre-client.aarch64 0:2 .10.8-5.amzn2
Complete!
# 创建挂载点
$ sudo mkdir /fsx
# 挂载文件系统
$ sudo mount -t lustre -o noatime,flock fs-00...9d.fsx.us-east-1.amazonaws.com@tcp:/ny345bmv /fsx
# 验证挂载成功
$ mount
...
172.0.0.0@tcp:/ny345bmv on /fsx type lustre (rw,noatime,flock,lazystatfs)
然后,验证文件系统是否包含 S3 对象,并且使用 touch 命令创建新文件。

切换到 AWS 控制台,在 S3 和存储桶名称下,验证文件是否已同步。

使用控制台,将文件从 S3 中删除。不出所料,几秒钟后,该文件也将从 FSx 文件系统中删除。

定价和可用性
这些新功能在 Amazon FSx for Lustre 文件系统上免费提供。自动导出和多存储库仅适用于美国东部(弗吉尼亚北部)、美国东部(俄亥俄)、美国西部(俄勒冈)、加拿大(中部)、亚太地区(东京)、欧洲(法兰克福)和欧洲(爱尔兰)中的 Persistent 2 文件系统。在支持 FSx for Lustre 的所有区域,2020 年 7 月 23 日之后创建的文件系统都可以自动导入并支持 S3 中已删除和移动的对象。
可以使用 AWS 管理控制台、AWS 命令行界面 (CLI) 和 AWS 开发工具包将文件系统配置为自动导入 S3 更新。
详细了解如何将 S3 数据存储库与 Amazon FSx for Lustre 文件系统结合使用。
还有一件事
在阅读本文期间还有一件事。今天,我们还推出了下一代 FSx for Lustre 文件系统。FSx for Lustre 下一代文件系统是基于 AWS Graviton 处理器构建的。与上一代文件系统相比,它们旨在为您提供每 TB 高达 5 倍的吞吐量(每 TB 高达 1 GB/s),并将吞吐量成本降低多达 60%。今天就试一试!
附言:我的同事 Michael 录制了一段演示视频,可向您展示 FSx for Lustre 的增强 S3 集成。现在就观看此视频。