亚马逊AWS官方博客
使用 Amazon QuickSight ML Insights 检测欺诈性呼叫
Original URL:https://thinkwithwp.com/blogs/big-data/detect-fraudulent-calls-using-amazon-quicksight-ml-insights/
欺诈者不断寻找新的技术和设计新的伎俩。这改变了欺诈方式使检测变得困难。企业通常使用基于规则的欺诈检测系统来应对。然而,一旦欺诈者意识到他们当前的伎俩或工具被识别出,他们很快就会找到破解方法。此外,在面临大量数据时,基于规则的检测系统往往会因为大量的数据显得吃力并且速度会下降。这使得难以检测欺诈行为并迅速采取行动,从而导致收入损失。
概览
有多个 AWS 服务可以实现异常检测并可用于对付欺诈,但在这里我们暂且关注以下三项:
在尝试检测欺诈时,存在两个高层级的挑战:
- 规模 – 要分析的数据量。例如,每个呼叫都会生成呼叫详细记录 (CDR) 事件。这些 CDR 包含许多信息,例如发起和终止电话号码以及呼叫持续时间。将这些 CDR 事件的数量乘以每天拨打的电话数量,您就可以大致了解运营商必须管理的规模了。
- 机器学习知识和技能 – 通过机器学习帮助解决业务问题的合适技能集。发展这些技能或雇用具备足够领域知识的合格数据科学家并非易事。
Amazon QuickSight ML Insights 介绍
Amazon QuickSight 是一个快速、基于云的 BI 服务,通过丰富的交互式控制面板,让组织中的每个人都可以轻松地从其数据中获取业务见解。通过按会话付费定价和可嵌入到您的应用程序中的控制面板,BI 现在更具成本效益,并且人人都可以使用。
但是,随着客户产生的数据量每天都在增长,利用这些数据获得业务见解也变得更具挑战性。这时候就轮到机器学习发挥作用了。 Amazon 是利用机器学习来自动化和扩展供应链、营销、零售和财务业务分析的不同层面的先驱者。
ML Insights 将经过成熟的 Amazon 技术集成到了 Amazon QuickSight 中,为客户提供超越可视化的机器学习支持的见解。
- 由机器学习提供支持的异常检测,可通过持续分析数十亿个数据点来挖掘隐藏的见解。
- 由机器学习提供支持的预测以及假设分析,可让用户通过简单的点击操作来预测关键业务指标。
- 自动叙述功能,可让用户使用普通语言的叙述方式阐述其控制面板的内容。
在这篇文章中,我演示了几乎没有机器学习专业知识的电信运营商如何使用 Amazon QuickSight ML 功能来检测欺诈性呼叫。
先决条件
要实施此解决方案,您需要以下资源:
- Amazon S3,用于准备一个 CSV 格式的“ribbon”呼叫详细记录样本。
- AWS Glue,用于在 PySpark 中运行 ETL 作业。
- 用于发现表的架构并更新 AWS Glue 数据目录的 AWS Glue 爬网程序。
- Amazon Athena,用于查询 Amazon QuickSight 数据集。
- Amazon QuickSight,用于使用 ML Insights 构建可视化并执行异常检测。
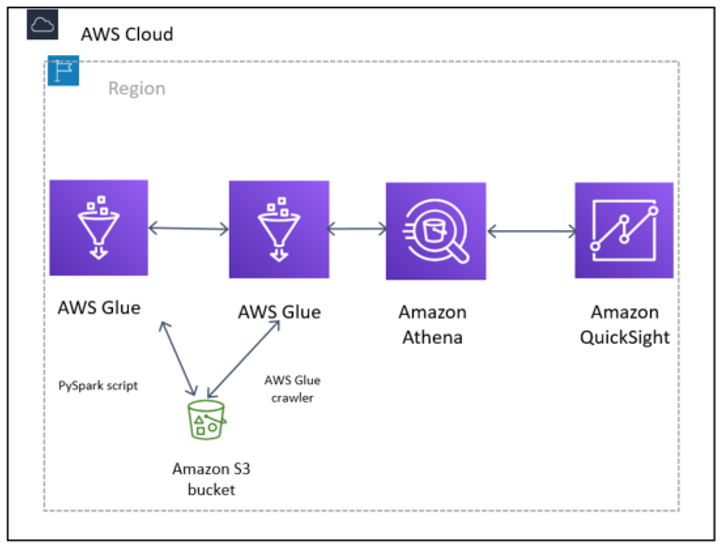
欺诈性呼叫检测示意图,使用 PySpark 脚本准备数据并将其转换为 Parquet,然后使用 AWS Glue 爬网程序构建 AWS Glue 数据目录。
数据集
在此文章中,我使用了一个合成数据集,由 Ribbon Communications 提供。数据由呼叫测试生成器生成,不是客户或敏感数据。
检查数据
以下示例是典型的 CDR。以下所示的 STOP CDR 是呼叫终止后生成的。

如您所见,这里有很多值。其中大多数对于欺诈识别或预防并无价值。
收入共享欺诈
收益共享欺诈是当今威胁电信行业最常见的欺诈手段之一。它涉及使用欺诈或被盗号码重复拨打高费率 B 号码,然后该号码与欺诈者共享现金。
假设您想使用 Amazon QuickSight ML 检测国内和国际收入分享欺诈。想一想收入分享欺诈呼叫的典型特征。收入分享欺诈的模式是多个 A 号码呼叫相同的 B 号码或具有相同前缀的一系列 B 号码。呼叫持续时间通常高于平均值,最长可达两小时,这是国际交换机允许的最长时间。通常,呼叫源自一个分区或一组分区。
一张 SIM 可能会对许多个 B 号码发起短暂的测试呼叫,作为实际欺诈行为的预演,这通常在被检测风险最低的时候进行,例如,周五晚上、周末或假日。欺诈者可能会使用会议呼叫从一个 A 号码进行多个并发呼叫。
通常,用于此类欺诈的 SIM 是通过同一经销商或一组经销商批量销售或激活的。欺诈者可能会使用欺诈性在线或 IVR 支付来充值 SIM,例如使用被盗的信用卡号码。PAYG 信用额度和捆绑包可能会被使用。基于上述情况,以下信息与检测欺诈最相关。
- 呼叫持续时间
- 发话号码(A 号码)
- 被叫号码(B 号码)
- 呼叫开始时间
- 会计 ID
您可以使用此参考来帮助识别 CDR 中的这些字段。
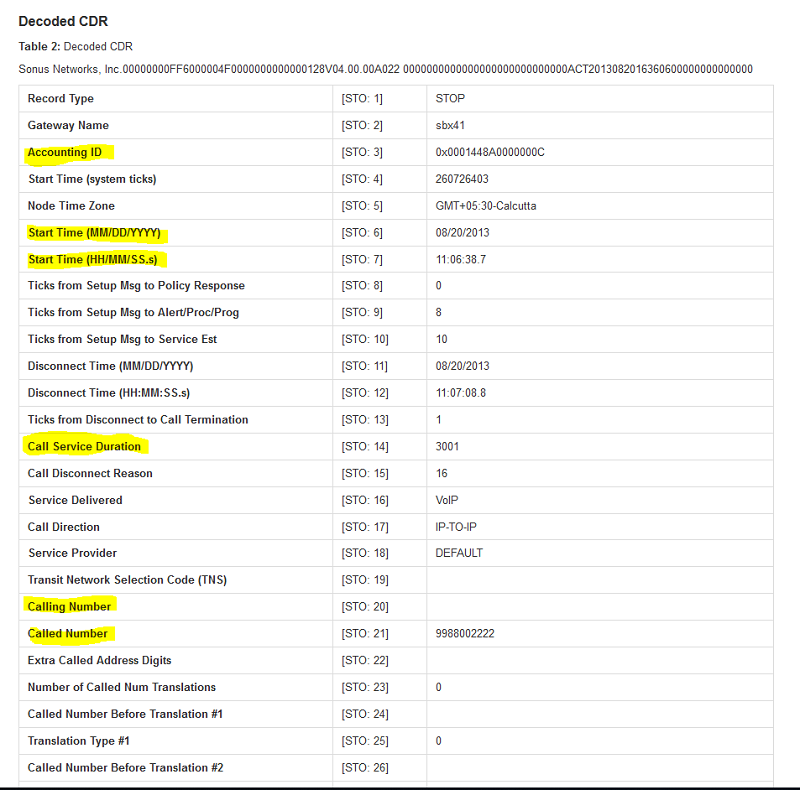
图 2:解码的 CDR 数据,突出显示了相关字段。
在 CDR 中的 235 列中确定了所需要的列。
通过检查原始样本数据,很快发现它缺少标题。
为了简化操作,请转换原始 CSV 数据,添加列名,并转换为 Parquet。
发掘数据
在 AWS Glue 控制台中,设置一个爬网程序并将其命名为 CDR_CRAWLER。
将爬网程序指向 Parquet CDR 数据所在的位置 s3://telco-dest-bucket/blog。
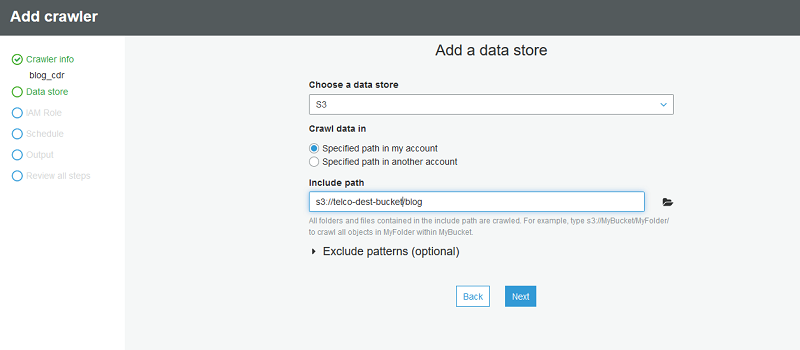
接下来,创建一个新的 IAM 角色以供 AWS Glue 爬网程序使用。
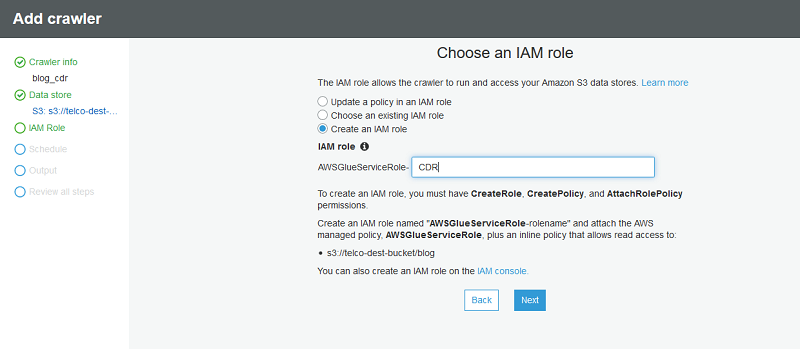
对于频率,保留默认定义按需运行。
接下来,选择添加数据库并定义数据库的名称。此数据库包含 AWS Glue 爬网程序发现的表。
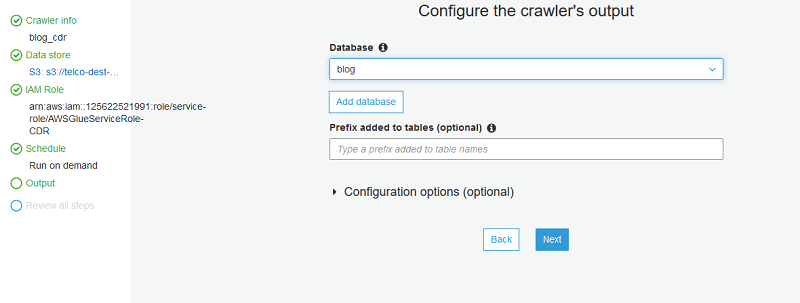
选择下一步并查看爬网程序设置。如果一切妥当,请选择完成。
接下来,选择爬网程序,选择刚刚创建的爬网程序 (CDR_CRAWLER),然后选择运行爬网程序。
AWS Glue 爬网程序开始抓取数据库。这可能需要一分钟或更长时间才能完成。
完成后,在数据目录下,选择数据库。您应该能够看到 AWS Glue 爬网程序创建的新数据库。在此例中,数据库的名称为 blog。
要查看在此数据库下创建的表,请选择相关数据库,然后选择 表。爬网程序的表也指向 Parquet 格式 CDR 所在的位置。
要查看表的架构,请选择爬网程序创建的表。
数据准备
您已定义要在 ML 模型中用于检测欺诈的相关维度。如果您想练习数据准备部分而不是使用现有的已处理 Parquet 文件,您可以使用我之前使用 Amazon SageMaker 笔记本和 AWS Glue 终端节点构建的 PySpark 脚本。该脚本包含以下任务:
- 删减数据集并仅关注相关列。
- 创建时间戳列,使用 Amazon QuickSight 创建分析时需要。
- 将文件从 CSV 转换为 Parquet 以提高性能。
您可以对正在使用的原始 CSV 格式的 CDR 运行 PySpark 脚本。以下是原始 CSV 格式的位置:
s3://telco-source-bucket/machine-learning-for-all/v1.0.0/data/cdr-stop/cdr_stop.csv
这是我创建的 PySpark 脚本。
数据集已在 AWS Glue 数据目录中编目,并可使用 Athena 查询。
Amazon QuickSight 和异常检测
接下来,使用 Amazon QuickSight 构建异常检测。要开始使用,请按照以下步骤操作。
- 在 Amazon QuickSight 控制台中,选择新分析。
- 点击创建新数据集
- 选择 Athena
- 输入数据源名称
- 点击创建数据源
- 从下拉列表中选择由 AWS Glue 爬网程序创建的相关数据库和表,然后单击选择
- 选择直接查询您的数据,然后点击可视化
使用 Amazon QuickSight 可视化数据
- 在图表类型下,选择折线图。
- 将 call_service_duration 拖到值字段。
- 将 timestamp_new 拖动到 X 轴字段。
Amazon QuickSight 会生成一个控制面板,如以下屏幕截图所示。
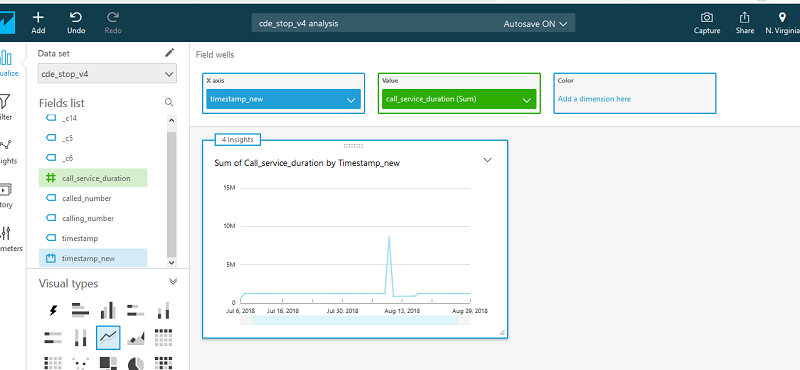
X 轴是时间戳。默认情况下,它基于一天的聚合。可以通过选择不同的值来更改此值。

由于我当前定义的时间戳查看的是一天的聚合,所以呼叫持续时间是一天内所有呼叫记录的所有呼叫持续时间的总和。我可以通过查找总呼叫持续时间长的日期来开始搜索。
异常检测
现在我们来看看如何开始使用 ML Insights 的异常检测功能。
- 在 Insights 面板的顶部,选择添加异常到工作表。此操作可为异常检测创建见解图表。
- 在屏幕顶部,选择字段区域并在类别中添加至少一个字段,如下例所示。我添加了呼叫/被叫号码,因为这些号码与欺诈案例有关;例如,一个 A 号码呼叫多个 B 号码或多个 A 号码呼叫 B 号码。

类别表示 Amazon QuickSight 拆分指标所依据的维度值。例如,您可以分析所有产品类别和产品 SKU 的销售异常 – 假设有 10 个产品类别,每个类别有 10 个产品 SKU。Amazon QuickSight 将按 100 个唯一组合拆分指标,并对拆分所得的每个指标运行异常检测。 - 要配置异常检测作业,请选择开始使用。
- 在异常检测配置屏幕上,设置以下选项:
- 分析所有类别组合 – 默认情况下,如果您选择了三个类别,Amazon QuickSight 将按层级对以下组合运行异常检测:A、AB、ABC。如果您选择此选项,QuickSight 将对所有组合进行分析:A、AB、ABC、BC、AC。如果您的数据没有分层,请选中此选项。
- 计划 – 设置该选项以按每小时、每天、每周或每月对数据运行一次异常检测,具体取决于您的数据和需求。对于计划开始时间和时区,输入值并选择确定。重要提示:在将分析作为控制面板发布之前,计划不会生效。在分析中,您可以选择手动运行异常检测(不设置计划)。异常归因分析 – 检测到异常后,您最多可以选择四个额外维度供 Amazon QuickSight 进行分析,以找到主要起因。例如,Amazon QuickSight 可以向您显示促使销售额激增的主要客户。在本例中,我添加了一个额外的维度:会计 ID。在电信欺诈案例中,您还可以考虑将充电时间或分区 ID 等字段作为额外维度。
- 设置完配置后,选择立即运行手动执行作业,这会出现“Detecting anomalies… This may take a while…”消息。根据数据集的大小,这可能需要几分钟到一个小时。
- 当异常检测作业完成时,在见解图表中会显示发现的异常。默认情况下,只有上个时间段数据中的最重要异常才会显示在见解图表中。

异常检测显示在 2018 年 8 月 29 日,有多个 A 号码呼叫多个 B 号码,并且呼叫服务持续时间长。这很耐人寻味! - 要查看此见解中的所有异常,请选择图表右上角的菜单,然后选择浏览异常。
- 在详细异常页面上,您可以看到最近一段时间检测出的所有异常。

在视图中,您可以看到检测到两个异常,显示两个时间序列。图表的标题表示在类别字段的唯一组合上运行的指标。在本例中:
- [All] | 9645000024
- 3512000024 | [ALL] 因此系统检测到多个 A 号码呼叫 9645000024 和 351200024 呼叫多个 B 号码存在异常。在这两种情况下,都观察到呼叫持续时间很长。图表上标记的数据点表示针对该时间序列检测到的最新异常。
- 要显示日期选择器,请在右上角选择按日期显示异常。此图表显示每天(或小时,取决于您的异常检测配置而定)检测到的异常的数量。您可以选择特定日期以查看当天检测到的异常。例如,在顶部图表中选择 2018 年 8 月 10 日可显示当天的异常:

重要提示: 数据集中的前 32 个点用于训练,不会计入异常检测算法中。您可能不会看到前 32 个数据点的任何异常。您可以在屏幕顶部展开筛选控件。使用筛选控件,您可以更改异常阈值以显示高、中或低重要性的异常。您可以选择仅显示高于预期或低于预期的异常。您还可以按数据集中的类别值进行筛选,以查看仅针对这些类别的异常。 - 查看起因列。配置异常检测时,定义了会计 ID 作为另一个维度。如果这是真正的呼叫流量而不是练习数据,您将能够找出导致异常的特定会计 ID。

- 完成后,选择返回分析。
小结
在本文中,我们探讨了一种称为共享收入欺诈的常见欺诈手段。我们探讨了如何提取相关数据以训练 Amazon QuickSight 中的异常检测模型。然后,我们使用这些数据基于呼叫持续时间、发话方和被叫方检测异常,查看会计 ID 等其他起因。整个过程使用无服务器技术,并且几乎不需要具备机器学习经验。
有关选项和策略的更多信息,请参阅 Amazon QuickSight 宣布正式发布 ML Insights。
如果您有任何问题或建议,请在下方留言。
关于作者
 Guy Ben Baruch 是 Amazon Web Services 的解决方案架构师。
Guy Ben Baruch 是 Amazon Web Services 的解决方案架构师。