亚马逊AWS官方博客
构建无服务化 EFS 文件浏览器
摘要:
最新发布的Lambda特性包含对EFS挂载的原生支持,EFS对Lambda的原生支持让Lambda第一次有了真正意义上的持久化存储和PB级数据访问的能力。
关键消息:
节省使用成本,提升开发效率
关键服务:
AWS Lambda,Amazon Elastic File System (Amazon EFS),Amazon API Gateway
正文内容
前言
在Lambda支持EFS的原生挂载前,原有EFS操作包括日常数据访问,定期数据备份,文件系统管理都需要借助EC2实例作为中间服务来实现EFS的挂载,进而操作EFS内数据。例如我们要实现EFS内数据的定期备份,通常的办法我们会利用到CloudWatch,Lambda来定时定期启动EC2实例,再通过配置User Data来控制EC2实例启动后操作逻辑包括源EFS挂载,EFS内数据压缩打包以及最终数据向S3的上传备份。参见下图我们可见EC2实例仅作为数据短暂的中间服务方存在,其执行效率和运行成本相较无服务架构下即时启动的Lambda对EFS的直接访问方式都稍显冗余且浪费。

上述方案Lambda部分参考代码如下,其中较大一部分逻辑都花费在EFS的挂载配置上,尽管我们通过脚本优化在数据备份完毕后关闭实例,仍然会有部分计算资源的浪费,毕竟Lambda实例启动和任务执行粒度都是毫秒级别。
除上述文件操作的场景外,我们也看到Lambda本身的限制如tmp目录存储大小(512MB),部署程序包大小(250MB),服务状态和函数结果无法固化等,使得原本适用无服务架构处理的场景变得不再适用,如超大媒体文件(图片,视频)的实时处理,AI/ML场景下预训练好的AI模型部署及第三方库的加载(TensorFlow,Pytorch),或者用户期望使用文件系统来获取依赖代码库(C++)。
基本原理
我们利用Lambda实现EFS的挂载和内部文件树遍历,将输出转换成JSON格式通过API Gateway返回到前端页面进一步解析展示,从而打造一个简易的无服务(Serverless)EFS文件浏览器。

配置步骤
创建EFS
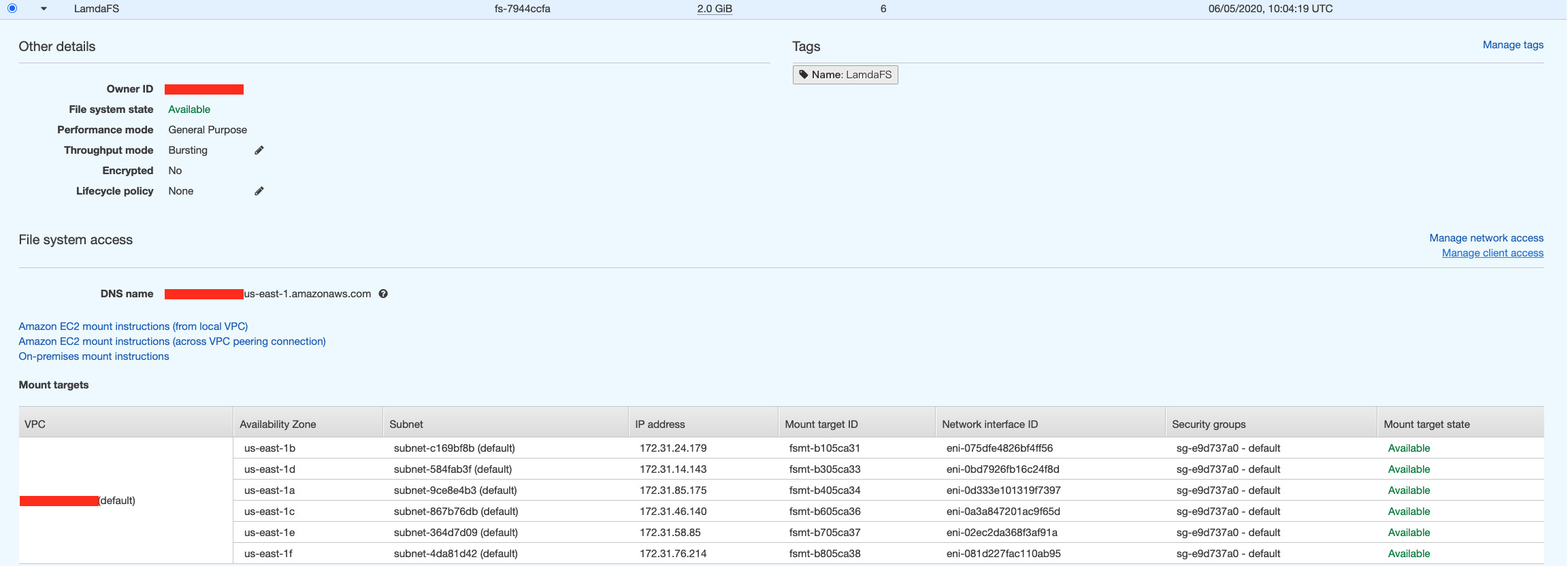
具体步骤在此不再赘述,可以参考该链接。创建完毕后的界面如下,注意后续创建的Lambda访问的VPC跟该EFS创建的VPC相同。
Lambda生成EFS目录树
创建Lambda
登陆到Lambda控制台,点击Create function,填入您的函数名(如LambdaFS)并选择相应的函数运行时(如Python3.8),其余按照默认选项设置,然后创建Lambda函数。

函数创建完毕后我们点击进入Permissions选项,查看Lambda函数当前的执行角色并点击进入相应的IAM服务界面。

进入IAM服务界面后点击Attach policies,添加VPC和EFS操作权限,分别是AWSLambdaVPCAccessExecutionRole和AWSLambdaVPCAccessExecutionRole。需要注意以上IAM策略仅作为演示作用,实际场景您应按照最小使用原则调整策略来保障服务的安全性。

IAM配置完毕后进入原有Lambda界面添加对应的VPC,子网和安全组,注意该VPC跟您在前面步骤启动的EFS相同。

接下来在File system选项中添加之前创建的EFS并选择本地挂载路径(如/mnt/demo)

创建完毕后Lambda面板上显示的文件系统信息如下所示

接着利用Lambda来遍历该EFS中文件目录以及文件,生成对应的目录层级,文件大小信息并转换成JSON格式输出,代码如下:
API Gateway集成
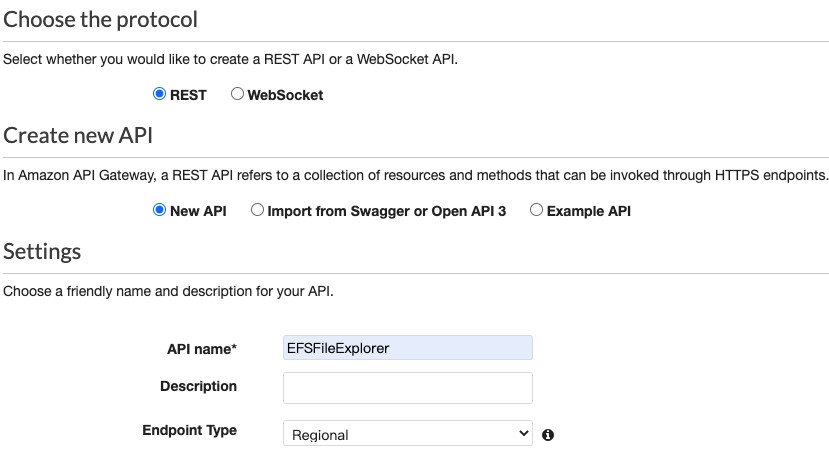
在此我们创建一个API Gateway来为刚才创建的Lambda提供前端访问接口,以REST API为例,在Create new API选项中选择New API,命名您的API名字(如EFSFileExplorer)其他选项默认,点击Create API。
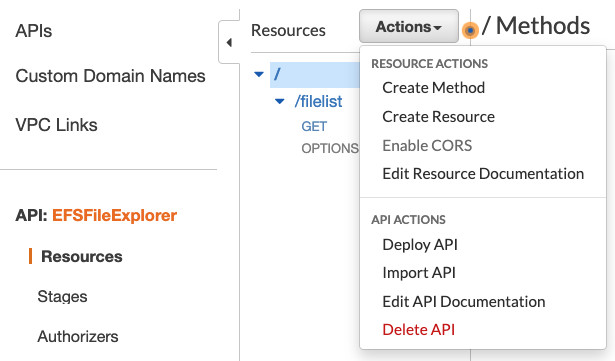
接下来创建API资源,点击Actions,选择Create Resource,填写您的Resource Name和对应的Resource Path(如filelist),再次点击Create Resource,资源创建完毕后在该资源下创建对应的Resource Method,点击Create Method然后选择GET,创建完毕后的资源列表如下所示。
继续选择GET方法然后选择Method Execution选择之前创建的Lambda作为处理API请求的后端服务,其他配置默认然后保存。

在此之后点选Actions,选择Deploy API来部署上线,Deployment Stage选择New Stage并填入版本信息等字段(如prod),部署完毕后您会看到类似https://xxxxxxxx.execute-api.us-east-1.amazonaws.com/prod的URL作为前端Web调用的入口。至此,无服务化 EFS文件浏览器的主要服务搭建完成。

随机文件生成
为进一步验证方案中Lambda拉取EFS目录树格式的正确性和运行效率,我们通过构建一个简单的Lambda函数来随机向同一个EFS中写入多个名字随机,大小随机的文件。Lambda对该EFS的挂载不再赘述,参照上述流程即可,复制并执行以下Lambda代码。该代码将生成10个目录,每个目录包含10个文件,其中每个文件名为长度从6到12的随机字符,文件大小从24到48字节随机。额外注意我们需要相应上调Lambda的超时时间,默认是3秒,这里我们调整成30秒。
前端拉取展示
我们先通过Postman或者CURL来验证API Gateway所返回的JSON信息是否正确,正常的GET结果如下,其中包含了目录层级,文件大小等信息:

接下来将该URL嵌入到前端代码(如JavaScript)中来实现JSON结果的拉取和展示,代码片段如下:
将获取到的JSON数据利用Vue.js等JS框架创建单页应用进行展示,示例最终效果如下:

小结
EFS对Lambda的原生支持让Lambda第一次有了真正意义上的持久化存储和PB级数据访问的能力,使得Lambda在大文件即时处理,机器学习推理等场景能更加出色的发挥出无服务架构在性能,成本和灵活性方面的优势。