亚马逊AWS官方博客
使用 Amazon SageMaker、Amazon OpenSearch Service、Streamlit 和 LangChain 构建功能强大的问答机器人
我们提供了一个 AWS Cloud Formation 模板,来支持构建此解决方案所需的所有资源。然后,演示如何使用 LangChain 将所有内容串联起来:
- 与 Amazon SageMaker 托管的 LLM 进行交互。
- 对知识库文档进行分块。
- 将文档嵌入内容摄取到 Amazon OpenSearch Service 中。
- 执行问答任务。
我们可以使用相同的架构将开源模型与 Amazon Titan 模型互换。Amazon Bedrock 推出后,我们会发布一篇后续博文,展示如何使用 Amazon Bedrock 实现类似的生成式人工智能应用程序,敬请关注。
解决方案概览
我们使用 SageMaker 文档作为这篇博文的知识语料库。我们将该网站上的 HTML 页面转换成较小的重叠信息块(以保留信息块之间的上下文连续性),然后使用 gpt-j-6b 模型将这些信息块转换成嵌入式信息,并将嵌入式信息存储在 OpenSearch Service 中。我们使用 Amazon API Gateway 在 AWS Lambda 函数中实现 RAG 功能,将所有请求路由到 Lambda。我们在 Streamlit 中实现了一个聊天机器人应用程序,该应用程序通过 API Gateway 调用该函数,而该函数在 OpenSearch Service 索引中对用户问题的嵌入信息进行相似性搜索。Lambda 函数会将匹配的文档(信息块)作为上下文添加到提示中,然后使用部署为 SageMaker 端点的 flan-t5-xxl 模型来生成用户问题的答案。这篇博文的所有代码都可以在 GitHub 存储库中找到。
下图显示了所建议解决方案的高级架构。
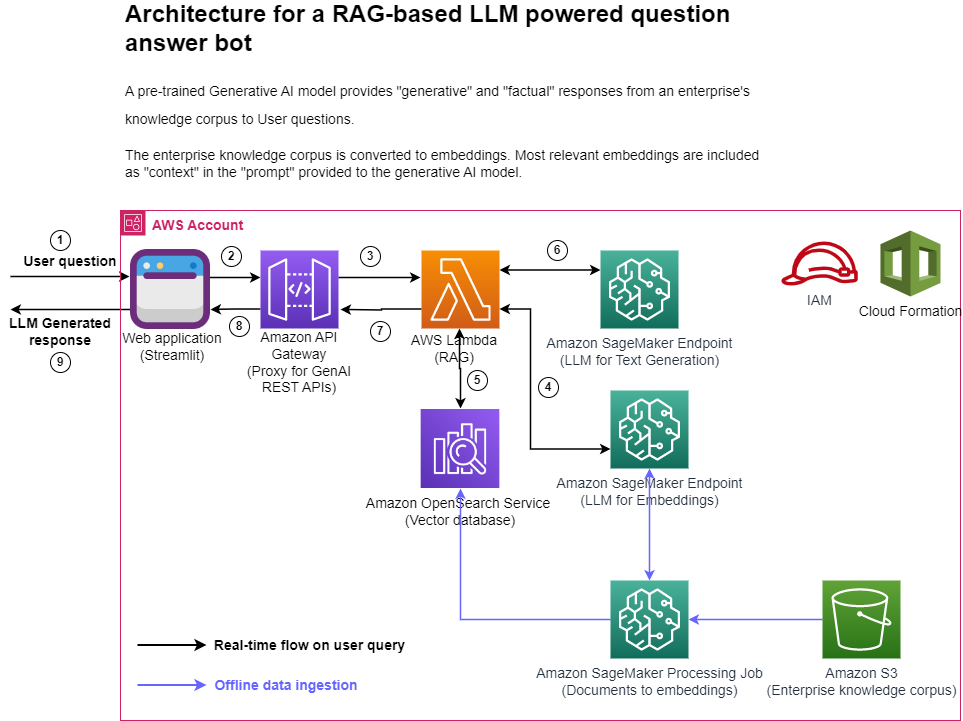
图 1:架构
分步说明:
- 用户通过 Streamlit Web 应用程序提出问题。
- Streamlit 应用程序调用 API Gateway 端点 REST API。
- API Gateway 调用 Lambda 函数。
- 该函数调用 SageMaker 端点将用户问题转换为嵌入内容。
- 该函数调用 OpenSearch Service API 来查找与用户问题相似的文档。
- 该函数以用户查询和“类似文档”为上下文创建“提示”,并要求 SageMaker 端点生成响应。
- 响应由该函数提供给 API Gateway。
- API Gateway 为 Streamlit 应用程序提供响应。
- 用户可以在 Streamlit 应用程序上查看响应。
如架构图所示,我们使用以下 AWS 服务:
- SageMaker 和 Amazon SageMaker JumpStart,用于托管两个 LLM。
- OpenSearch Service,用于存储企业知识语料库的嵌入内容,并对用户问题进行相似性搜索。
- Lambda,用于实现 RAG 功能并通过 API Gateway 将其作为 REST 端点公开。
- Amazon SageMaker Processing 作业,用于将大规模数据摄入到 OpenSearch。
- Amazon SageMaker Studio,用于托管 Streamlit 应用程序。
- AWS Identity and Access Management 角色和策略,用于访问管理。
- AWS CloudFormation,用于通过基础设施即代码创建整个解决方案堆栈。
就该解决方案中使用的开源软件包而言,我们使用 LangChain 与 OpenSearch Service 和 SageMaker 进行连接,并使用 FastAPI 在 Lambda 中实现 REST API 接口。
要在您自己的 AWS 账户中实例化这篇博文中介绍的解决方案,工作流程如下:
- 在您的账户中运行这篇博文附带的 CloudFormation 模板。这样可以创建该解决方案所需的所有必要的基础设施资源:
- LLM 的 SageMaker 端点
- OpenSearch Service 集群
- API Gateway
- Lambda 函数
- SageMaker notebook
- IAM 角色
- 在 SageMaker notebook 中运行 data_ingestion_to_vectordb.ipynb notebook,将 SageMaker 文档中的数据摄取到 OpenSearch Service 索引中。
- 在 Studio 的终端上运行 Streamlit 应用程序,并在新的浏览器标签页中打开该应用程序的 URL。
- 通过 Streamlit 应用程序提供的聊天界面,提出有关 SageMaker 的问题,并查看 LLM 生成的回复。
以下各节将详细讨论这些步骤。
先决条件
要实施这篇博文中提供的解决方案,您应该有一个 AWS 账户,并且熟悉 LLM、OpenSearch Service 和 SageMaker。
我们需要使用加速实例(GPU)来托管 LLM。此解决方案使用 ml.g5.12xlarge 和 ml.g5.24xlarge 的各一个实例;您可以在 AWS 账户中查看这些实例是否可用,并根据需要通过服务限额增加请求来请求这些实例,如以下屏幕截图所示。
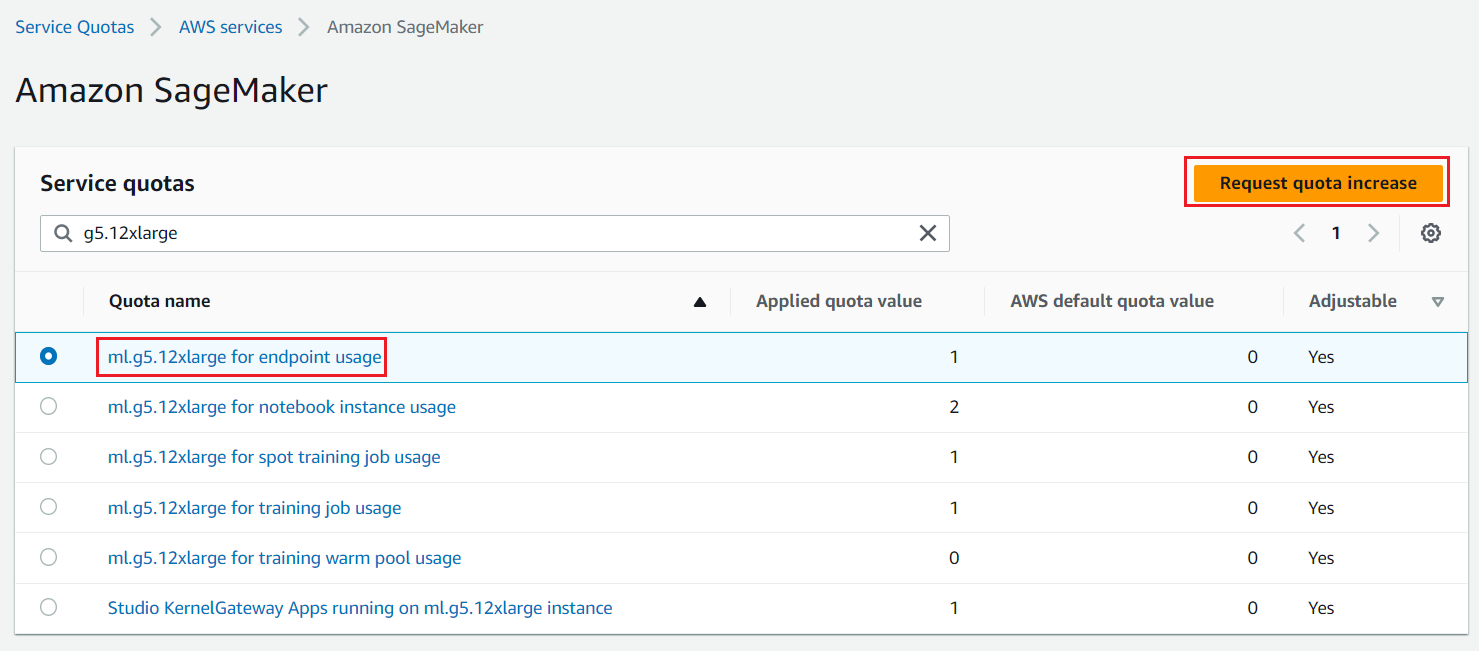
图 2:服务限额增加请求
使用 AWS Cloud Formation 创建解决方案堆栈
我们使用 AWS CloudFormation 创建一个名为 aws-llm-apps-blog 的 SageMaker notebook 和一个名为 LLMAppsBlogIAMRole 的 IAM 角色。为要部署资源的区域选择启动堆栈。CloudFormation 模板所需的所有参数都已填入默认值,只有 OpenSearch Service 密码需要您提供。请记下 OpenSearch Service 的用户名和密码,我们将在后续步骤中加以使用。此模板大约需要 15 分钟才能完成。
| AWS 区域 | 链接 |
|---|---|
us-east-1 |
|
us-west-2 |
|
eu-west-1 |
|
ap-northeast-1 |
成功创建堆栈后,在 AWS CloudFormation 控制台上导航到堆栈的 Outputs(输出)选项卡,记下 OpenSearchDomainEndpoint 和 LLMAppAPIEndpoint 的值。我们将在后续步骤中使用这些值。
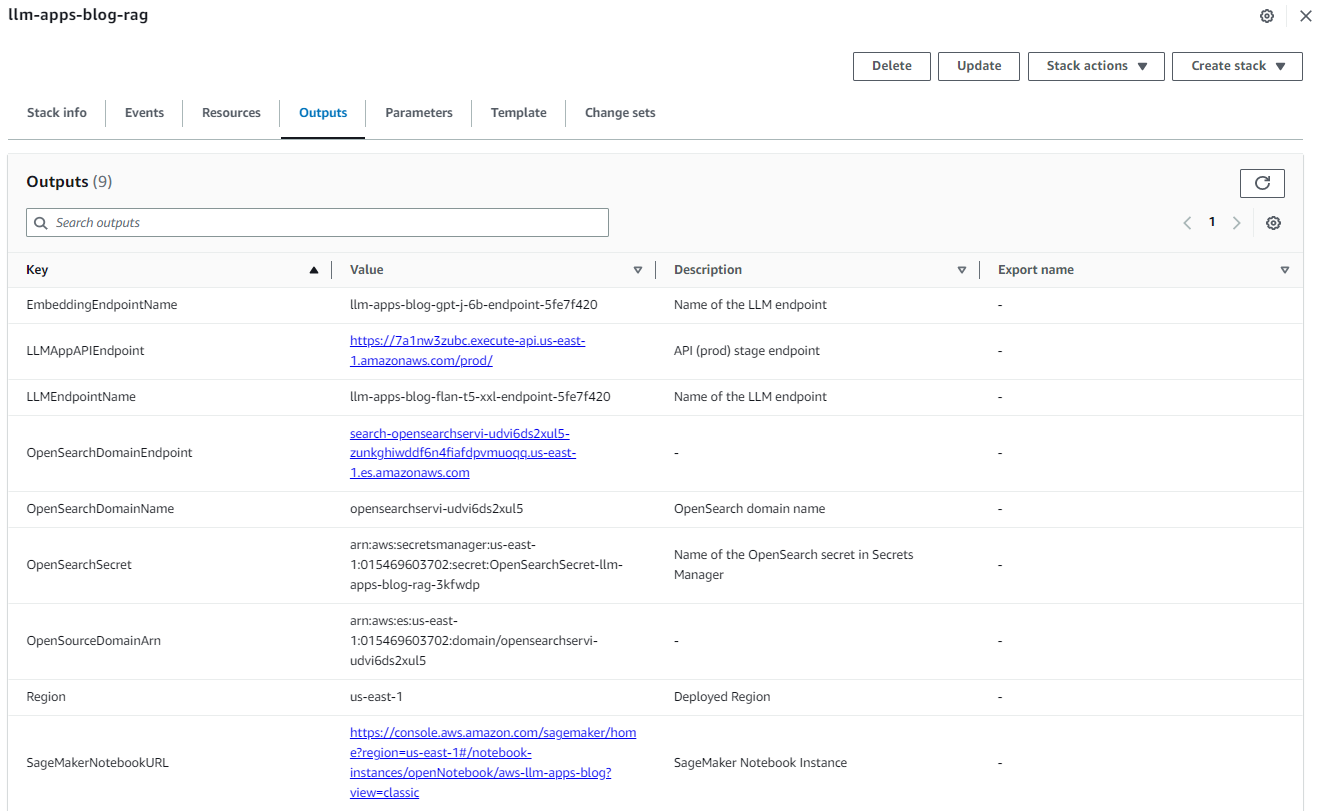
图 3:CloudFormation 堆栈输出
将数据摄取到 OpenSearch Service 中
要摄取数据,请完成以下步骤:
- 在 SageMaker 控制台的导航窗格中,选择 notebook。
- 选择 notebook
aws-llm-apps-blog,然后选择打开 JupyterLab。
图 4:打开 JupyterLab
- 选择 data_ingestion_to_vectordb.ipynb 以在 JupyterLab 中打开。该 notebook 会将 SageMaker 文档摄取到名为
llm_apps_workshop_embeddings的 OpenSearch Service 索引中。
图 5:打开数据摄取 notebook
- 打开 notebook 后,在“运行”菜单上选择运行所有单元,即可运行此 notebook 中的代码。这会将数据集下载到本地 notebook 中,然后将数据集摄取到 OpenSearch Service 索引中。此 notebook 的运行时间约为 20 分钟。它还会将数据摄取到另一个名为 FAISS 的矢量数据库中。FAISS 索引文件保存在本地,然后上传到 Amazon Simple Storage Service(S3),这样 Lambda 函数就能够选用这些文件,作为使用替代矢量数据库的示例。

图 6:notebook 运行所有单元
现在,我们准备将文档拆分成多个信息块,然后将这些信息块转换成嵌入式内容以摄取到 OpenSearch 中。我们使用 LangChain RecursiveCharacterTextSplitter 类对文档进行分块,然后使用 LangChain SagemakerEndpointEmbeddingsJumpStart 类通过 gpt-j-6b LLM 将这些信息块转换为嵌入式内容。我们通过 LangChain OpenSearchVectorSearch 类将嵌入式内容存储在 OpenSearch Service 中。我们将这些代码打包到 Python 脚本中,这些脚本通过自定义容器提供给 SageMaker Processing 作业。有关完整代码,请参阅 data_ingestion_to_vectordb.ipynb notebook。
- 创建一个自定义容器,然后在其中安装 LangChain 和 opensearch-py Python 软件包。
- 将此容器映像上传到 Amazon Elastic Container Registry(ECR)。
- 我们使用 SageMaker ScriptProcessor 类创建一个将在多个节点上运行的 SageMaker Processing 作业。
- 通过设置
s3_data_distribution_type='ShardedByS3Key'(作为提供给处理作业的ProcessingInput的一部分),Amazon S3 中的数据文件会自动分布到各个 SageMaker Processing 作业实例中。 - 每个节点处理一个文件子集,这样就缩短了将数据摄取到 OpenSearch Service 所需的总时间。
- 每个节点还使用 Python 多处理技术在内部并行处理文件。因此,并行化有两个层面,一个是在集群层面,在各个节点之间分配工作(文件);另一个是在节点层面,节点中的文件也在节点上运行的多个进程之间分割。
- 通过设置
- 在所有单元运行无误后,关闭 notebook。您的数据现已在 OpenSearch Service 中可用。在浏览器地址栏中输入以下 URL,即可获得
llm_apps_workshop_embeddings索引中的文档数量。使用以下 URL 中的 CloudFormation 堆栈输出中的 OpenSearch Service 域端点。系统会提示您输入 OpenSearch Service 用户名和密码,可从 CloudFormations 堆栈中获得它们。
浏览器窗口应显示类似于以下内容的输出。输出结果显示,有 5667 个文档被摄取到 llm_apps_workshop_embeddings 索引。{"count":5667,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0}}
在 Studio 中运行 Streamlit 应用程序
现在,我们准备为问答机器人运行 Streamlit Web 应用程序。此应用程序允许用户提问,然后通过 Lambda 函数提供的 /llm/rag REST API 端点获取答案。
Studio 提供了一个便捷的平台来托管 Streamlit Web 应用程序。以下步骤介绍如何在 Studio 上运行 Streamlit 应用程序。或者,您也可以按照相同的步骤在 notebook 上运行此应用程序。
- 打开 Studio,然后打开一个新终端。
- 在终端上运行以下命令来克隆这篇博文的代码存储库,并安装此应用程序所需的 Python 软件包:
- 在 webapp.py 文件中,需要设置 CloudFormation 堆栈输出中可用的 API Gateway 端点 URL。这是通过运行以下
sed命令来完成的。将 Shell 命令中的replace-with-LLMAppAPIEndpoint-value-from-cloudformation-stack-outputs替换为 CloudFormation 堆栈输出中LLMAppAPIEndpoint字段的值,然后运行以下命令在 Studio 上启动 Streamlit 应用程序。 - 此应用程序成功运行后,您将看到类似于以下内容的输出(您将看到的 IP 地址与本例中显示的不同)。记下输出中的端口号(通常为 8501),在下一步中会用作应用程序 URL 的一部分。
- 您可以使用与 Studio 域 URL 相似的 URL,在新的浏览器标签页中访问此应用程序。例如,如果 Studio URL 是
https://d-randomidentifier.studio.us-east-1.sagemaker.aws/jupyter/default/lab?,则 Streamlit 应用程序的 URL 将是https://d-randomidentifier.studio.us-east-1.sagemaker.aws/jupyter/default/proxy/8501/webapp(注意,lab替换为proxy/8501/webapp)。如果在上一步记下的端口号不是 8501,则在 Streamlit 应用程序的 URL 中使用该端口号,而不是 8501。
以下屏幕截图显示了该应用程序,其中包含几个用户问题。

进一步了解 Lambda 函数中的 RAG 实现
现在我们已经让应用程序端到端运行了,让我们进一步了解一下 Lambda 函数。Lambda 函数使用 FastAPI 实现 RAG 的 REST API,并使用 Mangum 软件包将 API 与我们打包并部署在函数中的处理程序封装在一起。我们使用 API Gateway 来路由所有传入的请求,以调用该函数并在应用程序内部处理路由。
下面的代码片段展示了我们如何在 OpenSearch 索引中查找与用户问题相似的文档,然后将问题和相似文档结合起来创建提示。接着向 LLM 提供此提示,以便生成用户问题的答案。
清理
为避免将来产生费用,请删除资源。您可以通过删除 CloudFormation 堆栈来实现此目的,如以下屏幕截图所示。

图 7:清理
总结
在这篇博文中,我们展示了如何结合使用 AWS 服务、开源 LLM 和开源 Python 软件包,来创建企业级 RAG 解决方案。
我们鼓励您探索 JumpStart、Amazon Titan 模型、Amazon Bedrock 和 OpenSearch Service,并使用本博文提供的实现示例和与您业务相关的数据集来构建解决方案,从而了解更多信息。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
关于作者
 Amit Arora 是 Amazon Web Services 的人工智能和机器学习专家架构师,协助企业客户使用基于云的机器学习服务来快速扩展他们的创新。他还是华盛顿特区乔治敦大学数据科学与分析硕士课程的兼职讲师。
Amit Arora 是 Amazon Web Services 的人工智能和机器学习专家架构师,协助企业客户使用基于云的机器学习服务来快速扩展他们的创新。他还是华盛顿特区乔治敦大学数据科学与分析硕士课程的兼职讲师。
 Xin Huang 博士是 Amazon SageMaker JumpStart 和 Amazon SageMaker 内置算法的高级应用科学家。他专注于开发可扩展的机器学习算法。他的研究兴趣是自然语言处理、表格数据的可解释深度学习以及非参数时空聚类的稳健分析。他曾在 ACL、ICDM、KDD Conference 和 Royal Statistical Society: Series A 上发表过多篇论文。
Xin Huang 博士是 Amazon SageMaker JumpStart 和 Amazon SageMaker 内置算法的高级应用科学家。他专注于开发可扩展的机器学习算法。他的研究兴趣是自然语言处理、表格数据的可解释深度学习以及非参数时空聚类的稳健分析。他曾在 ACL、ICDM、KDD Conference 和 Royal Statistical Society: Series A 上发表过多篇论文。
 Navneet Tuteja 是 Amazon Web Services 的数据专家。在加入 AWS 之前,Navneet 曾为寻求数据架构现代化和实施全面人工智能/机器学习解决方案的组织担任推动者。她拥有塔帕尔大学的工程学学位和德克萨斯农工大学的统计学硕士学位。
Navneet Tuteja 是 Amazon Web Services 的数据专家。在加入 AWS 之前,Navneet 曾为寻求数据架构现代化和实施全面人工智能/机器学习解决方案的组织担任推动者。她拥有塔帕尔大学的工程学学位和德克萨斯农工大学的统计学硕士学位。