亚马逊AWS官方博客
使用 Amazon EC2 Spot 实例和 Amazon EMR 运行 Apache Spark 应用程序的最佳实践
Apache Spark 已成为运行分析作业的最流行工具之一。之所以受欢迎,是因为它具有易用性、快速的性能、内存和磁盘利用率高以及内置容错能力等优点。这些特性与云计算的概念(实例可以是一次性的、临时的)密切相关。
Amazon EC2 Spot 实例提供 AWS 云中可用的备用容量,与按需价格相比,具有极低的折扣。 当EC2 需要回收容量时,EC2 可中断 Spot 实例并提前两分钟发送通知。您可将Spot实例用于各种需要容错和灵活性的应用场景。例如,分析、容器化工作负载、高性能计算 (HPC)、无状态 Web 服务器、渲染、CI/CD 以及其他测试和开发工作负载。
Amazon EMR 提供了一个托管 Hadoop 框架,让用户可以简便、快速和经济高效地使用EC2实例处理大量数据。使用 Amazon EMR 时,您无需考虑Spark 软件或 Hadoop 框架中的任何其他工具的安装、升级和维护工作。也同样无需考虑底层硬件或操作系统的安装和维护工作。相反,您可以专注于您的业务应用程序,使用 Amazon EMR 来消除繁重的重复性工作。
在本博客中,我们将重点讨论如何通过使用 Spot 实例在 Amazon EMR 上实现成本优化并高效运行 Spark 应用程序。我们提供了几个最佳实践建议,用于在使用Spot实例过程中提高Spark应用程序的容错能力。实施这些最佳实践不会对Spark应用程序的可用性,性能和执行时间产生大的影响。
使用 Spot Instance Advisor发现具有合适中断率的实例类型
如前所述,如果 EC2 需要回收容量,可以中断 Spot 实例。在本博客中,我们将分享一些如何提高 Spark 应用程序容错能力的最佳实践,以应对由于 Spot 中断而导致的底层 EC2 实例的偶尔丢失。即使这样,使用具有更低中断率的 EC2 Spot 实例类型也可以进一步提供帮助。当中断发生时,Spark 需要重做一些工作,导致您的作业执行时间变长。这种方法有助于减少此类情况的发生。
使用 Spot Instance Advisor 检查中断率,并尽量使用过去一段时间中断率较低的实例类型创建 Amazon EMR 集群。例如,在撰写本文之时,美东(俄亥俄)区域 r4.2xlarge 的中断频率低于 5%。这意味着,在过去 30 天内启动的所有 r4.2xlarge Spot 实例中,只有不到 5% 被 EC2 中断。
在多种实例类型上运行您的 Spot 工作负载
当您在 EC2 实例上运行工作负载(分析或其他任务)并且使用了按需或预留实例购买选项时,通常可以在整个集群中使用单个实例类型。您可以在基准测试之后执行此操作,以便找到合适的实例类型来满足应用程序要求。但是对于 Spot 实例,在一个集群中使用多个 Spot 容量池(一个可用区中的一种实例类型)是用好Spot 实例的关键所在。此实践使您能够实现扩展并预留用于运行作业的足够容量。
例如,假设我正在使用按需 r4.xlarge 实例(30.5 GiB 内存和 4 个 vCPU)运行 Spark 应用程序。当开始使用 Spot 实例时,我可以使用包括多种实例类型的核心或任务队列来配置Amazon EMR 集群,这些实例类型具有近似的vCPU数量对内存大小的比例(大约每个 vCPU 需要7GB内存),让 EMR 选择合适的实例类型在集群中运行。这些实例类型包括 r4.2xlarge、r5.xlarge、i3.2xlarge 和 i3.4xlarge。采用这个方法后,我有更大可能拥有足够的 Spot 容量来启动集群。此外,还可以增加 Amazon EMR 从其他容量池补充集群所需容量并继续运行的机会,以防止集群中的一些实例因 EC2 Spot 中断而被终止。
| 实例类型 | vCPU 数量 | RAM (GB) |
| R4.xlarge | 4 | 30.5 |
| R4.2xlarge | 8 | 61 |
| R5.xlarge | 4 | 32 |
| I3.2xlarge | 8 | 61 |
| I3.4xlarge | 16 | 122 |
调整 Spark Executor的大小以允许使用多种实例类型
如前所述,要让应用在 Spot 实例上顺利运行,一个关键要素是使用多样化的实例类型。此外,这还有助于缓解 Spot 中断对作业的影响。这种方式也限制了您的Spark 应用程序的架构。
运行内存密集型Spark Executor(内存超过 20GB)会将您的应用程序绑定到一组特定大小的实例类型,它们可能没有足够的 Spot 容量来启动您的集群。此外,它们的 Spot 中断率可能也较高,从而可能会对正在运行的作业产生影响。
例如,对于一个每Executor需要 90 GiB 内存和 15 个vCPU核的 Spark 应用程序,只有 11 个实例类型符合硬件配置要求,并且 Spot 中断率低于 20%。假如我们按照为每个vCPU核分配 6 GiB 内存的比率把Executor拆小,让一个Executor只使用2个vCPU核。如果我们确实这样做了,我们将增加 额外20个可以运行我们作业的实例类型(中断率低于 20%)。
调整Executor大小的一种公正方法是确定运行应用程序的最小vCPU核数。从最开始2个vCPU核开始逐渐增加是个不错的方式。然后使用以下计算公式分配内存:
NUM_CORES * ((EXECUTOR_MEMORY + MEMORY_OVERHEAD) / EXECUTOR_CORES)
在我们的示例中,为 2 * (( 90 + 20 ) / 15) = 15GB
有关Spark额外预留内存设置的更多信息,请参阅 Spark 文档。
在 Spark 中避免大量的混洗操作
如果 您的Amazon EMR 集群中的 Spot 实例被中断,为减少 Spark 需要重新处理的数据量,应该避免大量的混洗操作。
广泛依赖的操作比如 GroupBy 和某些类型的Join会产生大量的中间数据。中间数据存储在本地磁盘上,然后被打乱发送给集群中的其他Executor。
尽管不能总是做到这一点,但我们仍然建议要么避免混洗操作,要么减少需要混洗的数据量。我们建议这样做的原因有两个:
- 这是一个通用的 Spark 最佳实践,因为混洗操作开销很大。
- 在 Spot 实例的使用场景中,这样做会降低作业的容错能力。因为丢失一个带有混洗数据或者依赖混洗数据进行计算的节点(很多节点经常是两个条件都满足)需要你重新执行部分的混洗过程。
我们发现有几种开发模式会产生不必要的混洗数据,如下所述。
展开再聚合模式
从开发人员的角度来看,对某些复杂数据类型执行展开(explode)可能是某些场景下非常快速的解决方案(比如将数组中的内容展开变为多行)。于是我们的记录数增加了几倍,接下来我们还可以在作业中把它们聚合在一起。
例如,假设我们的数据包含用户 ID 和描述网站访问情况的日期数组:
| A | B | |
| 1 | user_id | visit_dates_array |
| 2 | 0 | [ “28/01/2018”29/01/2018”, “01/01/2019”] |
| 3 | 100000 | [ “01/11/2017”, “01/12/2017”] |
| 4 | 999999 | [ “01/01/2017”, “02/01/2017”, “03/01/2017”, “04/01/2017”, “05/01/2017”, “06/01/2017”] |
假设我们需要运行一个 Spark 应用程序来计算各个用户访问网站的次数。在这种情况下,一个简单的解决方案就是使用explode函数展开访问日期数组,然后聚合数据,如下所示。
展开数据:
重新聚合数据:
虽然这种方法快速而简单,但是会将记录数增加到原来的三倍。要精确计算出每个 user_id 的访问次数之和,还必须通过网络将我们的数据传输给其他Executor。
除了展开然后分组求和,还有哪些方案可选?
一个办法就是开发一个直接计算求和的 UDF,以避免或尽量减少混洗操作。以下是 Scala 语言开发的例子。
另外一个方法是利用Spark 2.4最近推出的聚合函数。这个函数也可以将混洗数据量减少到最低限度,只保留 user_id 及其访问次数:
海量数据联接(数据分桶)
执行Join操作时,Spark 将按联接键重新分区(混洗)数据。
如果对同一个表或具有相同键的多个表执行多次Join,则只能使用分桶操作来混洗数据一次。等保存数据时,使用同一键的数据的任何后续Join操作都不需要混洗,因为数据已经在 Amazon S3 上“被提前混洗”。
要对数据进行分桶,您需要确定数据分桶的数量和执行数据分桶参考的字段。
处理数据分布不均
在某些情况下,数据没有在分区之间均匀地分布。有几个原因造成这个问题:
- 通常情况下,大多数Executor都会及时完成。但是那些处理大量异常数据的Executor会执行更长时间。这就增加了因为遭受 Spot 实例中断而不得不重新计算整个作业的风险。不仅如此,这还会对整体性能产生负面影响,延长作业执行时间或导致资源未得到充分利用。
- 数据分布不均也可能会致使出现大量混洗数据,从而可能导致出现前述问题。
要处理数据分布分布不均,我们建议你在Executor所在节点执行感兴趣的计算。然后再跨节点将执行结果进行汇总计算,此方法也称为合并操作。
处理数据分布不均的一种常见技术是对键值进行加盐处理。
将大型Spark 作业拆小以增加弹性
我们遇到的一个反模式是大型应用程序执行着可能需要数小时甚至数天才能完成的很多作业。
这样的大型作业会造成要么完全执行成功,要么彻底执行失败的局面。在运行作业的整个过程中的任何一个问题都会导致作业执行失败,带来用户时间和金钱方面的损失。
这个结论其实显而易见。但是用户可以把大型作业拆分成一系列更小的作业来提高应对故障情况和Spot实例中断的弹性。拆分作业还意味着,您可以及时纠正任何阻止作业顺利完成的问题,而且这样做还可减少丢失已完成工作的几率。
使用 Amazon EMR 实例队列
您可以在一些技术中使用 Amazon EMR 实例队列来高效利用 Spark。
使集群中的 EC2 实例类型多样化
通过配置 Amazon EMR 实例队列,您可以为每个 Amazon EMR 节点类型(主节点、核心节点、任务节点)设置最多包含五个 EC2 实例类型的队列。如前所述,灵活的实例类型选择是启动和维护您的Amazon EMR 集群Spot 容量的关键。
对于主节点组,Amazon EMR 会从您挑选的实例类型中选择一个实例。在核心节点和任务节点组中,Amazon EMR 会根据Spot实例容量可用性和低价格因素选择最佳实例类型用于集群。此外,您还可以在不同的可用区中指定多个子网。在这种情况下,Amazon EMR 选择最符合目标容量需求的 AZ 来启动整个集群。
根据作业的硬件配置要求调整 Amazon EMR 实例队列的大小
Amazon EMR 实例队列允许您通过指定适合您应用程序的实例类型来定义资源池。您还可以指定每个实例类型在池中所承担目标容量的权重。
默认情况下,实例的权重大小等于它们拥有的 vCPU 数量。不过,也可以根据其他实例特征(如内存)来分配权重,我将在本节对此进行演示。
按 CPU 调整:
例如,假设我有一个作业,要求每个Executor 4 个核,每个核 1GB RAM,因此 Spark 配置如下:
–executor-cores 4 –executor-memory 4G
我们希望该作业由 20 个Executor执行,这意味着需要 80 个核 (20*4):
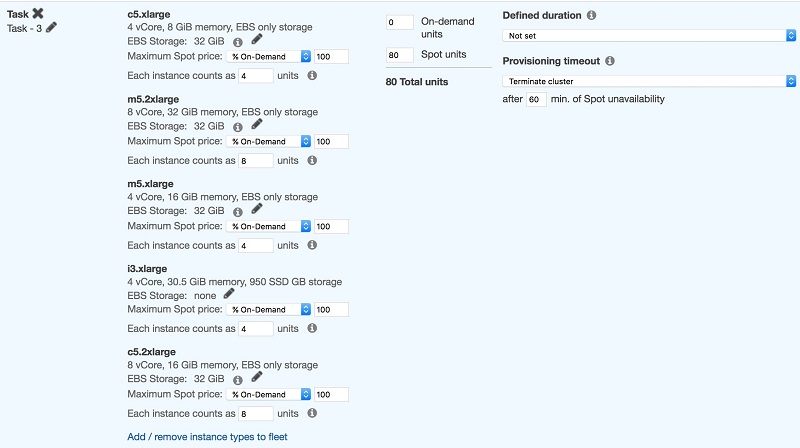
屏幕截图显示 80 个 Spot 单元,表示运行此作业需要 80 个核。它还显示了为满足硬件要求而选择的各种实例类型。
Amazon EMR 选择这些实例类型的任意组合以满足 80 个 Spot 单元的目标容量,而一些较大的实例类型可能会运行多个Executor。
按内存调整:
某些 Spark 应用程序是内存密集型的,需要使用不同的权重策略。
例如,如果我们的作业运行时需要使用四个核,每个核 6GB (–executor-cores 4 –executor-memory 24G),我们首先必须先选择 RAM 至少为 28GB 的实例:
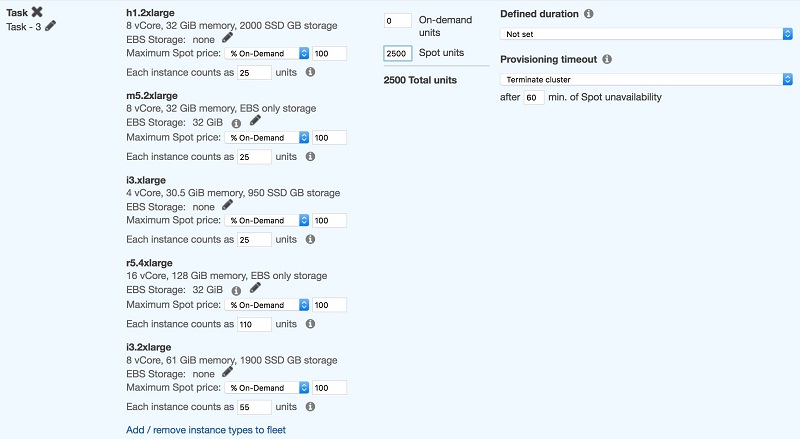
如屏幕截图所示,在此配置中,实例类型选择设置为满足作业内存要求,同时为实例操作系统中运行的其他进程留出 15% 到 20% 的可用内存。
然后将符合条件的最小实例类型的可用内存单元数与所需Executor数量相乘 (25*100),计算出单元总数。
与 CPU 密集型作业一样,有些实例类型只运行一个Executor,而有些则会运行多个Executor。
弥合各代实例类型之间的性能差异
某些工作负载仅仅因为在较新的实例类型上运行,性能就会提高多达 50%。这种效果要归功于 AWS Nitro 技术、快速的 CPU 时钟速度或不同的 CPU 架构(从 Haswell/Broadwell 迁移到 Skylake),或者这些因素的组合。
如果减少应用程序运行时间是一项重要要求,则可以通过为老一代实例类型指定较小的权重来抵消各代实例类型之间的性能差异。
例如,假设您的作业通过 10 个 r5.2xlarge 实例需要运行一个小时,而通过 10 个 r4.2xlarge 实例则要运行两个小时。在这种情况下,您可能希望按照以下方式定义实例队列:
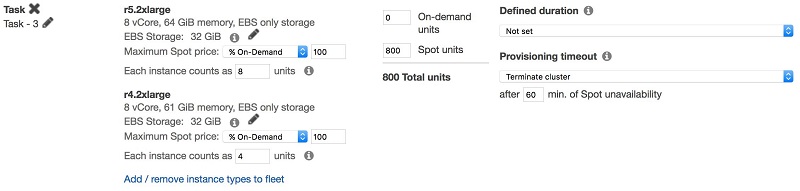
为每个节点类型选择适当的购买选项
Spot Blocks是定义了持续运行时间的 Spot 实例,最长可运行 6 个小时而不被中断,与标准 Spot 实例相比,折扣率会低些。但是,如果您的作业不能忍受 Spot 中断,并且预计集群运行时间小于 6 小时,那么可以考虑使用 Spot Blocks。
主节点:除非您的集群生命周期十分短暂,并且非常在意成本节省,否则请避免在 Spot 实例上运行主节点。我们这样建议的原因是主节点上的 Spot 中断将终止整个集群。作为按需实例的替代方案,您可以在 Spot Blocks上设置主节点。您可以设置该节点的预定义持续运行时间,并在 Spot Blocks容量不可用时故障转移到按需实例。
核心实例:如果集群上的作业使用 HDFS,则要避免对核心节点使用 Spot 实例。这样可防止出现以下情况:Spot 中断导致写入实例上的 HDFS 卷里面的数据丢失。
任务节点:对您的任务节点使用 Spot 实例,最多选择五个满足硬件配置要求的实例类型。Amazon EMR 通过考量价格和容量可用性等因素来满足容量需求。
收到 EC2 Spot 中断通知
当 EC2 需要中断 Spot 实例时,会对每个将要被中断的Spot实例提前 2 分钟发出告警。您可以通过两种手段以编程方式对告警作出响应:在实例中轮询当前实例的元数据服务或者使用 Amazon CloudWatch Events。有关具体信息,请参阅该文档。
对于此类告警的响应方式因工作负载类型而有所不同。例如,您可以选择将即将被中断的Spot实例从 弹性负载均衡器分离,以便在实例关闭之前耗尽运行中的连接。或者您可以将日志复制到一个集中位置,也可以正常关闭应用程序。
要了解有关 EMR 如何处理 EC2 Spot 中断的更多信息,请参阅相关AWS 大数据博客
Spark enhancements for elasticity and resiliency on Amazon EMR。
例如,您可能仍然希望跟踪 Spot 中断,以便将 Amazon EMR 作业失败与 Spot 中断或作业运行时长联系起来。在这种情况下,您可以设置一个 CloudWatch 事件来触发 AWS Lambda 函数以将中断事件传送到一个数据存储中。这个方法使您可以查询账户中的历史中断事件。对于较小规模测试甚至是初始测试,您可以简单使用包含电子邮件目标的 Amazon SNS 通过电子邮件获得中断通知。
标记 Amazon EMR 集群并跟踪成本
在 AWS 云中标记资源是一项基本的最佳实践。有关标记策略的更多信息,请访问此 AWS Answers 页面。在 Amazon EMR 中,标记集群之后,标签将传播到底层 EC2 实例和集群创建的 Amazon EBS 卷。这样,您能够全面了解 Amazon EMR 集群的运行成本,并且可以使用 AWS Cost Explorer 轻松查看。
小结
在本篇博客中,我们列出了通过使用 Spot 实例在 Amazon EMR 上对 Spark 应用程序进行成本优化的最佳实践。我们希望您能认为这些实践对您有所帮助,并在 Spark 应用程序中尝试使用这些最佳实践,以实现工作负载的成本优化。
关于作者
 Ran Sheinberg 是 Amazon Web Services EC2 Spot 实例领域的专业解决方案架构师。他与 AWS 客户配合工作,通过在各种不同类型的工作负载(无状态 Web 应用程序、队列工作线程、容器化工作负载、分析、HPC 等)中使用 Spot 实例来优化其计算开销。
Ran Sheinberg 是 Amazon Web Services EC2 Spot 实例领域的专业解决方案架构师。他与 AWS 客户配合工作,通过在各种不同类型的工作负载(无状态 Web 应用程序、队列工作线程、容器化工作负载、分析、HPC 等)中使用 Spot 实例来优化其计算开销。
 Daniel Haviv 是 Amazon Web Services 分析领域的专业解决方案架构师。
Daniel Haviv 是 Amazon Web Services 分析领域的专业解决方案架构师。