亚马逊AWS官方博客
自动驾驶数据湖(三):图像处理流程管道
1.前言
在亚马逊云科技2020的re:Invent大会上,发布了在云上构建自动驾驶数据湖的参考架构(点击 这里 下载源文件),结合国内的实际业务场景,我们做了一些针对性的细化和调整,修改为如下的参考架构(以MDF4/Rosbag格式数据为参考)。

因为Rosbag数据文件里面包含了例如图片,音视频,雷达,GPS等内容,需要通过解析并识别出来例如带时间戳的图片数据,pcd点云数据等,解析和拆开了对应数据以后就可以进行对应的数据分析,机器学习等环节处理。
因此我们把上图中的自动驾驶数据湖参考架构拆分成一个系列的四篇博客(此处暂时未包括左上角的IoT相关部分),方便用户和读者理解和使用对应的解决方案,这是本系列博客的第三部分:图像处理流程管道(基于Airflow调度实现)。
在本篇博客中,更加细化的图像处理流程管道的具体步骤和代码,可以参考如下图所示的参考步骤:

说明:此架构图来自参考文档2里面的步骤架构,我们未做修改。
接下来的博客内容详细代码和步骤参考上图的架构:
a)Rosbag文件上传到S3后,通过ECS识别并拆分数据存入S3;
b)接着调用Rekognition对裸数据(原始文件)进行识别和处理;
c)接着在步骤draw_bounding_boxes中对这些数据进行标注;
d)中间元数据有存放在DynamoDB方便查询和使用;
e)全流程pipeline通过托管的Airflow进行管理。
2.环境准备
我们使用的源代码位于 https://github.com/auto-bwcx-me/ (如果对亚马逊云科技的相关服务特别熟悉,也可以直接使用 官方的GitHub Repo)。
环境说明:
a)我们的操作环境为Cloud9,所有非控制台的操作都基于它完成;
b)因为是博客,为了突出自动驾驶数据湖相关的内容,我们直接给这个Cloud9配置了Administrator的权限,未遵循安全最佳实践里面的最小权限原则,大家在生产环境的时候要注意,尽量遵循最小权限分配的原则;
c)如果没有特别说明,我们的操作区域为新加坡区域;
d)如果没有特别说明,我们执行脚本的操作目录为代码目录。
注意:如果做过别的实验(如自动驾驶数据湖(一):场景检测),有留存的Cloud9,可以继续使用,各项关于Cloud9的详细配置可以有选择的确认后跳过。
2.1准备Cloud9
因为我们要在Cloud9里面编译更新Python3.9,所以部署Cloud9实例的时候可以选一个C系列的机型(如c5.2xlarge),这样编译速度会快很多,其他全部默认即可(注意部署到对应的区域,如新加坡区域即可)
创建一个Cloud9环境,取个名字,如“auto3”

确认如下红框选中的配置,其他保持默认即可

约等待1-2分钟即可打开Cloud9控制台,如果出现确实无法访问的情况(不排除是出口网络问题),可以把刚创建的Cloud9删除,重新创建一个。
2.2 安全配置
打开IAM控制台,点击左边的角色(Roles),选择创建新角色:

在添加权限的页面上可以输入“Administrator”进行搜索,然后选中结果里面的“AdministratorAccess”即可(注意:此处配置不符合安全最佳实践,生产环境慎用):

取个名字,例如叫“EC2-for-Cloud9”,然后创建即可。

打开EC2控制台(注意别选错了区域),然后选中对应Cloud9的实例,按下图所示找到修改IAM Role的位置:

选中刚才创建的IAM Role确认即可。

进入到Cloud9的Web控制台,点击右上角的配置按钮:

找到临时Credentials设置,把它关闭(默认是绿色打开的,调整为红色关闭的即可):

至此Cloud9配置完成。
2.3 拉取代码
进入Cloud9环境,执行如下脚步同步代码:
正常情况如下,如果有异常,请留意URL是否正确

2.4 更新Python3.9
在更新Python3.9之前先安装一些系统后续步骤需要用到的依赖包。打开Cloud9环境的命令行执行:
然后更新安装配置,删除临时Crendentials:
如果返回类似如下内容表示权限配置成功(中间的EC2-for-Cloud9是我们之前配置的IAM角色):
接下来使用如下方式安装和更新Python3.9:
大概需要5分钟左右的时间。
3.测试过程
注意:如果在别的环节调整过Cloud9的默认磁盘大小,可以有选择跳过对应步骤。
默认情况下,部署的Cloud9的磁盘只有10G,我们需要打包好几个Docker镜像,很容易把磁盘撑爆了,所以通过执行这脚本可以把磁盘调整到例如1000G(其实如果只是做这一个实验,100G以上就可以满足,或者曾经调整过磁盘就可以跳过了),确保在代码目录下执行(如果使用的是普通SSD硬盘,记得更换对应脚本文件):
默认情况下,我们选择和设置的区域是新加坡区域,如果不确定可以这样显式指定:
3.1配置CDK
通过如下方式配置Python3.9环境
更新CDK的相关包
创建ECR的docker 镜像存储库
然后开始CDK的初始化(要注意的是,一个Region初始化一次即可,不需要重复操作,如下的整个命令是一行,注意复制执行的时候不要折行了):
3.2部署环境
接下来部署文章开头架构图所示的测试环境(大概需要20-35分钟)
3.3测试验证
按如下的脚本准备测试数据即可
因为我们配置了Airflow的pipeline处理管道,所以只要把文件丢上去,启用Airflow管道流程即可。
3.4过程监控
打开S3的控制台,会看到多个由“rosbag-workflow-airflow”开头的存储桶:
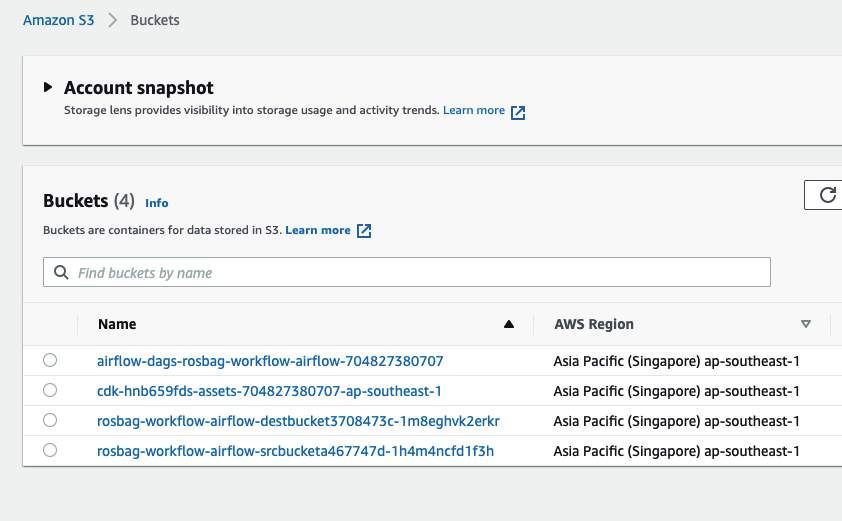
名字里面带src的桶里面是我们上传的原始数据:

名字里面带dest的桶里面是我们使用ECS处理后的目标数据(其中2022-03-09-01位rosbag的文件名称)

解析出来的数据量比较大,如下图所示:

打开Airflow的控制台,点击左侧菜单的“Environments”,会看到如下图所示已经部署好的Airflow环境:

点击上图框中的“Open Airflow UI”,即可看到如下图所示的DAG流程:

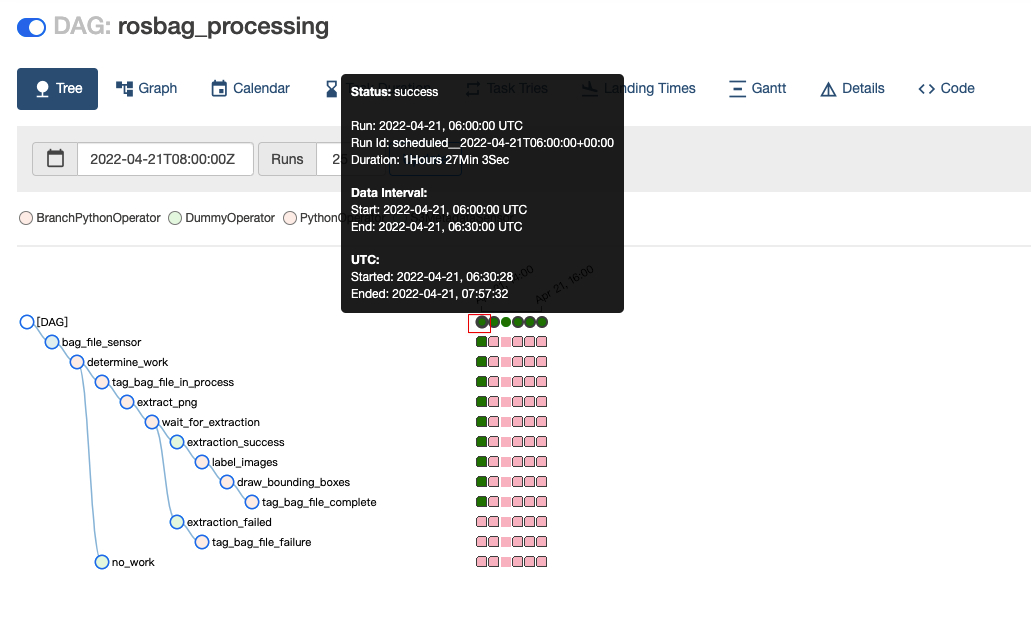
点击上图框中的“rosbag_processing”,打开如下图所示的任务执行页面:

打开上图左上角的红色数字1开关启用自动处理流程,默认会30分钟拉起一次,如果不想等待(因为我们已经上传了测试文件),可以点击右上角的红色数字2的菜单马上发起流程,也可以启用右下角红色数字3的自动刷新按钮实现页面自动刷新。
注意:整个过程跑完(基于我们的测试文件),大概需要 2小时50分钟左右(主要时间开销的步骤是draw_bounding_boxes)。我们可以耐心等待3小时再回来看其他输出的数据。
把鼠标挪到这个圆圈的位置,点击它
在打开的页面中打开管道图形

我们会发现,任务顺利结束(绿色方框一路到尾):

通过单击每一个步骤可以查看更详细的配置,日志和运行时数据等:

打开S3的控制台,按照我们的流程定义,每次上传一个rosbag文件以后,我们进入对应的原始数据桶,找到这个文件(在S3里面,这个文件是一个对象)

会发现系统启动流程后,会给这个对象打上一个标签(标签名“process.status”,标签值“in progress”),如果在流程管道执行的过程中失败了,确认代码没有问题后,可以把这个标签删除,系统会重新开始新的流程。

当成功执行完毕后,这个标签的值会变成“complete”。

找到输出的目标存储桶(名字带dest),点击进去
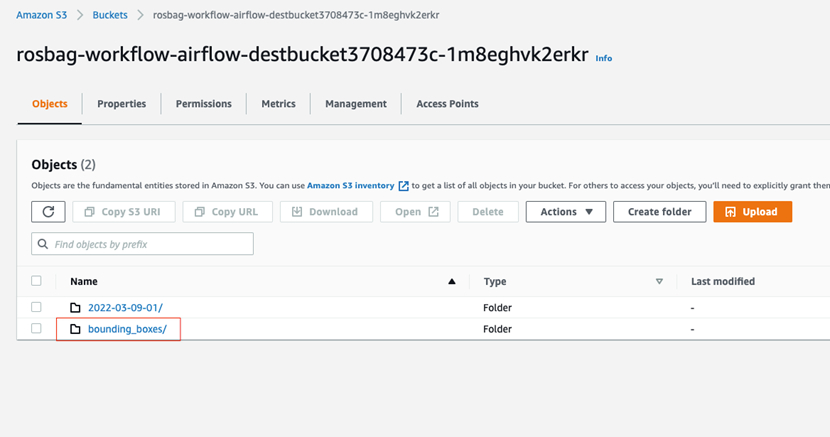
其中和上传文件同名的文件夹里面放的是经过Rekognition识别处理过后的数据(留意比原始ECS处理的数据对了同名的json文件)

其中bounding_boxes就是流程处理完毕后的标注数据

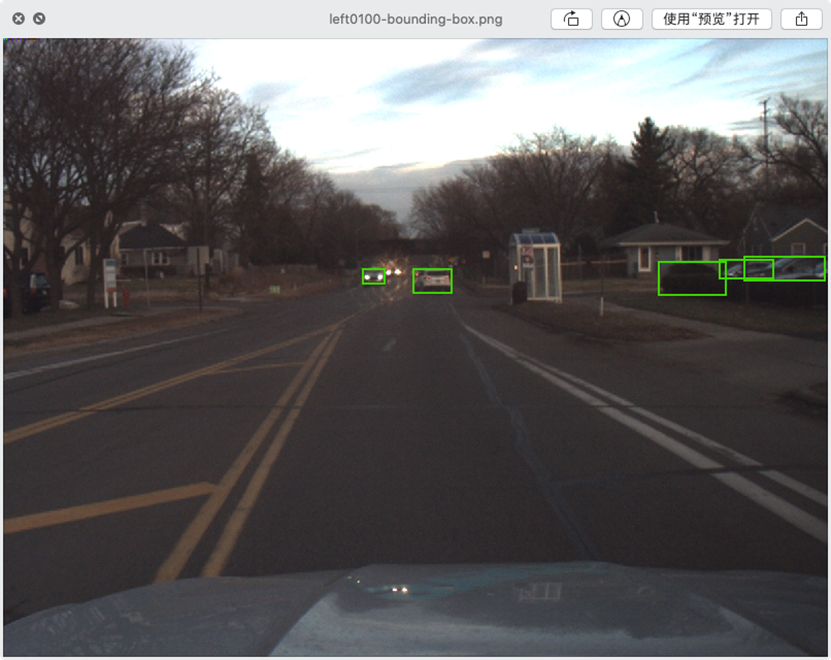
我们去两个照片做个对比,原始数据png文件(此处以left100为例)

处理后的png文件(此处以left100为例,如下图是经过标注的文件)
打开DynamoDB的控制台,可以看到我们调用Rekognition获得的元数据存储在数据库里面。

本篇博客的实验内容就到这里就结束了,更多细节,如ECS,ECR,Lambda等可以在控制台打开查看对应配置了解和客户化。
4.环境清理
虽然绝大部分分配和使用资源型的服务(如ECS,Lambda等)会自动终止资源使用,但是如果客户想手工清除环境的话,可以先清空上述测试过程中创建的S3存储桶里面的数据(以rosbag-workflow-airflow开头的S3存储桶,当然手工删除这些存储桶也是可以的),然后在代码目录下执行如下脚本即可(大概需要10分钟):
参考文档
参考1: 在亚马逊云科技上构建自动驾驶数据湖:
参考2: 自动驾驶数据湖之图像处理和模型训练流程管道:
参考3: 自动驾驶数据湖(一):场景检测:
https://thinkwithwp.com/cn/blogs/china/autonomous-driving-data-lake-scene-detection/
参考4: 自动驾驶数据湖(二):图像处理和模型训练:
参考5: 自动驾驶数据湖(四):可视化:
https://thinkwithwp.com/cn/blogs/china/autonomous-driving-data-lake-visualization-using-webviz/