亚马逊AWS官方博客
推出 Amazon Route 53 应用程序恢复控制器
我很高兴地宣布 Amazon Route 53 应用程序恢复控制器已于今天发布,它包含了多项 Amazon Route 53 的功能,可以持续监控应用程序在发生故障时恢复的能力,并且可以跨多个 AWS 可用区、AWS 区域和本地环境控制应用程序的恢复,以帮助客户构建必须提供极高可用性的应用程序。
AWS 始终将数据和工作负载的安全性和可用性放在首位。AWS 全球基础设施从建立开始,就能让客户构建能够抵御不同类型故障的应用程序架构。在业务或应用程序需要高可用性时,客户通常会使用 AWS 全球基础设施,跨一个 AWS 区域内的 AWS 可用区部署冗余的应用程序副本。然后通过网络负载均衡器或 Application Load Balancer 将流量路由到相应的副本。这种架构能够满足绝大多数工作负载的要求。
但某些行业和工作负载可能会有更高的高可用性要求:需要达到或超过 99.99% 的可用率以及秒级或分钟级的恢复时间目标(RTO)。可以想象一下,实时支付处理或交易引擎一旦发生中断会对整个经济产生怎样的影响。为了满足这些要求,客户通常会跨不同的 AWS 可用区、AWS 区域和本地环境部署多个副本。然后使用 Amazon Route 53 可靠地将最终用户路由到相应的副本。
Amazon Route 53 应用程序恢复控制器可帮助构建这些需要极高可用性和极低 RTO 的应用程序。这通常是采用双活架构的应用程序,当然其他类型的冗余架构也可利用 Amazon Route 53 应用程序恢复控制器的强大功能。它由两个部分组成:就绪检查和路由控制。
就绪检查会持续监控 AWS 资源配置、容量和网络路由策略,并且可以监控任何将会影响恢复操作执行能力的更改。这些检查可确保恢复环境的正确扩展和配置,能够在需要时接管。检查项目包括 Auto Scaling 组、Amazon Elastic Compute Cloud(Amazon EC2)实例、Amazon Elastic Block Store(EBS)卷、负载均衡器、Amazon Relational Database Service(RDS)实例、Amazon DynamoDB 表的配置以及多项其他配置。例如,就绪检查会验证 AWS 服务限制,以确保发生故障转移时能够在 AWS 区域部署足够的容量。此外还会验证应用程序副本的容量和扩展特性是否跨 AWS 区域一致。
路由控制有利于在发生故障时跨应用程序副本调整流量,以确保应用程序始终可用。路由控制与 Amazon Route 53 运行状况检查结合,通过 DNS 解析将流量重定向到相应的应用程序副本。路由控制在以下三个方面改进了传统基于 Amazon Route 53 运行状况检查的自动化故障转移:
- 首先,路由控制使您能够根据应用程序指标或部分故障(例如错误率提高 5% 或延迟增加一毫秒)对整个应用程序堆栈实施故障转移。
- 其次,路由控制让您能够安全简单地实施手动覆盖。您可以利用路由控制来转移流量以进行维护,或者在监控器未检测到问题时从故障中恢复。
- 第三,路由控制可以使用称为安全规则的功能,以防止与完全自动运行状况检查有关的常见副作用,例如防止故障转移到尚未准备就绪的副本,或者 flapping(漂移)问题。
为帮助理解 Route 53 应用程序恢复控制器的工作原理,我将演示我在配置自己的高可用性应用程序时使用的过程。
工作原理
为方便演示,我构建了一个应用程序,包含一个负载均衡器、一个有两个 EC2 实例的 Auto Scaling 组以及一个全局 DynamoDB 表。我编写了一个 CDK 脚本,以在以下两个 AWS 区域部署该应用程序:美国东部(弗吉尼亚北部)和美国西部(俄勒冈)。该全局 DynamoDB 表可确保在这两个 AWS 区域之间复制数据。我在前面已经解释,这是一个主备架构。
该应用程序是一款多玩家九宫格游戏,通常需要具备 99.99% 或以上的可用率 :-)。一条 DNS 记录(tictactoe.seb.go-aws.com)会指向位于美国东部(弗吉尼亚北部)区域的负载均衡器。下图显示了此应用程序的架构。

准备我的应用程序
要为我的Route 53 应用程序恢复控制器Route 53 应用程序恢复控制器,我首先部署了应用程序堆栈的独立副本,以便我可以跨堆栈故障转移流量。这些副本跨 AWS 高可用性边界部署,例如可用区或 AWS 区域。我选择跨多个 AWS 区域部署我的应用程序副本。
然后,我在这些独立副本之间配置了数据复制。我使用 DynamoDB 全局表来帮助复制数据。
最后,我对每个独立堆栈进行了配置以公开一个 DNS 名称。此 DNS 名称是我的应用程序的入口点,例如区域负载均衡器 DNS 名称。
术语
在配置就绪检查之前,我想先介绍一些基本术语。
单元是一个独立的容器,其中包含我的应用程序的独立故障转移单位。它对我的应用程序独立运行所需的所有 AWS 资源进行分组。为方便演示,我使用了两个单元:在部署我的应用程序的每个 AWS 区域一个。单元通常与 AWS 高可用性边界(例如 AWS 区域或可用区)一致,但也可以更小。一个可用区中可以有多个单元。这种方法可以有效地降低爆炸半径,尤其是在您遵循一次一个单元的更改管理实践时。

恢复组是一组单元的集合,代表我要检查故障转移就绪情况的应用程序或应用程序组。恢复组通常包含两个或以上的单元,这些单元在功能上完全相同。

资源集是一组可以跨多个单元的 AWS 资源。在于本演示中,我有三个资源集:一是位于 us-east-1 和 us-west-2 区域的两个负载均衡器,二是位于这两个区域的两个 Auto Scaling 组,最后一个是该全局 DynamoDB 表。
就绪检查可验证 AWS 资源集接受故障转移的就绪情况。在此例中,我要审计负载均衡器、Auto Scaling 组和 DynamoDB 表的就绪情况。我为 Auto Scaling 组创建了就绪检查。该服务会持续监控组中的实例类型和计数,以确保每个组都均匀扩展。我为负载均衡器和全局 DynamoDB 表重复这一过程。

为了帮助确定应用程序是否已准备好恢复,Route 53 应用程序恢复控制器会持续跨应用程序单元(可用区或区域)审计容量、AWS 资源限制和 AWS 节流限制。 当 Route 53 应用程序恢复控制器检测到不符合限制的情况时,它会跨单元为该资源发出 AWS 服务配额请求。如果 Route 53 应用程序恢复控制器检测到资源容量不匹配的情况,我可以采取措施跨单元调整容量。例如,我可以为我的 Auto Scaling 组触发向上扩展。
创建就绪检查
为了创建就绪检查,我打开 AWS 管理控制台,然后导航到 Route 53 下的 Application Recovery Controller(应用程序恢复控制器)部分。

要为我的应用程序创建恢复组,我导航到 Getting Started(入门)部分,然后选择 Create recovery group(创建恢复组)。

我输入一个名称(例如 AWSNewsBlogDemo),然后选择 Next(下一步)。
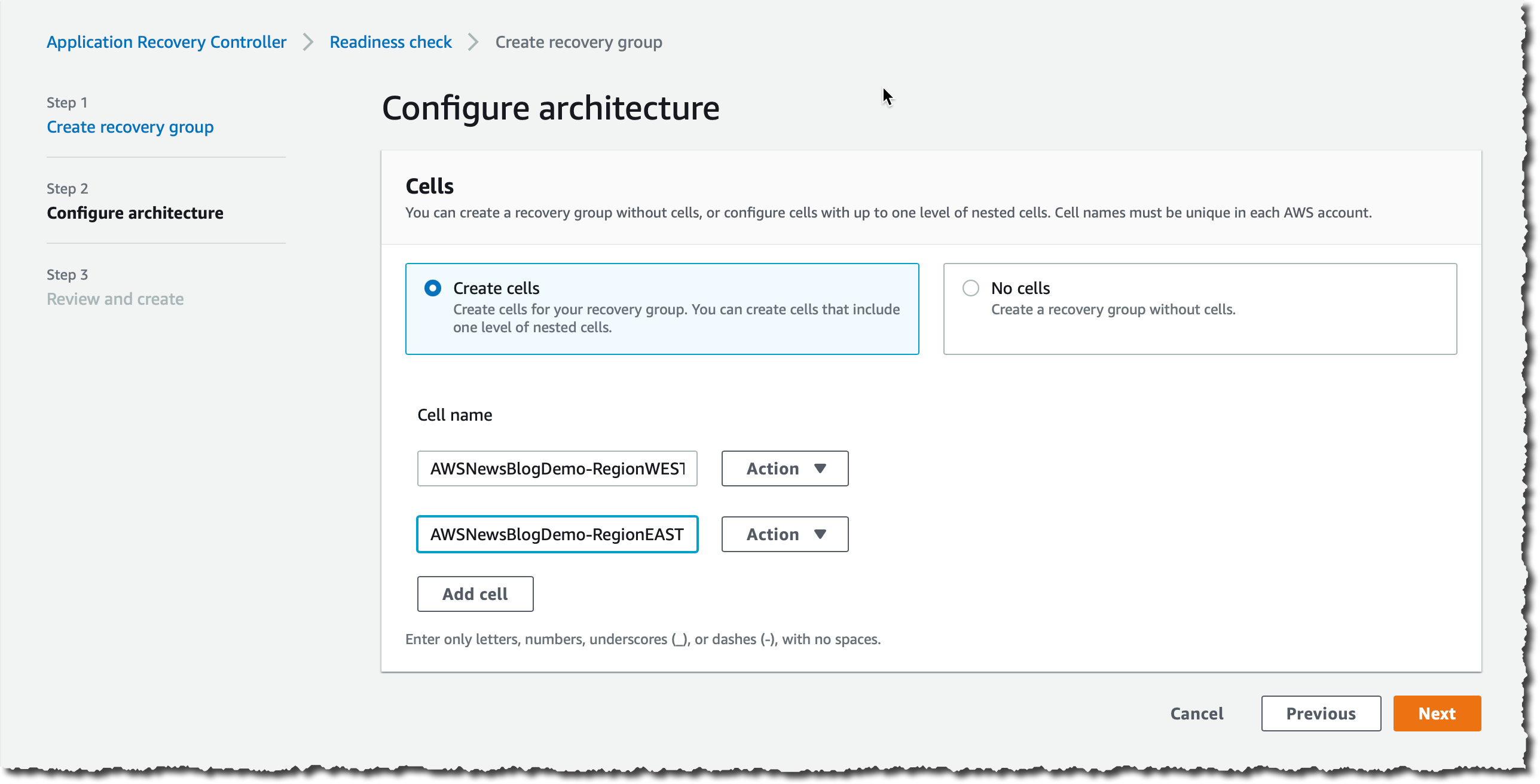
在 Configure Architecture(配置架构)中,我选择 Add Cell(添加单元),然后输入一个单元名称(AWSNewsBlogDemo-RegionWEST),然后再次选择 Add Cell(添加单元)以添加第二个单元。我为为第二个单元输入 AWSNewsBlogDemo-RegionEAST。我选择 Next(下一步)以查看我的输入,然后选择 Create recovery group(创建恢复组)。
现在我需要将我的负载均衡器、Auto Scaling 组和 DynamoDB 表等资源与我的恢复组关联起来。
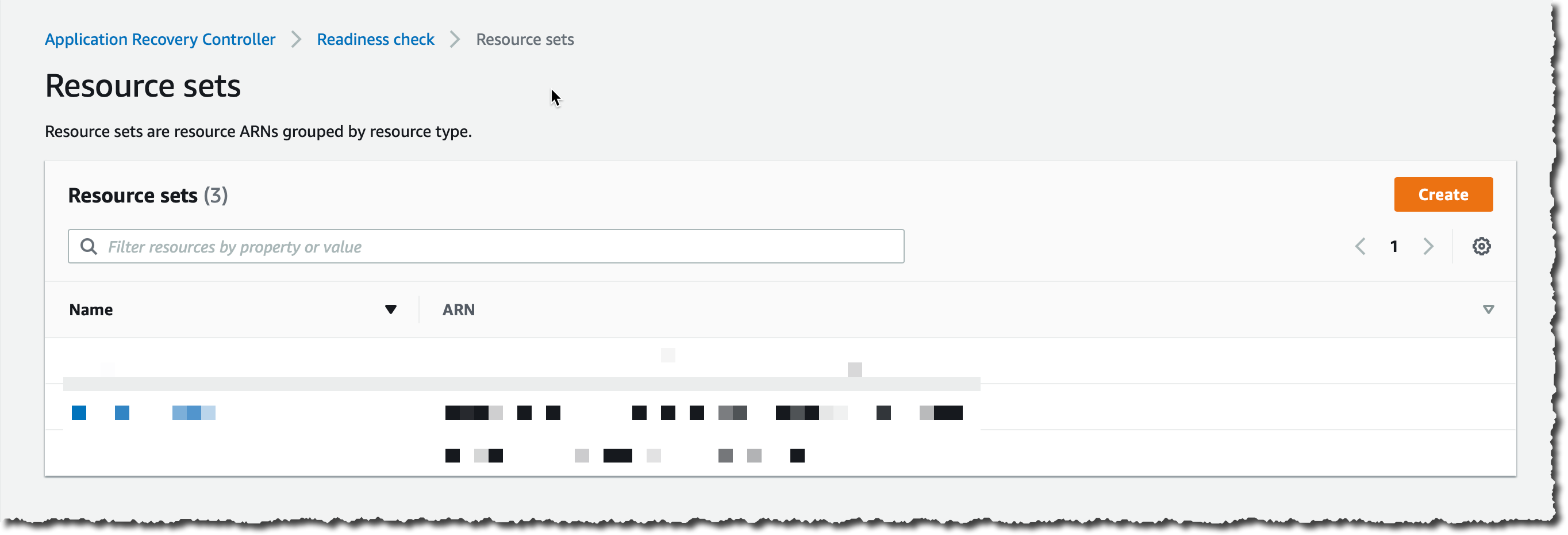
在左侧导航窗格中,我选择 Resource Set(资源集),然后选择 Create(创建)。

我为第一个资源集输入一个名称(例如,load_balancers)。对于 Resource type(资源类型),我选择 Network Load Balancer or Application Load Balancer(网络负载均衡器或 Application Load Balancer),然后选择 Add(添加)以添加负载均衡器 ARN。
我再次选择 Add(添加)以输入第二个负载均衡器 ARN,然后选择 Create resource set(创建资源集)。
我重复此过程,为这两个 Auto Scaling 组创建一个资源集,然后为全局 DynamoDB 表创建第三个资源集(一个 ARN)。我现在有三个资源集:
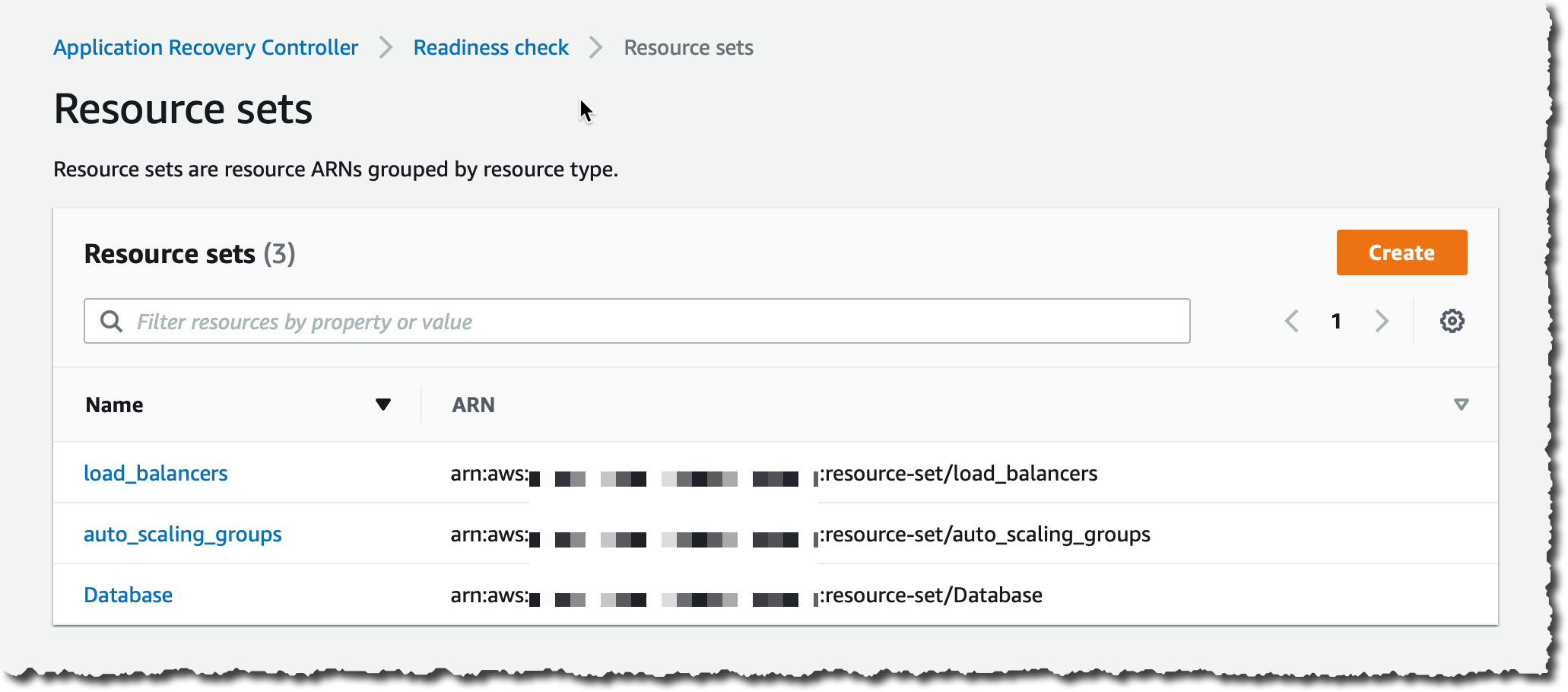
最后一步是创建就绪检查。这会将资源与资源组中的单元关联起来。
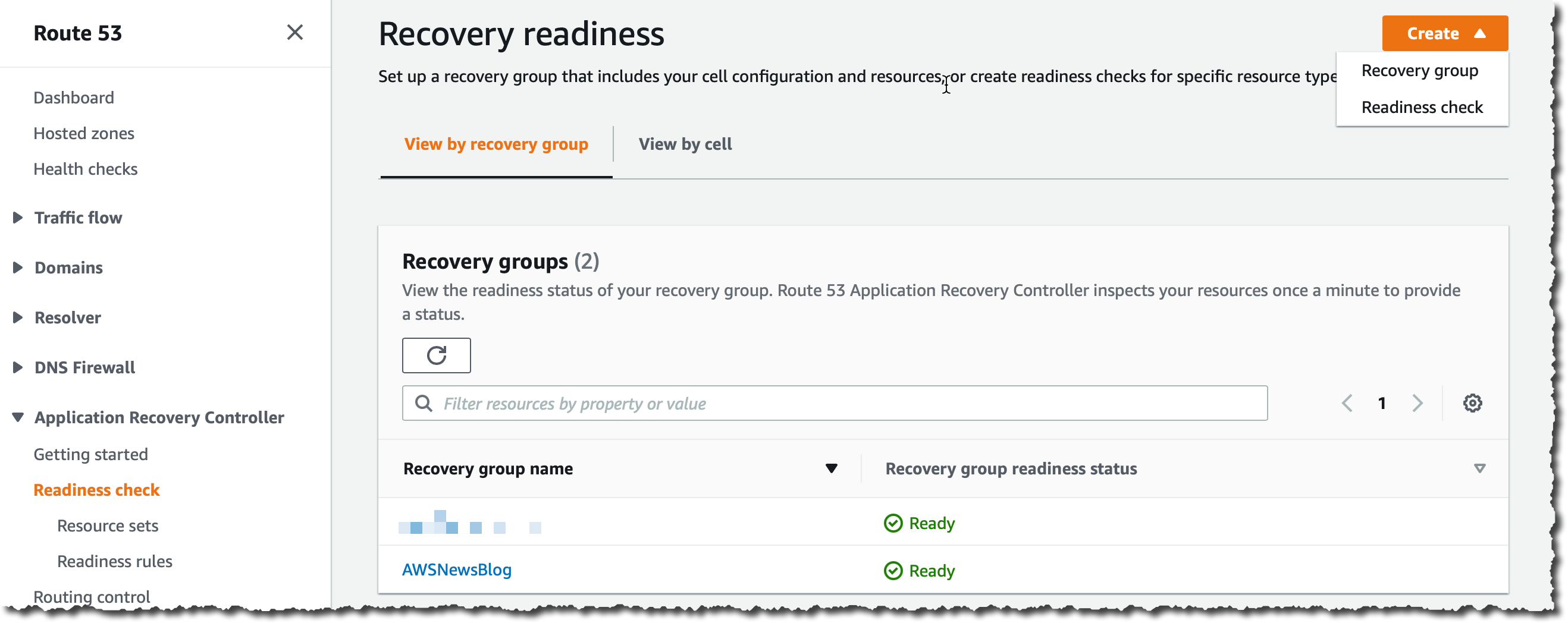
在 Readiness check(就绪检查)中,我选择屏幕右上角的 Create(创建),然后选择 Readiness check(就绪检查)。
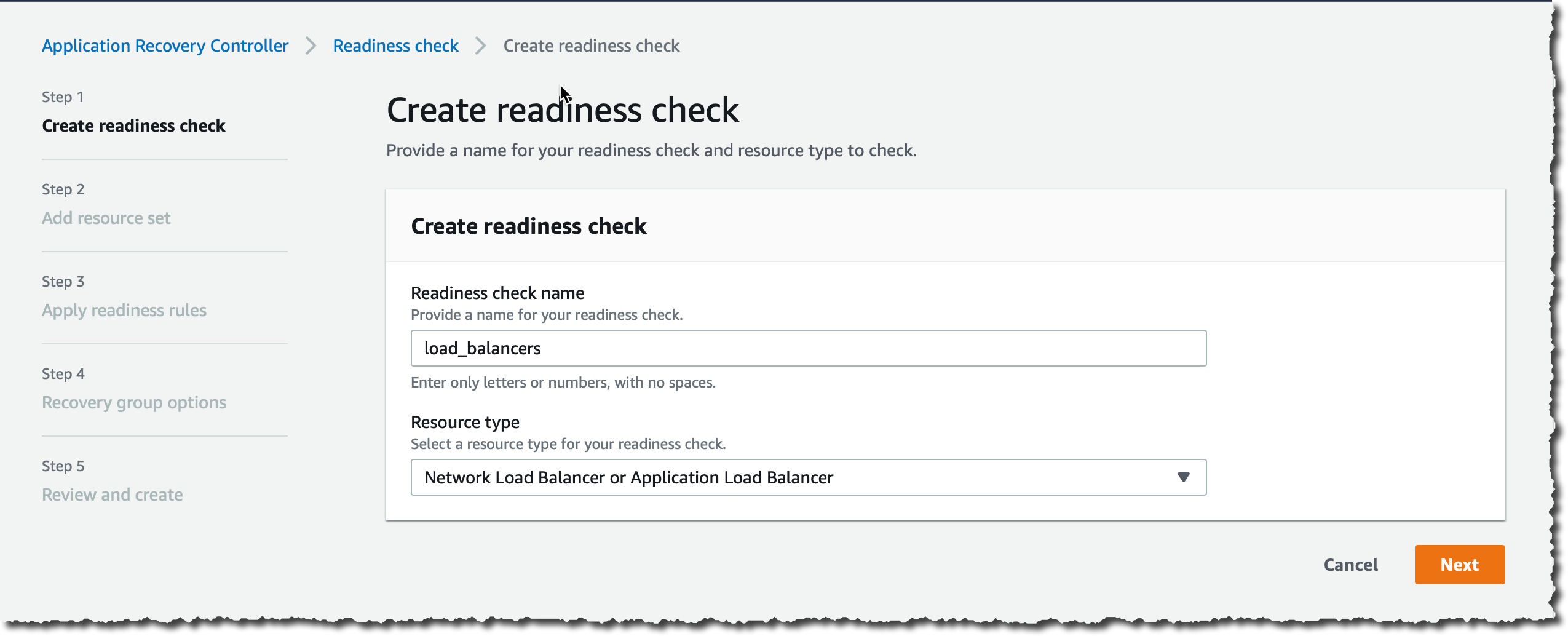
第 1 步(Create readiness check(创建就绪检查)),我输入一个名称(例如,load_balancers)。对于 Resource type(资源类型),我选择 Network Load Balancer or Application Load Balancer(网络负载均衡器或 Application Load Balancer),然后选择 Next(下一步)。
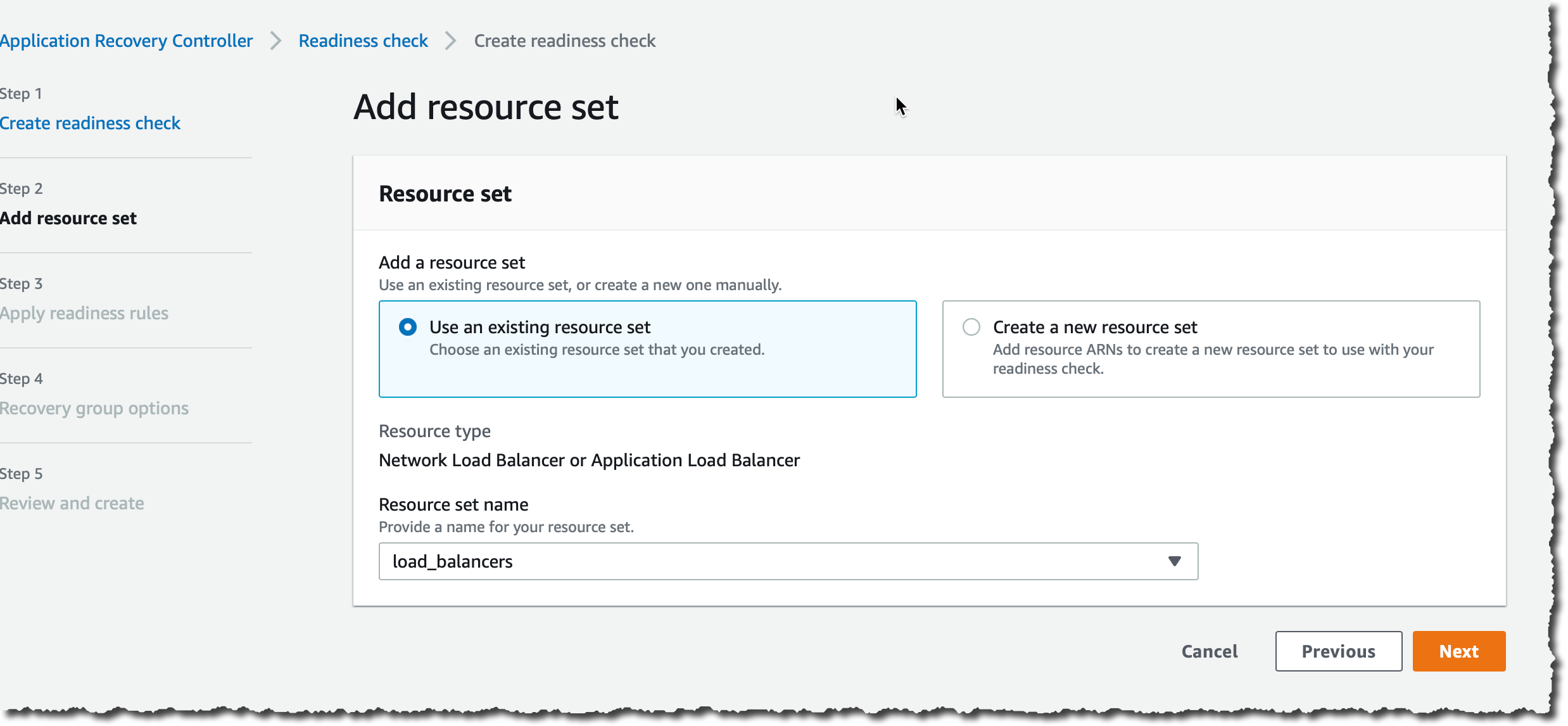
第 2 步(Add resource set(添加资源集)),我保留默认选择 Use an existing resource set(使用现有资源集),对于 Resource set name(资源集名称),我选择 load_balancers,然后选择 Next(下一步)。
第 3 步(Apply readiness rules(应用就绪规则)),我检查规则,然后选择 Next(下一步)。

第 4 步(Recovery Group Options(恢复组选项)),我保留默认选择 Associate with an existing recovery group(关联到现有恢复组)。对于 Recovery group name(恢复组名称),我选择 AWSNewsBlog。然后,我将这两个单元(EAST 和 WEST)与这两个负载均衡器 ARN 关联起来。务必要确保关联到每个单元的负载均衡器正确。ARN 中包含区域名称。
第 5 步(Review and create(检查并创建)),我检查我的选择,然后选择 Create readiness check(创建就绪检查)。

我为 Auto Scaling 组和 DynamoDB 全局表重复这一过程。
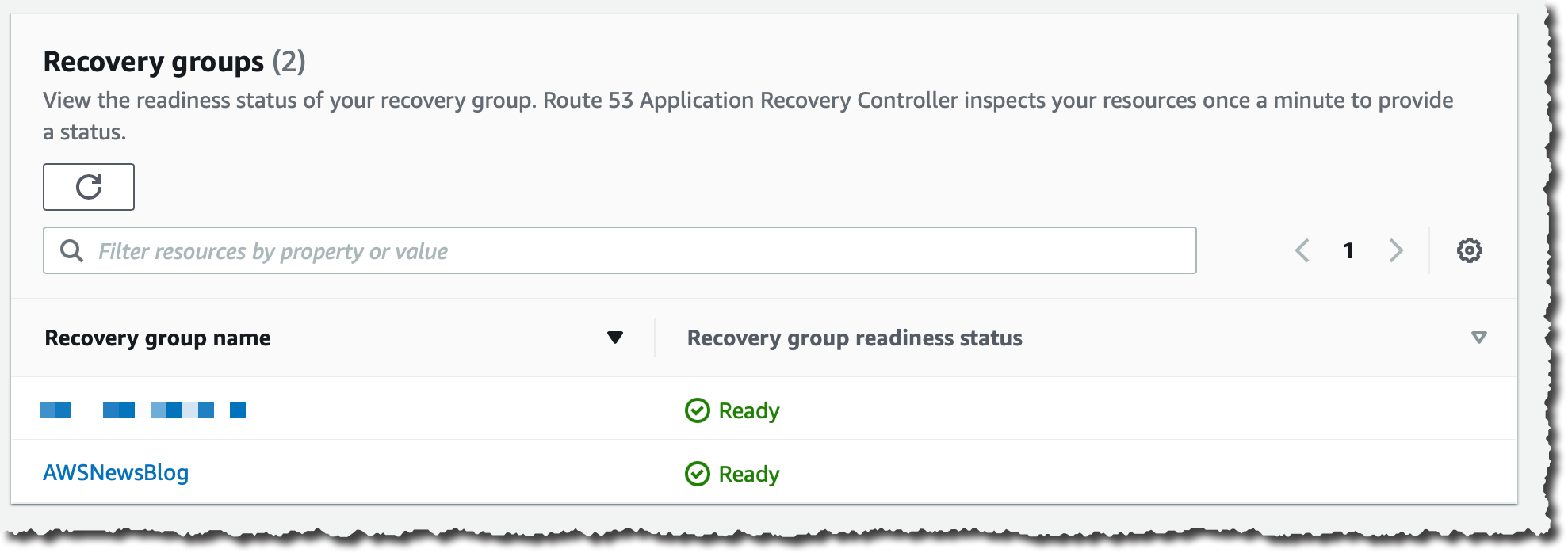
当组中的所有就绪检查均为绿色时,表示该组的状态为 Ready(就绪)。
然后我可以配置和测试路由控制。
术语
在配置路由控制之前,我想先介绍一些基本术语。
集群是一组五个冗余的区域端点,您可以对其执行 API 调用以更新或获取路由控制的状态。您可以在一个集群上托管多个控制面板和路由控制。
路由控制是在集群上托管的一个简单开关,用于控制进出单元的客户端流量的路由。创建路由控制时,您可以在 Route 53 中添加运行状况检查,以便在您更新 Route 53 应用程序恢复控制器中的路由控制时,可以重新路由流量。如果您希望将运行状况检查与路由控制结合使用来路由流量,则运行状况检查必须与每个应用程序副本前面的 DNS 故障转移记录关联。
控制面板将一组相关的路由控制组合起来。
配置路由控制
我可以使用 Route 53 控制台或 API 操作在每个 AWS 区域为我的应用程序创建路由控制。创建路由控制后,我为每个路由控制创建了一个 Amazon Route 53 应用程序恢复控制器运行状况检查,然后在每个区域将每个运行状况检查关联到我负载均衡器的 DNS 故障转移记录。然后,为了在区域之间实现流量的故障转移,我将一个路由控制的路由控制状态更改为 Off(关闭),另一个路由控制的路由控制状态更改为 On(打开)。
第一步是创建集群。集群的收费为 2.5 美元/小时。当您创建集群来体验 Route 53 应用程序恢复控制器时,请务必在实验结束后删除集群。

在左侧导航窗格中,我导航到集群面板,然后选择 Create(创建)。

我输入集群的名称,然后选择 Create cluster(创建集群)。
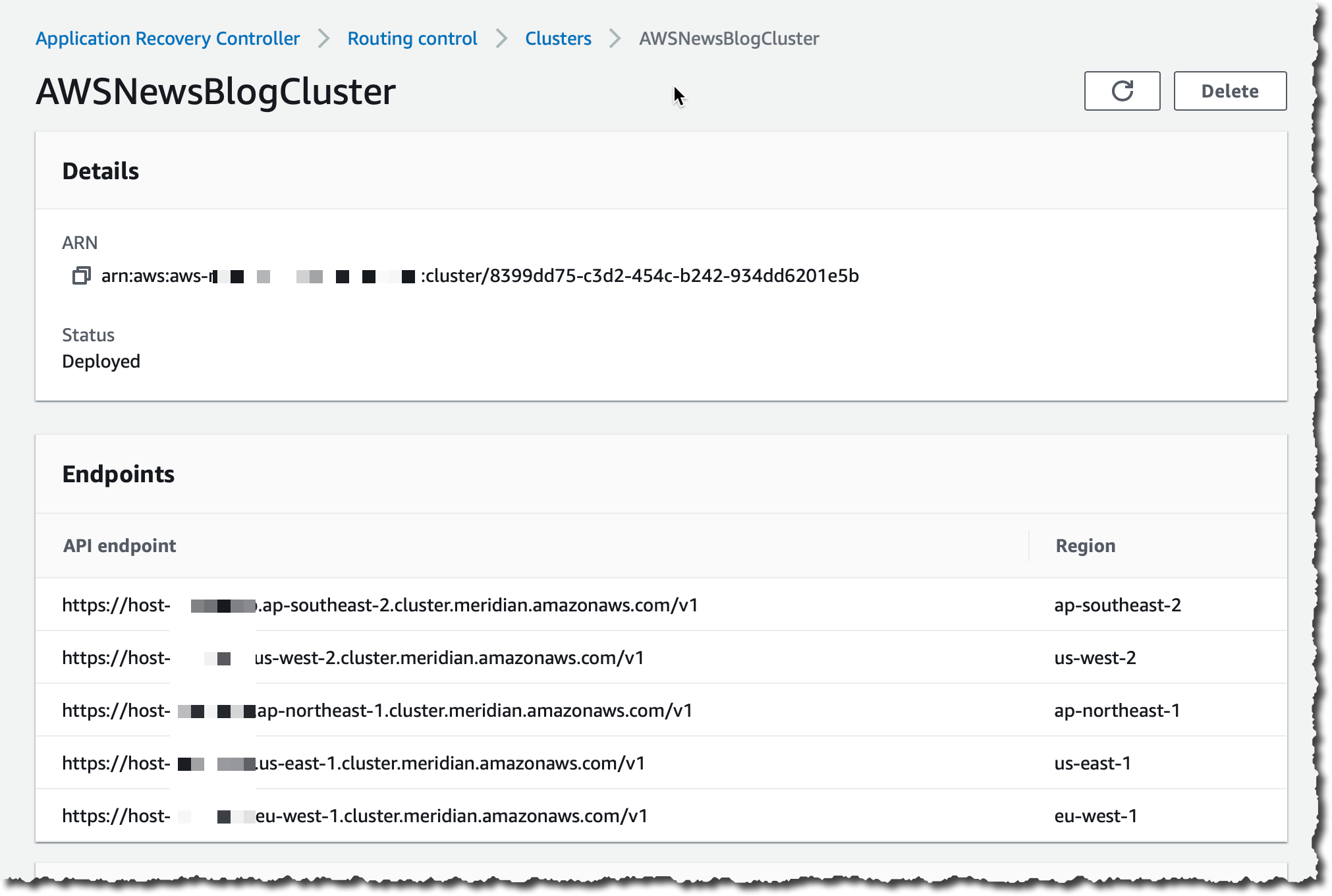
集群处于 Pending(待处理)状态几分钟。一段时间之后,其状态变为 Deployed(已部署)。
部署完成后,我选中该集群名称,然后可发现五个冗余 API 端点。在构建恢复工具以检索或设置路由控制状态时,必须指定其中一个端点。您可以使用任何集群端点,但对于复杂或自动化场景,我们建议您的系统准备好对每个可用的端点进行重试,为每个重试请求使用不同的端点。
流量路由通过在控制面板中分组的路由控制来进行管理。您可以创建控制面板,也可使用系统为您创建的默认控制面板。
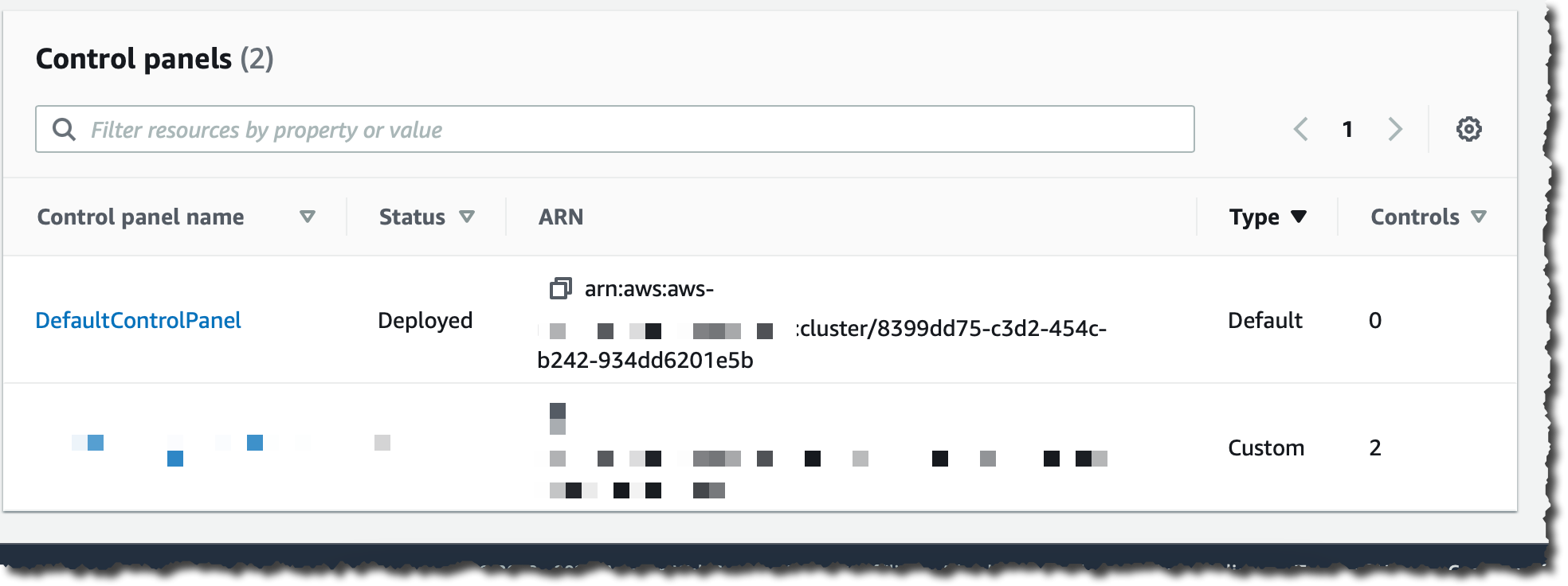
我选择 DefaultControlPanel(默认控制面板)。
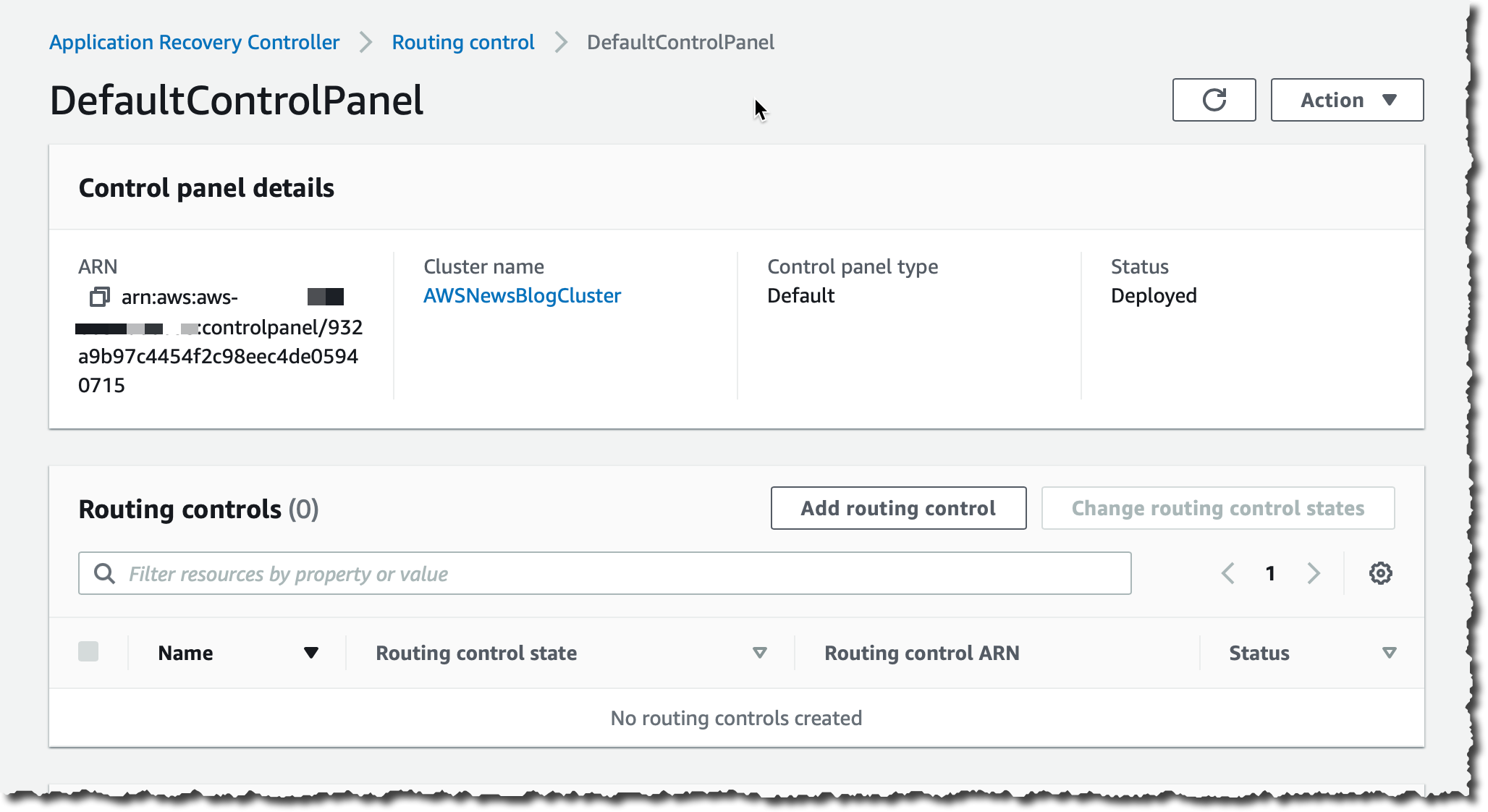
我选择 Add routing control(添加路由控制)。

我输入路由控制的名称(FailToWEST),然后选择 Create routing control(创建路由控制)。我为第二个路由控制(FailToEAST)重复这一操作。
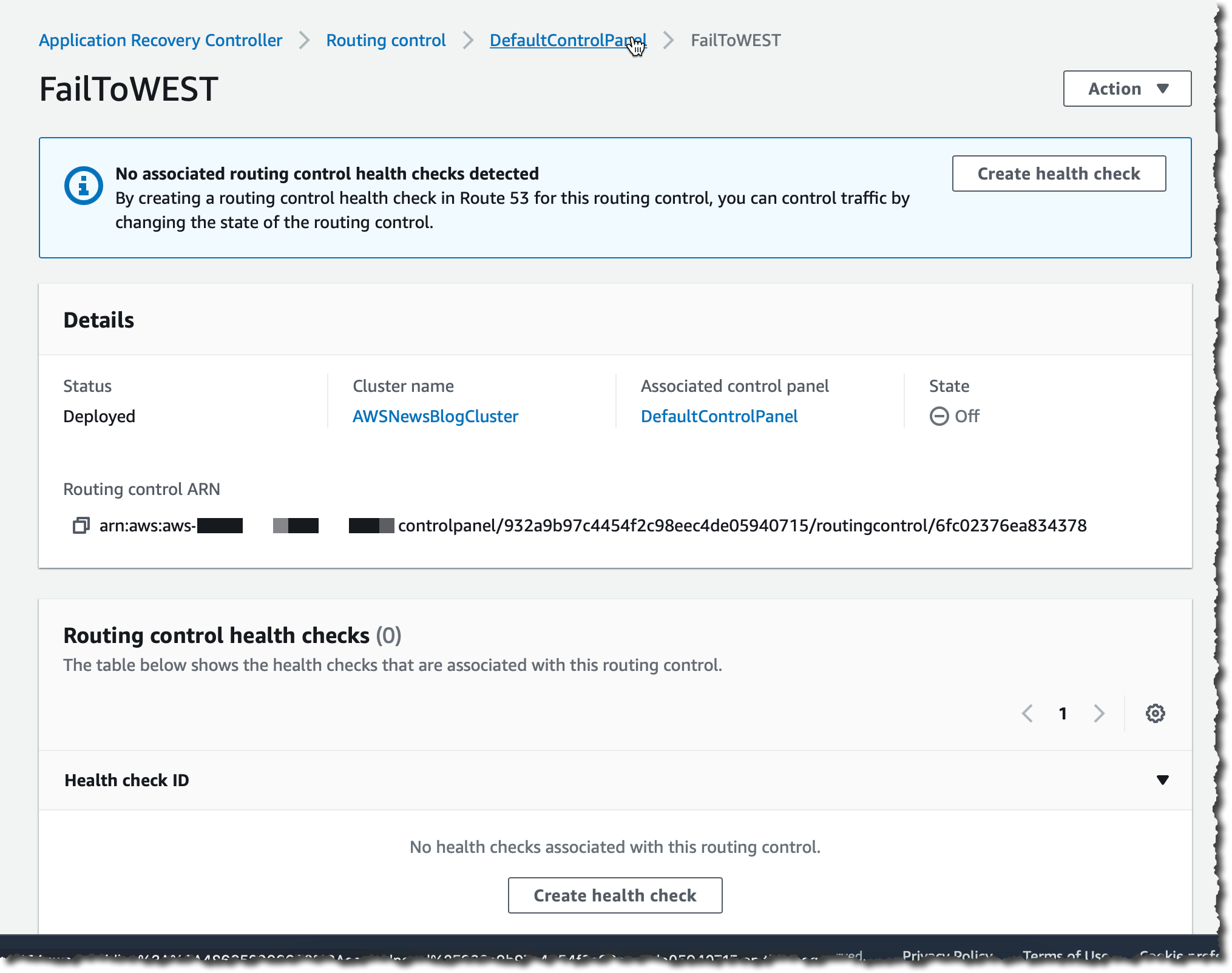
创建路由控制之后,我从列表中选中它。在详细信息页面上,我选择 Create health chec(创建运行状况检查)以在 Route 53 中创建运行状况检查。

我输入运行状况检查的名称,然后选择 Create(创建)。我导航到 Route 53 控制台,以验证运行状况检查是否正确创建。
我为每个路由控制创建了一个运行状况检查。
您可能已经注意到,在控制面板中可以添加安全规则。 如果您同时使用多个路由控制,则可能需要在启用和禁用这些路由控制时实施一些保障机制。这可以帮助避免在副本未准备就绪时启动故障转移,或者避免意外后果,例如同时关闭这两个路由控制并停止所有流量。要创建这些保障机制,您需要创建安全规则。 有关安全规则的更多信息,包括使用示例,请参阅 Route 53 应用程序恢复控制器开发人员指南。
前面我们创建好了路由控制和 DNS 运行状况检查,最后一步是将流量路由到我的应用程序。
调整我的 DNS 设置
为了将流量路由到我的应用程序,我将 DNS 别名分配给单元中的应用程序顶级入口点。在此例中,我使用 Route 53 控制台创建了两条故障转移类型的别名 A 记录,并将每个运行状况检查与每条 DNS 记录关联起来。这两条记录具有相同的记录名称。一条是主记录,另一条是备用记录。有关 Amazon Route 53 运行状况检查的更多信息,请参阅 Amazon Route 53 53 开发人员指南。
 |
 |
在应用程序恢复路由控制页面上,我启用了这两个路由控制中的一个。

完成这一操作后,所有指向 tictactoe.seb.go-aws.com 的流量都将转向在 us-east-1 上部署的基础设施。
测试我的设置
为了测试设置,我首先在一个终端中使用 dig 命令。它显示了指向在 us-east-1 上部署的负载均衡器的 DNS 别名记录。

我还用 Web 浏览器测试了应用程序。我注意到 tictactoe.seb.go-aws.com 这个名称指向了 us-east-1。
然后我使用 update-routing-control-state API 操作、CLI 或控制台,关闭了指向 us-east-1 区域的路由控制,然后开启了指向 us-west-2 区域的路由控制。当我使用 CLI 时,我使用集群提供的端点。
aws route53-recovery-cluster update-routing-control-state \
--routing-control-arn arn:aws:route53-recovery-control::012345678:controlpanel/xxx/routingcontrol/abcd \
--routing-control-state On \
--region us-west-2 \
--endpoint-url https://host-xxx.us-west-2.cluster.routing-control.amazonaws.com/v1在控制台中,我导航到控制面板,选择我要更改的路由控制,然后单击 Change routing control states(更改路由控制状态)。

不到一分钟后,DNS 地址就会更新。我的应用程序流量现在被路由到 us-west-2 区域。

就绪检查和路由控制实现了应用程序流量的受控故障转移,将流量从我的活动副本重定向到位于另一个 AWS 区域的备用副本。正如我演示的那样,我可以手动更改流量路由,也可以使用 Amazon CloudWatch 告警,以根据应用程序的技术和业务指标来自动调整流量路由。
定价
此新功能按使用量付费,无需预付。您需要按就绪检查数以及集群小时数付费。就绪检查的收费标准为每小时 0.045 美元。集群的收费标准为 2.5 美元/小时。对于本文中使用的演示示例,我们有三个就绪检查和一个集群。此设置的每小时价格(不包括应用程序本身)为 3 x 0.045 美元 + 1 x 2.5 美元 = 2.635 美元/小时。有关定价的更多详细信息,包括示例,请参阅 Route 53 定价页面。
此新功能是一项全球性服务,可用于监控和控制在任何公有商业 AWS 区域中运行的应用程序的应用程序恢复。立即试用,并向我们提供反馈。与往常一样,您可以通过您通常联系的 AWS Support 联系人发送反馈,也可通过在 有关 Route 53 应用程序恢复控制器的 AWS 论坛上发帖反馈。