亚马逊AWS官方博客
Amazon Personalize 现已正式发布
今天,我们很高兴地宣布,所有 AWS 客户都可以使用 Amazon Personalize。Amazon Personalize 的预览版在 AWS re:Invent 2018 中宣布推出,它是一项完全托管的服务,允许您为应用程序创建私有、自定义的个性化建议,几乎不需要机器学习经验。
无论是在应用程序内部及时提供视频推荐,还是适时提供个性化通知电子邮件,基于您的数据的个性化体验都可以为客户提供更相关的体验,而这通常会带来更高的业务回报。
开发高效推荐系统的任务非常具有挑战性:构建、优化和部署实时个性化需要分析、应用机器学习、软件工程和系统操作方面的专业知识。很少有组织拥有克服这些挑战的知识、技能和经验,随着新产品和促销活动的引入或客户行为的变化,基于规则的简单系统变得脆弱且维护成本高昂。
20 多年来,Amazon.com 完善了机器学习模型,提供从产品发现到结账的个性化购买体验。借助 Amazon Personalize,我们为开发人员提供相同功能来构建自定义模型,而无需处理通常伴随此类解决方案的基础架构和机器学习的复杂性。
借助 Amazon Personalize,您可以在活动数据(页面查看次数、注册、购买等)中提供唯一信号以及可选的客户特征信息(年龄、位置等)。然后,您可以提供要推荐项目的清单,例如文章、产品、视频或音乐。然后,完全在幕后,Amazon Personalize 将处理和检查数据,识别有意义的内容,选择正确的算法,培训和优化为您的数据定制的个性化模型,并通过 API 访问。Amazon Personalize 分析的所有数据均保持私密和安全,仅用于您的自定义建议。由此产生的模型是您的专属模型。
通过单个 API 调用,您可以为用户提供建议并个性化客户体验,从而提高营销活动的参与度、转化率和性能。例如,Domino’s Pizza 正在使用Amazon Personalize 通过其数字资产提供自定义通信,例如促销优惠。Sony Interactive Entertainment 将Personalize 与 Amazon SageMaker 配合使用,以自动化和加快其机器学习开发,并大规模推动更有效的个性化。
Personalize 就像拥有自己的Amazon.com 机器学习个性化团队一样,每天 24 小时随时待命。
隆重推出 Amazon Personalize
Amazon Personalize 可根据您在 Amazon S3 中存储的历史数据或您的应用程序实时发送的流数据(或两者)来提供建议。
这为客户提供了构建推荐解决方案的灵活性。例如,您可以根据历史数据构建初始推荐程序,并在您累积足够的直播事件时定期重新训练。或者,如果您没有可以开始的历史数据,您可以暂时提取事件,然后构建您的推荐程序。
我在之前的博文中介绍了历史数据,这次将重点关注直播事件。
简要流程如下所示:
- 创建数据集组以存储您的应用程序发送的事件。
- 创建交互数据集并定义其架构(此时不需要任何数据)。
- 创建事件跟踪器以将事件发送到 Amazon Personalize。
- 开始向 Amazon Personalize 发送事件。
- 选择推荐配方,或者借助 AutoML,让 Amazon Personalize 为您选择一个配方。
- 创建解决方案,即在数据集上训练配方。
- 创建一个活动并开始推荐项目。
创建数据集组
假设我们想要捕获电影推荐的点击流。我们使用首次设置向导,创建一个数据集组来存储这些事件。在这里,我们假设开始时没有任何历史数据:所有事件都是由点击流生成的,并使用事件提取开发工具包进行提取。
创建数据集组只需要一个名称。
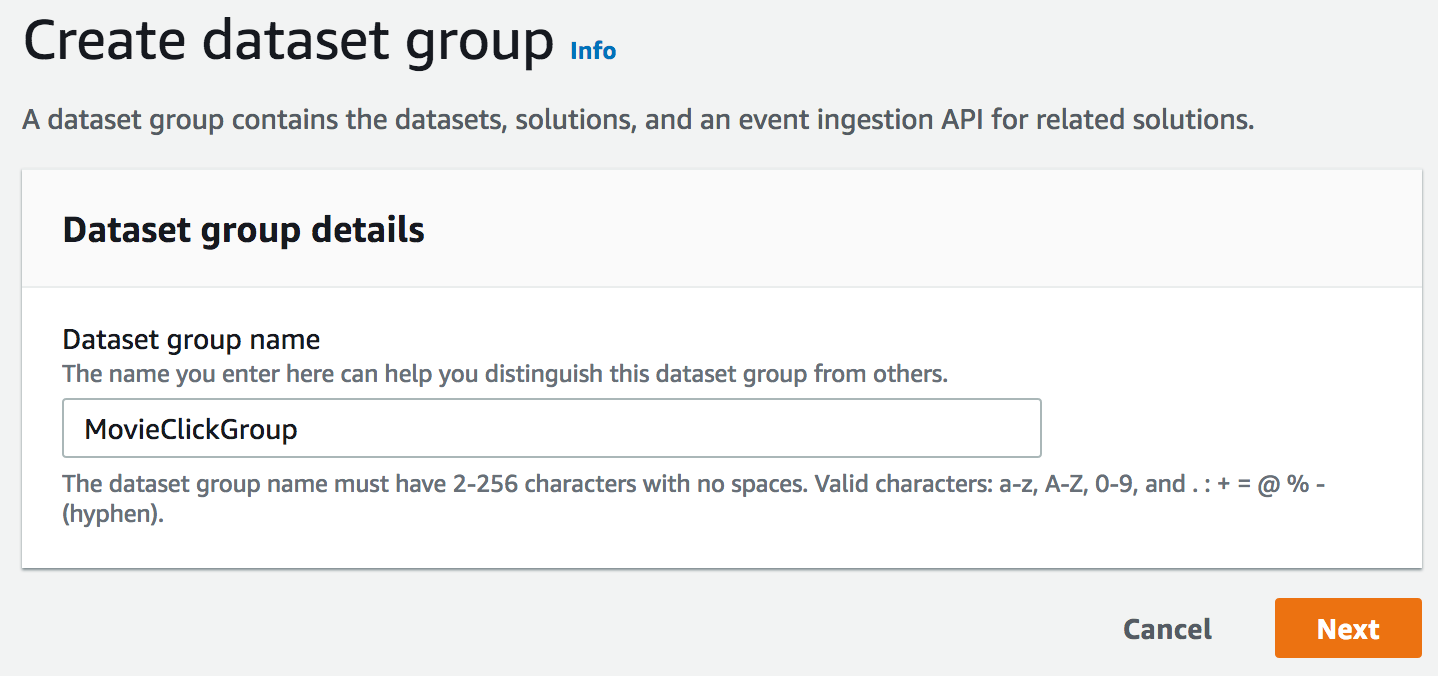
然后,我们必须创建交互数据集,该数据集显示用户如何与项目交互(喜欢、点击等)。当然,我们需要定义描述数据的架构:在这里,我们只需使用 Amazon Personalize 提供的默认模式。
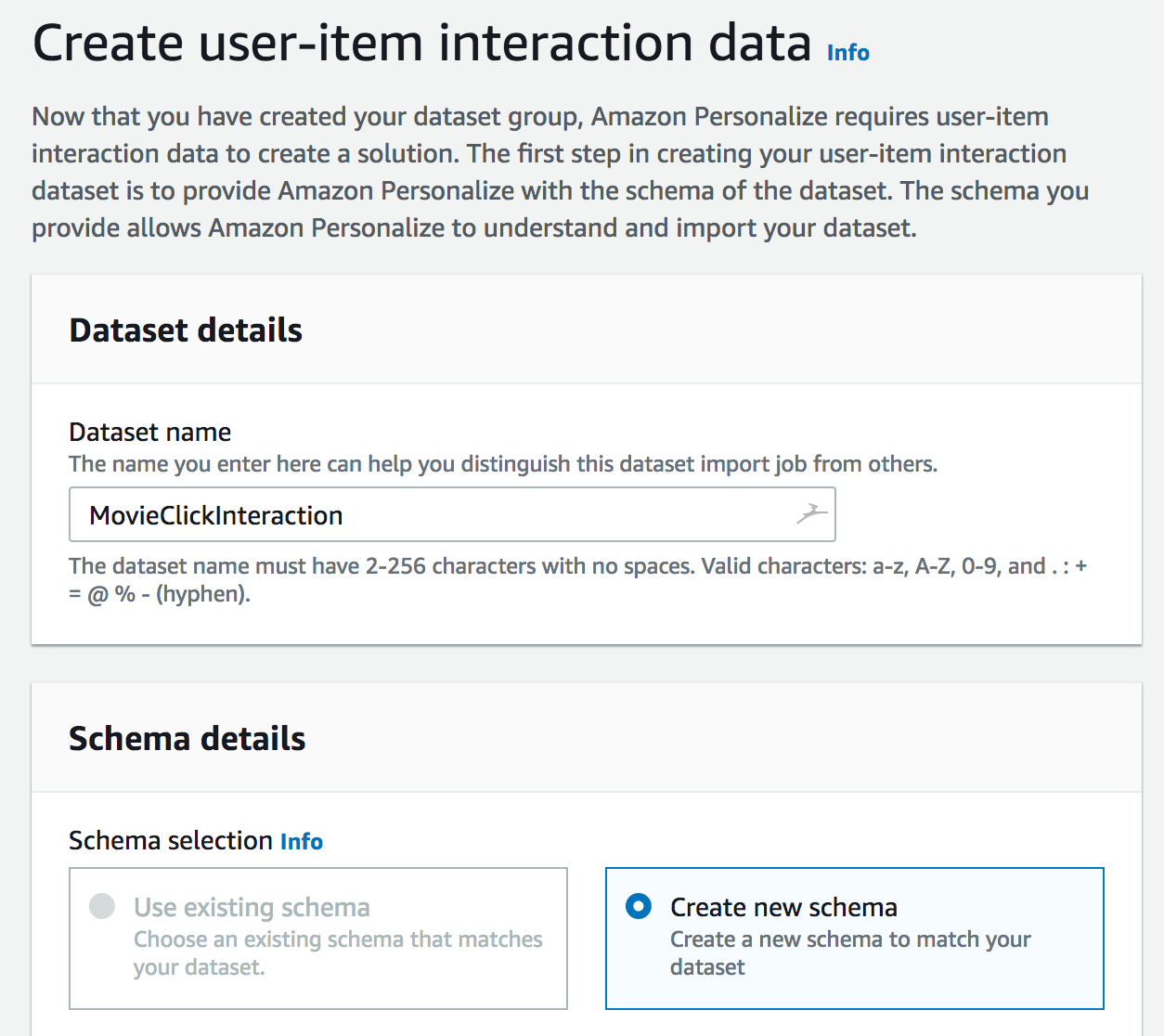
或者,我们现在可以定义一个导入作业,以便将历史数据添加到数据集中:如上所述,我们将跳过此步骤,因为所有数据都来自此流。
配置事件跟踪器
下一步是创建事件跟踪器,以使我们可以将流事件发送到数据集组。

大约一分钟后,我们的跟踪器准备就绪。请注意跟踪 ID:我们需要它来发送事件。
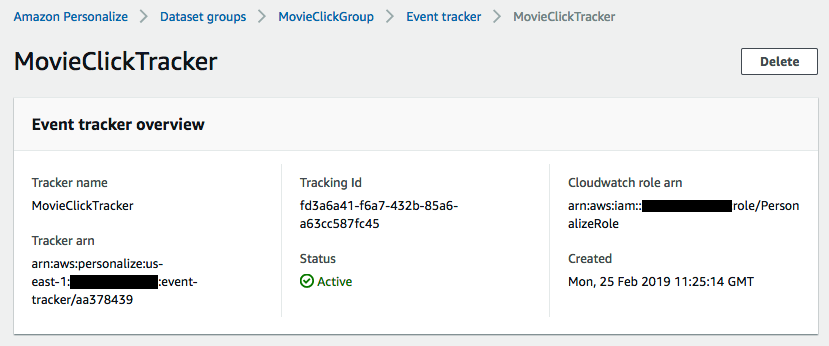
创建数据集组
当 Amazon Personalize 创建事件跟踪器时,它会自动在与事件跟踪器关联的数据集组中创建一个新数据集。此数据集具有良好定义的架构,存储以下信息:
- user_id 和 session_id:这些值由您的应用程序定义。
- tracking_id:事件跟踪器 ID。
- timestamp、item_id、event_type、event_value:这些值描述了事件本身,必须由您的应用程序传送。
可通过两种不同的方式将实时事件发送到此数据集:
- 服务器端,通过 AWS 开发工具包:请注意,可以从任何来源提取,无论您的代码是在 AWS 内部(例如在 Amazon EC2 或 AWS Lambda 中)还是外部托管。
- 使用 AWS Amplify JavaScript 库。
我们来了解一下两个选项。
使用 AWS 开发工具包发送实时事件
此过程非常简单:我们只需使用 PutEvents API 发送单个事件,或最多 10 个事件的列表。当然,我们可以使用任何 AWS 开发工具包:由于我最喜欢的语言是 Python,因此我们可以使用 boto3 开发工具包发送事件。
import boto3
personalize_events = boto3.client('personalize-events')
personalize_events.put_events(
trackingId = <TRACKING_ID>,
userId = <USER_ID>,
sessionId = <SESSION_ID>,
eventList = [
{
"eventId": "event1",
"sentAt": 1549959198,
"eventType": "rating",
"properties": """{\"itemId\": \"123\", \"eventValue\": \"4\"}"""
},
{
"eventId": "event2",
"sentAt": 1549959205,
"eventType": "rating",
"properties": """{\"itemId\": \"456\", \"eventValue\": \"2\"}"""
}
]
)在我们的应用程序中,我们给电影123评分 4 分,给电影 456 评分 2 分。我们使用适当的跟踪标识符,向事件跟踪器发送两个事件:
- eventId:一种应用程序特定标识符。
- sentAt:一种时间戳,匹配架构中定义的 timestamp 属性。该值自 Unix 纪元(1970 年 1 月 1 日00:00:00.000 UTC)开始走秒,并且独立于任何特定时区。
- eventType:事件类型,匹配架构中定义的 event_type 属性,
- properties:项目 ID 和事件值,匹配架构中定义 item_id 和 event_value 属性。
以下使 Java 中的类似代码片段。
List<Event> eventList = new ArrayList<>();
eventList.add(new Event().withProperties(properties).withType(eventType));
PutEventsRequest request = new PutEventsRequest()
.withTrackingId(<TRACKING_ID>)
.withUserId(<USER_ID>)
.withSessionId(<SESSION_ID>)
.withEventList(eventList);
client.putEvents(request)现在你明白了!
使用 AWS Amplify 发送实时事件
AWS Amplify 是一个 JavaScript 库,可以轻松创建、配置和实施由 AWS 提供支持的可扩展移动和 Web 应用程序。它与 Amazon Personalize 中的事件跟踪服务集成。
在我们发送事件之前,需要几个设置步骤。为简洁起见,请参阅 Amazon Personalize 文档中的这些详细说明:
- 在 Amazon Cognito 中创建身份池,以便对用户进行身份验证。
- 使用池 ID 和跟踪器 ID 配置 Amazon Personalize 插件。
完成此操作后,即可将事件发送到 Amazon Personalize。我们仍然可以使用任何文本字符串作为事件类型,但请注意,有几种特殊类型可用:
- Identify 允许您将特定用户的 userId 发送到 Amazon Personalize。userId 随后成为后续调用中的可选参数。
- MediaAutoTrack 自动计算媒体事件的播放、暂停和恢复位置,而 Amazon Personalize 将位置用作事件值。
使用 AWS Amplify 发送一些示例事件的方法如下:
Analytics.record({
eventType: "Identify",
properties: {
"userId": "<USER_ID>"
}
}, "AmazonPersonalize");
Analytics.record({
eventType: "<EVENT_TYPE>",
properties: {
"itemId": "<ITEM_ID>",
"eventValue": "<EVENT_VALUE>"
}
}, "AmazonPersonalize");
Analytics.record({
eventType: "MediaAutoTrack",
properties: {
"itemId": "<ITEM_ID>",
"domElementId": "MEDIA DOM ELEMENT ID"
}
}, "AmazonPersonalize");如您所见,这也非常简单。
创建推荐解决方案
现在我们已了解如何摄取事件,接下来让我们定义如何训练我们的推荐解决方案。
首先我们需要选择一个配方,配方不仅是一种算法:它还包括预定义的功能转换、算法的初始参数以及自动模型调整。因此,有了配方,就无需掌握个性化方面的专业知识。Amazon Personalize 提供几种适用于不同用例的配方。
如果您初次接触机器学习,可能会想知道这些配方中哪一个最适合您的用例。无需担心:如前所述,Amazon Personalize 支持 AutoML,这是一种自动搜索最佳配方的新技术,所以让我们启用它。虽然我们正在使用它,但我们也要求 Amazon Personalize 自动调整配方参数。
所有这一切在 AWS 控制台中都非常简单:因为您可能希望从现在开始实现自动化,所以让我们改用 AWS CLI。
$ aws personalize create-solution \
--name jsimon-movieclick-solution \
--perform-auto-ml --perform-hpo \
--dataset-group-arn $DATASET_GROUP_ARN现在我们已准备好培训解决方案。无需担心服务器,培训将在完全托管的基础设施上进行。
$ aws personalize create-solution-version \
--solution-arn $SOLUTION_ARN
培训完成后,我们可以使用解决方案版本来创建推荐活动。
部署推荐活动
仍然无需担心服务器! 实际上,活动规模会根据入站流量自动扩展:我们只需定义想要支持的每秒最小事务数 (TPS)。
此编号用于调整托管模型的初始队列的大小。它还会影响推荐收费(每 TPS 小时 0.20 美元)。在这里,我将该参数设置为 10,这意味着最初的收费为每小时 2 美元。如果流量超过 10 TPS,Personalize 将向上扩展,根据新的 TPS 设置增加计费。一旦流量下降,Personalize 将向下收缩,但不会低于我的最低 TPS 设置。
$ aws personalize create-campaign \
--name jsimon-movieclick-campaign \
--min-provisioned-tps 10 \
--solution-version-arn $SOLUTION_VERSION_ARN如果您以后需要使用新的解决方案版本更新活动,只需使用 UpdateCampaign API 并传送新解决方案版本的 ARN 即可。
部署活动后,我们可以快速测试它是否能够推荐新电影。
实时推荐新项目
我认为没有比这更简单的了:只需传送用户的 ID 并接收推荐即可。
$ aws personalize-rec get-recommendations \
--campaign-arn $CAMPAIGN_ARN \
--user-id 123 --query "itemList[*].itemId"
["1210", "260", "2571", "110", "296", "1193", ...]现在,我们已准备好将您的推荐模型集成到您的应用程序中。例如,Web 应用程序必须执行以下步骤才能显示推荐电影列表:
- 以我们最喜欢的语言使用 GetRecommendations API,来调用活动并接收针对给定用户的电影推荐,
- 从后端读取电影元数据(例如,图像URL、标题、流派、发布日期等),
- 生成要在用户的浏览器中呈现的 HTML 代码。
Amazon Personalize 实际操作
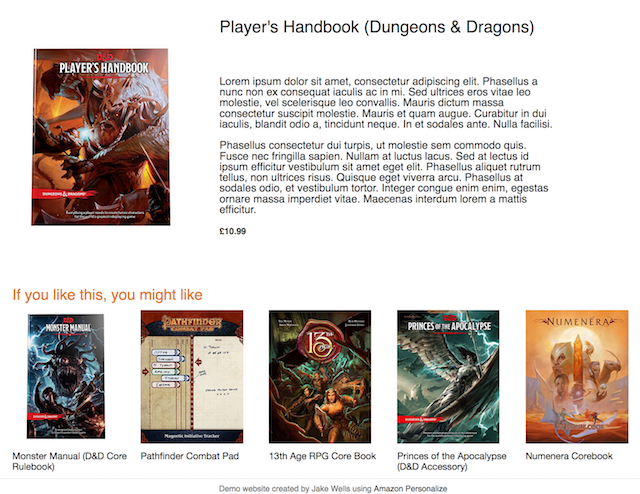
实际上,我的同事 Jake Wells 已经建立了一个推荐书籍的 Web 应用程序。利用包含超过 1900 万条书评的开放数据集,Jake 首先使用托管在 Amazon SageMaker 上的笔记本来清理和准备数据。然后,他使用 Amazon Personalize 训练了一个推荐模型,并编写了一个演示推荐过程的简单 Web 应用程序。这是一个非常酷的项目,绝对值得专门写一篇博文来介绍!
现已推出!
无论您是使用历史数据还是事件流,都可以通过一些简单的 API 调用来训练和部署推荐模型。无需任何机器学习经验,所以请访问 thinkwithwp.com/personalize,尝试一下,并让我们知道您的想法。
Amazon Personalize 向以下区域提供:美国东部(俄亥俄州)、美国东部(弗吉尼亚北部)、美国西部(俄勒冈州)、亚太地区(东京)、亚太地区(新加坡)和欧盟(爱尔兰)
该服务也是 AWS 免费套餐的一部分。注册后的前两个月,您将获得:
1.数据处理和存储:每月高达 20 GB
2.训练:每月训练小时数多达 100 小时
3.预测:每月多达 50 TPS 小时的实时推荐
我们期待您的反馈!