亚马逊AWS官方博客
新的 Amazon FinSpace 简化了金融服务的数据管理和分析
管理数据是金融服务行业 (FSI) 的核心。我曾在私人银行和基金管理公司工作,并帮助分析师收集、汇总和分析来自内部数据源(如投资组合管理、订单管理和会计系统)以及外部数据源(如实时市场反馈和历史股票定价以及替代数据系统)的数百 PB 级数据。在此期间,我花了时间尝试跨组织接收器访问数据、管理权限以及构建系统,以便在不断增长和更复杂的环境中自动执行重复任务。
今天,我们正在推出一种解决方案,该解决方案应该可以减少我花在此类项目上的时间: Amazon FinSpace 是专为金融服务行业打造的数据管理和分析解决方案。Amazon FinSpace 将查找和准备数据所需的时间从几个月缩短到几分钟,以便分析师可以将更多时间花在分析上。
客户告诉我们的
在合并和分析数据之前,分析师花费数周或数月时间来查找和访问多个部门的数据,每个部门都按市场、仪器或地理位置专业化。除了这种逻辑隔离之外,数据还在不同的 IT 系统、文件系统或网络中进行物理隔离。由于对数据的访问受监管和政策的严格控制,分析师必须准备访问请求,并向合规部门进行解释。这是一个非常依赖手动的特设过程。
一旦获得访问权限,他们通常必须对越来越大的数据集执行计算逻辑(例如布林线、指数移动平均线,或平均正确范围),以准备数据进行分析或从数据派生信息。这些计算通常在容量受限的服务器上运行,因为它们不是为了处理现代金融世界中的工作负载规模而设计的。即使是服务器端系统也在努力扩展,并跟上其需要存储和分析的数据集日益增长的规模。
Amazon FinSpace 如何提供帮助
Amazon FinSpace 免除了存储、准备、管理和审计数据访问权限所需的无差别繁重工作。它自动执行查找数据和准备分析所涉及的步骤。Amazon FinSpace 使用行业和内部数据分类惯例存储和组织数据。分析师连接到 Amazon FinSpace 网络界面,使用熟悉的商业术语(“标普 500”、“CAC40”、“欧元私募股权基金”)搜索数据。
分析师可以使用包含 100 多个专用函数的内置库为时间序列数据准备其所选择的数据集。他们可以使用集成的 Jupyter 笔记本对数据进行实验,并在几分钟内以云规模并行执行这些金融数据转换。最后,Amazon FinSpace 提供了一个框架来管理数据访问和审计谁在何时访问哪些数据。它会跟踪数据的使用情况并生成合规和审计报告。
Amazon FinSpace 还使处理历史数据变得轻松。假设我建立了一个计算信用风险的模型。这种模式依赖利率和通货膨胀率。这两种比率会经常更新。当前与客户相关的风险水平与几个月前的风险水平不同,因为当时通货膨胀率和利率不同。当数据分析师用当前的角度和过去的角度看数据时,他们称之为双时态建模。借助 Amazon FinSpace,您可以轻松回到从前,并比较模型在多个维度的同时如何演变。
为了向您展示 Amazon FinSpace 的运作方式,假设我有一个分析师和数据科学家团队,我想为他们提供搜索、准备和分析数据的工具。
如何创建 Amazon FinSpace 环境
作为 AWS 账户管理员,我为金融分析师团队创建了一个工作环境。这是一个一次性的设置。
我导航到 Amazon FinSpace 控制台,然后单击 Create Environment(创建环境):

我给我的环境命名。我选择了用于加密静态数据的 KMS 加密密钥。然后,我选择与 AWS Single Sign-On 集成,或者在 Amazon FinSpace 中管理用户名和密码。 AWS Single Sign-On 集成允许您的分析师通过外部系统(如公司 Active Directory)进行身份验证,以访问 Amazon FinSpace 环境。在本例中,我选择自己管理凭证。

我创建了一个超级用户,该用户将在 Amazon FinSpace 环境中拥有管理权限。我点击 Add Superuse(添加超级用户):
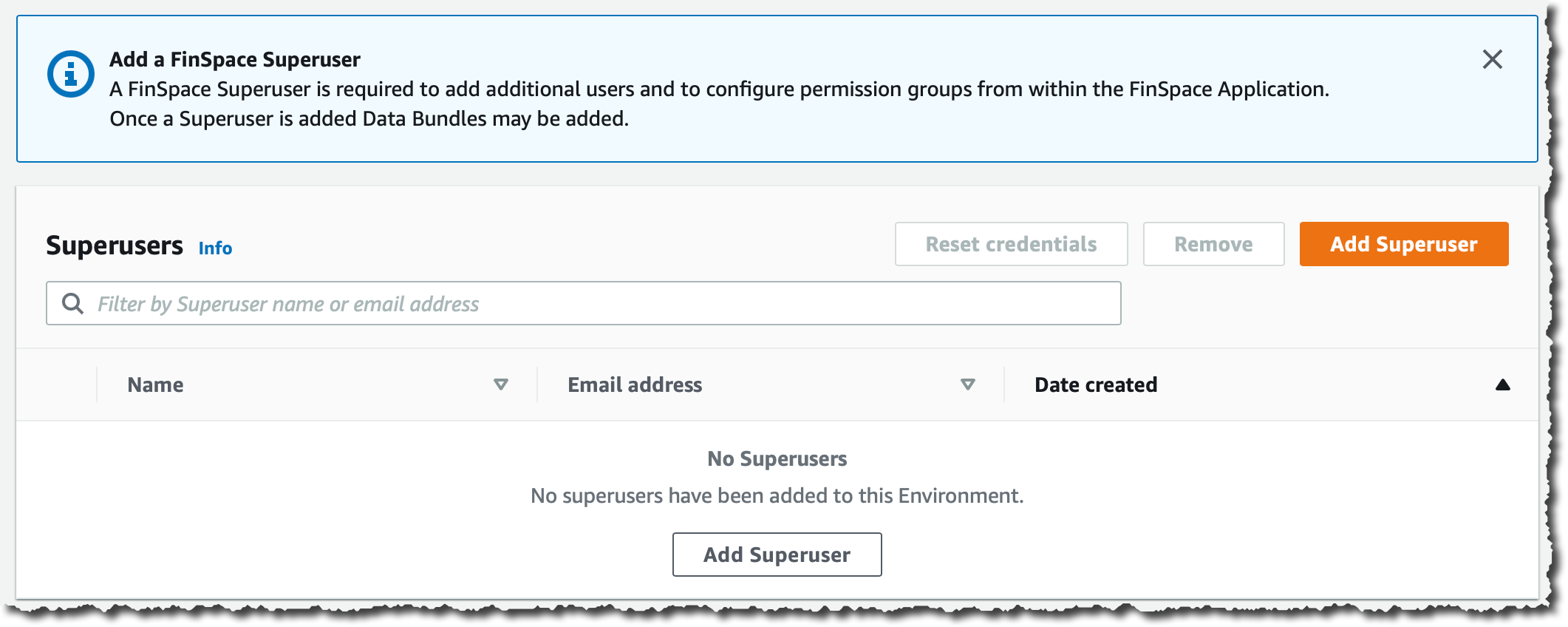
 我记下了临时密码。还复制了要发送给我的超级用户的消息文本。此消息包括初始连接到环境的连接说明。
我记下了临时密码。还复制了要发送给我的超级用户的消息文本。此消息包括初始连接到环境的连接说明。

超级用户有权添加其他用户并在 Amazon FinSpace 环境中自行管理这些用户的权限。
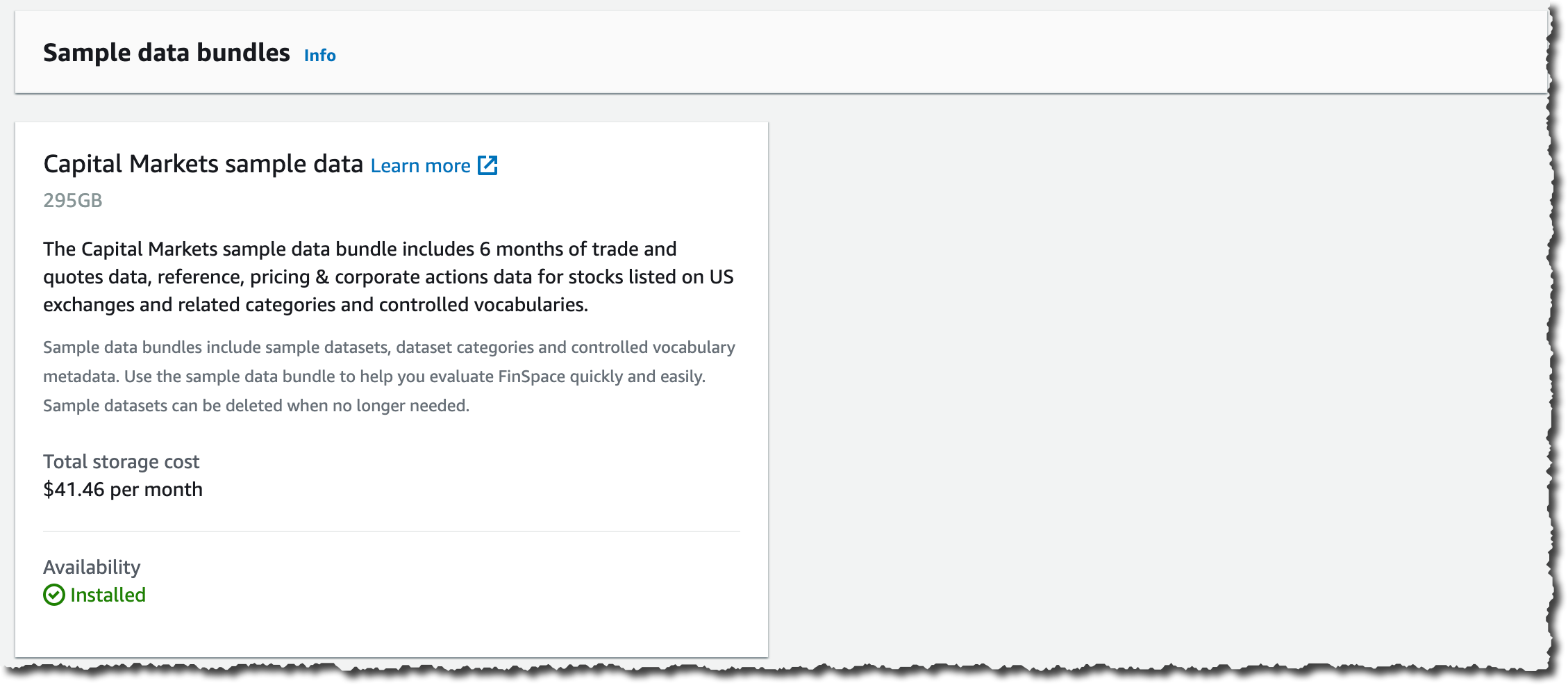
最后,仅为了此次演示的目的,我选择导入初始数据集。这样我可以从环境中的一些数据开始。只需在控制台中单击一下即可。此数据集的存储成本为每月 41.46 USD,我可以随时将其删除。
在 Sample data bundles(示例数据包)、Capital Markets sample data(资本市场示例数据)下,我单击 Install dataset(安装数据集)。这可能需要几分钟的时间,所以现在是站起来、伸展双腿和拿一杯咖啡的好时机。
如何使用 Amazon FinSpace 环境
作为金融分析师,我的 AWS 账户管理员向我发送了一封电子邮件,其中包含连接到我的 Amazon FinSpace 环境的 URL 以及相关凭证。我连接到 Amazon FinSpace 环境。
欢迎页面上值得注意几点。首先,在右上角,我单击了齿轮图标以访问环境设置。在这里我可以添加其他用户并管理他们的权限。其次,您可以在左侧按类别浏览不同的数据,或者通过在屏幕顶部的搜索栏上键入搜索查询来搜索特定的字词,然后在左侧细化搜索。
我可以使用 Amazon FinSpace 作为我的数据中心。数据是通过 API 提供的,或者我可以直接从工作站加载数据。我使用标签来描述数据集。数据集是数据的容器;更改是版本控制的,我可以创建数据的历史视图或使用 Amazon FinSpace 为我维护的自动更新数据视图。
对于这个演示,假设我收到了一位投资组合经理的请求,他想要一张图表,使用 AMZN 股票的 5 分钟时间条显示实际波动率。让我向您展示我如何使用搜索栏查找数据,然后使用笔记本来分析这些数据。
首先,我在数据集中搜索股价时间条摘要,间隔为 5 分钟。在搜索框中输入“股票”。我很幸运:第一个结果就是我想要的。如果需要的话,我可以使用左侧的分面来优化结果。

找到数据集后,我就会探索其描述、架构和其他信息。基于这些,我决定这是否是正确的数据集,以回应我的投资组合经理的请求。

我单击笔记本中的 Analyze(分析)以启动 Jupyter 笔记本,在此我将能够使用 PySpark 进一步探索数据。一旦笔记本打开,我首先会检查笔记本是否正确配置为使用 Amazon FinSpace PySpark 内核(启动内核需要 5-8 分钟)。

我单击第一个代码框上的 “play”(播放)以连接到 Spark 集群。

要分析我的数据集并回答我的 PM 提出的具体问题,我需要键入一些 PySpark 代码。出于本演示的目的,我使用了来自 Amazon FinSpace GitHub 存储库的示例代码。您可以将笔记本上传到您的环境中。单击上方屏幕左上角所示的向上箭头,从本地计算机中选择文件。
本笔记本从我之前发现的 Amazon FinSpace 目录 “US Equity Time-Bar Summary”(美国股票时间条摘要)数据中提取数据,然后使用 Amazon FinSpace 内置的分析函数 realized_volatility() 来计算一组股票代码和交易所事件类型的实际波动率。
在创建任何图表之前,让我们先了解一下数据集。数据的时间范围是什么? 此数据集中有哪些股票代码? 我用 Amazon FinSpace 提供的简单 select() 或 groupby() 函数来回答这些问题。我用下面的代码准备我的 FinSpaceAnalyticsAnalyser 课程:
from aws.finspace.analytics import FinSpaceAnalyticsManager
finspace = FinSpaceAnalyticsManager(spark = spark, endpoint=hfs_endpoint)
sumDF = finspace.read_data_view(dataset_id = dataset_id, data_view_id = view_id)完成后,我就可以开始探索数据集了:

我可以看到,2019 年 10 月 1 日至 2020 年 3 月 31 日之间有 561778 次 AMZN 交易和价格报价。
为了绘制实际波动率,我使用 Panda 来绘制价值:

当我执行这个代码块时,我会收到:

同样,我可以开始布林线分析,以检查波动率峰值是否造成了 AMZN 股票的超卖状况。我也在使用 Panda 来绘制价值。

然后生成这个图表:
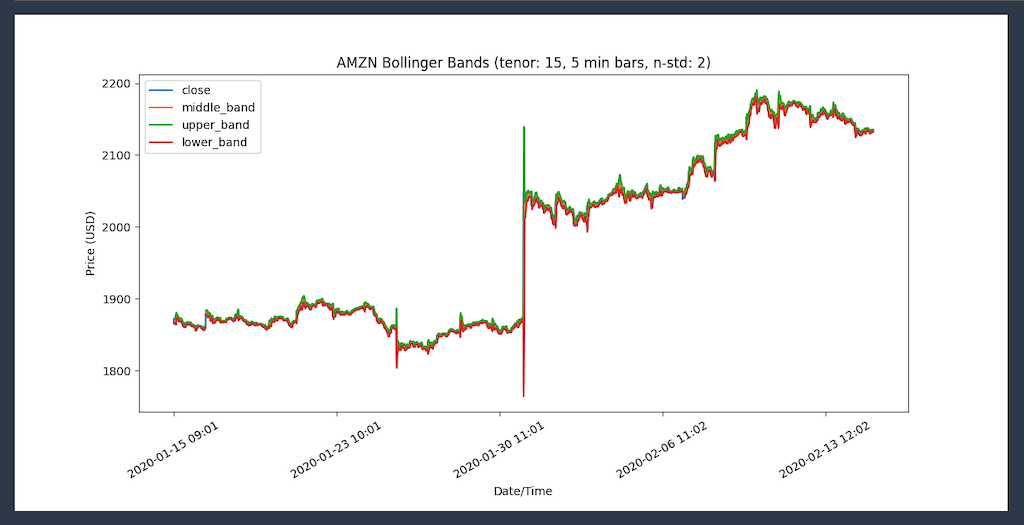
我准备回答投资组合经理的问题。但是为什么 2020 年 1 月 30 日会出现峰值? 答案在新闻中:“亚马逊在取得巨大收益后飙升。”፦)
可用性和定价
Amazon FinSpace 今天在美国东部(弗吉尼亚北部)、美国东部(俄亥俄)、美国西部(俄勒冈)、欧洲(爱尔兰)和加拿大(中部)推出。
像往常一样,我们仅针对您的项目所使用的资源向您收取费用。定价基于三个维度:有权访问该服务的分析师人数、摄取的数据量以及应用转换所用的计算时间。详细的定价信息可在服务定价页面上找到。
今天就试试吧,让我们知道您的反馈。