亚马逊AWS官方博客
面向农业科技的 AI:使用 Amazon Rekognition 自定义标签对猕猴桃进行分类
原文链接:https://thinkwithwp.com/cn/blogs/machine-learning/ai-for-agritech-classifying-kiwifruits-using-amazon-rekognition-custom-labels/

计算机视觉是人工智能 (AI) 的一个领域,借助于价格合理且基于云的训练计算,更高性能的算法,优化的可扩展模型的部署和推理,该领域越来越受到人们的关注和欢迎。但是,尽管在单个人工智能 (AI) 和机器学习 (ML) 领域取得了这些进展,但是将机器学习管道简化为一致且可观察的工作流程,以便规模较小的业务部门能够更轻松地访问,这仍然是一个很有挑战的目标。这一点在农业科技领域尤为明显,在这个领域中,计算机视觉在通过自动化提高产能方面具有巨大潜力。这种情况也存在于健康和安全领域,在这些领域中,危险的工作可以由人工智能而不是农民来完成。AWS 客户采用的农业应用包括根据产品的等级和缺陷对农产品进行分类(IntelloLabs、Clarifruit 和 Hectre),以及尽早有效地主动确定害虫控制措施 (Bayer Crop Science),这些都是计算机视觉大有可为的一些领域。
尽管这些计算机视觉应用具有一定的吸引力,但通常只有大型农业企业才能使用,因为特定边缘硬件架构的训练–编译–部署–推断序列非常复杂,导致技术与可以从中获得最大利益的从业人员之间出现某种程度的分离。许多情况下,这种脱节的根源在于人工智能/机器学习的复杂性,以及其在农业、林业和园艺等初级领域的端到端应用中缺乏明确的路径。在大多数情况下,雇用经验丰富的合格数据科学家来探索机会,而管理人员和运营商无法直接进行试验和创新,这样的前景在财务和组织方面都是不切实际的。最近在新西兰举行的一次农业科技演讲中,一位高管与会者强调,缺乏端到端的 AWS 计算机视觉解决方案是试验的限制因素,为了证明组织买进更强大的技术评估是合理之举,需要进行试验。
这篇博文旨在揭开 AWS AI/ML 服务如何协同工作的神秘面纱,并特别说明如何生成带标记的图像,针对该图像训练计算机视觉模型,以及如何使用 Amazon Rekognition 自定义标签部署自定义图像识别模型。按照本教程进行操作,您应该能够在大约一小时内启动并运行自定义计算机视觉模型,并根据与您的特定需求相关的数据,做出关于进一步投资 AI/ML 创新的更明智的判断。
训练图像存储
如以下管道中所示,生成自定义计算机视觉模型的第一步是生成用于训练模型的带标签的图像。为此,我们首先将未标记的训练图像加载到账户中的 Amazon Simple Storage Service (Amazon S3) 存储桶中,每个类别都存储在存储桶下其自己的文件夹中。在此示例中,我们的预测分类为两种猕猴桃(黄金和蒙蒂),并具有已知类型的图像。收集每个训练类别的图像后,只需通过 Amazon S3 API 或AWS 管理控制台将图像上传到您的 Amazon S3 存储桶下其各自对应的文件夹中即可。

设置 Amazon Rekognition
要开始使用 Amazon Rekognition,请完成以下步骤:
1. 在 Amazon Rekognition 控制台上,选择 Use Custom Labels (使用自定义标签)。
2. 选择 Get started (开始) 以创建一个新项目。
项目用于存储模型和训练配置。
3. 输入项目名称(例如,Kiwifruit-classifier-project)。
4. 选择 Create (创建)。
5. 在 Datasets (数据集) 页面上,选择 Create new dataset (创建新数据集)。
6. 输入数据集的名称(例如,kiwifruit classifier)。
7. 对于 Image location (图像位置),请选择 Import images from Amazon S3 bucket (从 Amazon S3 存储桶导入图像)。
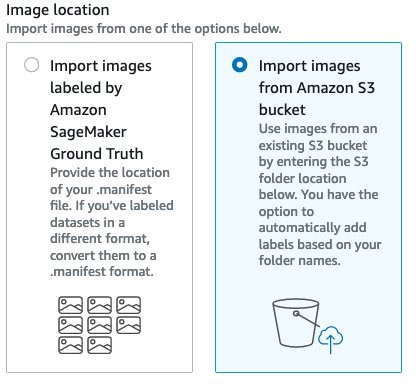
8. 对于 S3 folder location (S3 文件夹位置),输入存储图像的位置。
9. 对于 Automatic labeling (自动标记),选择 Automatically attach a label to my images based on the folder they’re stored in (根据存储的文件夹自动将标签附加到我的图像)。
这意味着文件夹的标签作为该图像的分类应用于每个图像。

10. 对于 Policy (策略),将提供的 JSON 输入 Amazon S3 存储桶,以确保 Amazon Rekognition 可以访问该数据来训练模型。
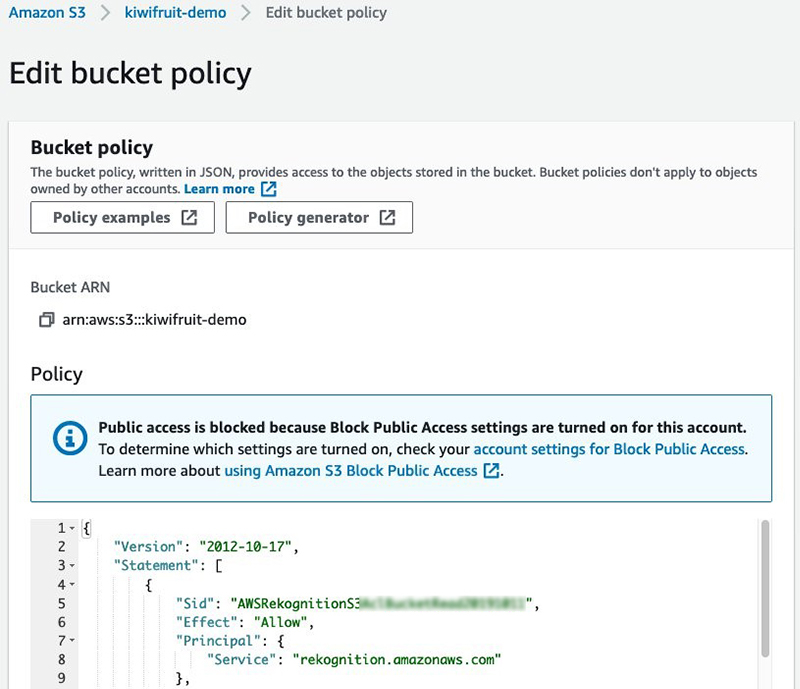
11. 选择 Submit (提交)。
训练模型
现在我们已经使用存储这些图像的文件夹名称成功生成了标记的图像,我们可以训练我们的模型。
1. 选择 Train model (训练模型) 以创建一个用于在训练后存储模型的项目。
2. 对于 Choose project (选择项目),输入您创建的项目的 ARN。
3. 对于 Choose a training dataset (选择训练数据集),选择您创建的数据集。
4. 对于 Create test set (创建测试集),选择 Split training dataset (拆分训练数据集)。
这会自动保留已标记的数据部分,用于评估我们训练后的模型的性能。

5. 选择 Train (训练) 开始训练作业。
训练可能需要一些时间(取决于您提供的带标签图像的数量),您可以在 Projects (项目) 页面监控进度。
6. 训练完成后,选择项目下的模型以查看其在每个分类中的性能。
7. 在 Use your model (使用您的模型) 下,选择 API Code (API 代码)。
这将允许您获取代码示例以启动和停止模型,并使用 AWS 命令行界面 (AWS CLI) 进行推理。
启动模型后部署推理终端节点可能需要几分钟的时间。

使用新训练的模型
现在,您拥有了一个感到满意的经过训练的模型,使用该模型就像使用提供的示例 API 代码引用 Amazon S3 存储桶中的图像来生成推理一样简单。以下代码是使用 boto3 库来分析图像的 Python 代码示例:
只需解析 JSON 响应即可访问负载的 Name (名称) 和 Confidence (置信度) 字段以进行图像推理。
总结
在这篇博文中,我们学习了如何使用 Amazon Rekognition 自定义标签和 Amazon S3 文件夹标签功能来训练图像分类模型,部署该模型并使用它进行推理。接下来的步骤可能是遵循适用于多类分类器的类似步骤,或者使用 Amazon SageMaker Ground Truth 生成除了带分类标签之外还带有边界框注释的数据。有关在农业中使用计算机视觉的其他方法的更多信息和想法,请参阅 AWS Machine Learning 博客和 AWS for Industries:农业博客。