AWS Big Data Blog
Tag: AWS Glue

Optimize Python ETL by extending Pandas with AWS Data Wrangler
April 2024: This post was reviewed for accuracy. Developing extract, transform, and load (ETL) data pipelines is one of the most time-consuming steps to keep data lakes, data warehouses, and databases up to date and ready to provide business insights. You can categorize these pipelines into distributed and non-distributed, and the choice of one or […]

Stream Twitter data into Amazon Redshift using Amazon MSK and AWS Glue streaming ETL
This post demonstrates how customers, system integrator (SI) partners, and developers can use the serverless streaming ETL capabilities of AWS Glue with Amazon Managed Streaming for Kafka (Amazon MSK) to stream data to a data warehouse such as Amazon Redshift. We also show you how to view Twitter streaming data on Amazon QuickSight via Amazon Redshift.
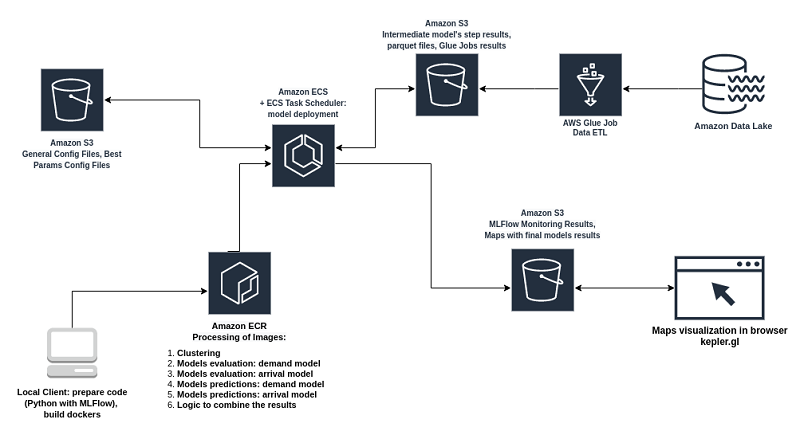
How Wind Mobility built a serverless data architecture
We parse through millions of scooter and user events generated daily (over 300 events per second) to extract actionable insight. We selected AWS Glue to perform this task. Our primary ETL job reads the newly added raw event data from Amazon S3, processes it using Apache Spark, and writes the results to our Amazon Redshift data warehouse. AWS Glue plays a critical role in our ability to scale on demand. After careful evaluation and testing, we concluded that AWS Glue ETL jobs meet all our needs and free us from procuring and managing infrastructure.

Process data with varying data ingestion frequencies using AWS Glue job bookmarks
We often have data processing requirements in which we need to merge multiple datasets with varying data ingestion frequencies. Some of these datasets are ingested one time in full, received infrequently, and always used in their entirety, whereas other datasets are incremental, received at certain intervals, and joined with the full datasets to generate output. To address this requirement, this post demonstrates how to build an extract, transform, and load (ETL) pipeline using AWS Glue.

Extend your Amazon Redshift Data Warehouse to your Data Lake
Amazon Redshift is a fast, fully managed, cloud-native data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence tools. Many companies today are using Amazon Redshift to analyze data and perform various transformations on the data. However, as data continues to grow and become […]
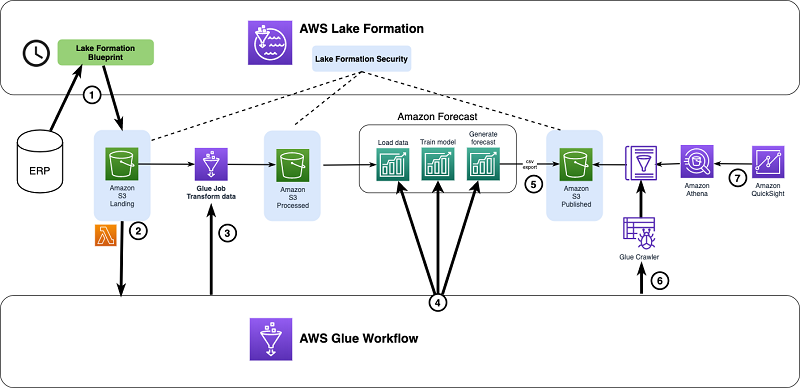
Build an end to end, automated inventory forecasting capability with AWS Lake Formation and Amazon Forecast
This post demonstrates how you can automate the data extraction, transformation, and use of Forecast for the use case of a retailer that requires recurring replenishment of inventory. You achieve this by using AWS Lake Formation to build a secure data lake and ingest data into it, orchestrate the data transformation using an AWS Glue workflow, and visualize the forecast results in Amazon QuickSight.
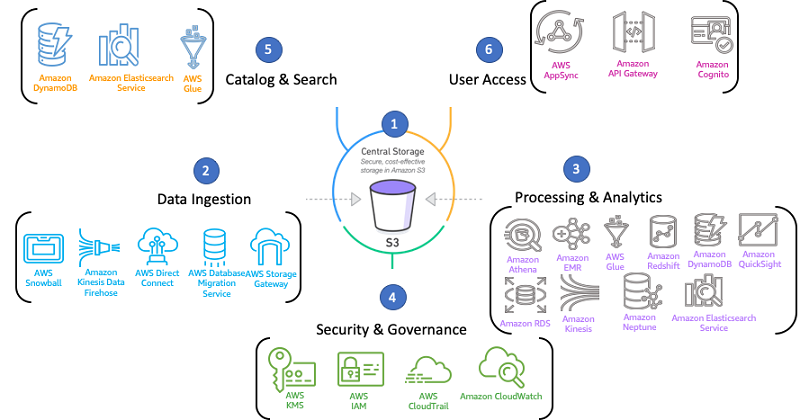
Build an AWS Well-Architected environment with the Analytics Lens
Building a modern data platform on AWS enables you to collect data of all types, store it in a central, secure repository, and analyze it with purpose-built tools. Yet you may be unsure of how to get started and the impact of certain design decisions. To address the need to provide advice tailored to specific technology and application domains, AWS added the concept of well-architected lenses 2017. AWS now is happy to announce the Analytics Lens for the AWS Well-Architected Framework. This post provides an introduction of its purpose, topics covered, common scenarios, and services included.
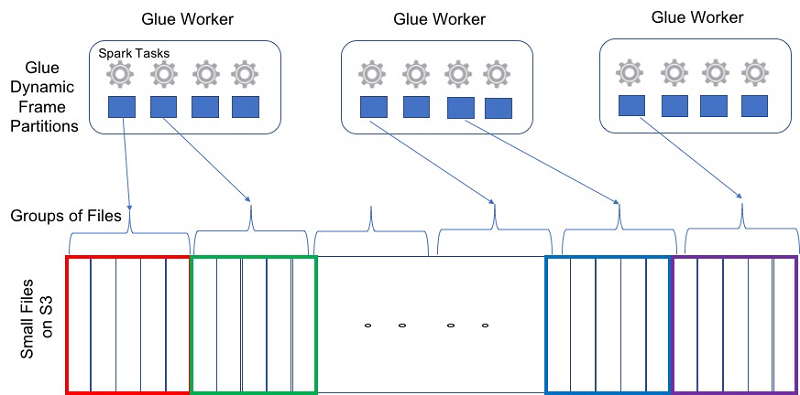
Optimize memory management in AWS Glue
In this post, we discuss a number of techniques to enable efficient memory management for Apache Spark applications when reading data from Amazon S3 and compatible databases using a JDBC connector. We describe how Glue ETL jobs can utilize the partitioning information available from AWS Glue Data Catalog to prune large datasets, manage large number of small files, and use JDBC optimizations for partitioned reads and batch record fetch from databases. You can use some or all of these techniques to help ensure your ETL jobs perform well.

Build an automatic data profiling and reporting solution with Amazon EMR, AWS Glue, and Amazon QuickSight
This post demonstrates how to extend the metadata contained in the Data Catalog with profiling information calculated with an Apache Spark application based on the Amazon Deequ library running on an EMR cluster. You can query the Data Catalog using the AWS CLI. You can also build a reporting system with Athena and Amazon QuickSight to query and visualize the data stored in Amazon S3.

Simplify data pipelines with AWS Glue automatic code generation and Workflows
In this post, we discuss how to leverage the automatic code generation process in AWS Glue ETL to simplify common data manipulation tasks, such as data type conversion and flattening complex structures. We also explore using AWS Glue Workflows to build and orchestrate data pipelines of varying complexity. Lastly, we look at how you can leverage the power of SQL, with the use of AWS Glue ETL and Glue Data Catalog, to query and transform your data.