AWS Big Data Blog
Category: AWS Lambda

Extend geospatial queries in Amazon Athena with UDFs and AWS Lambda
Amazon Athena is a serverless and interactive query service that allows you to easily analyze data in Amazon Simple Storage Service (Amazon S3) and 25-plus data sources, including on-premises data sources or other cloud systems using SQL or Python. Athena built-in capabilities include querying for geospatial data; for example, you can count the number of […]

Enrich VPC Flow Logs with resource tags and deliver data to Amazon S3 using Amazon Kinesis Data Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. VPC Flow Logs is an AWS feature that captures information about the network traffic flows going to and from network interfaces in Amazon Virtual Private Cloud (Amazon VPC). Visibility to the network […]

How a blockchain startup built a prototype solution to solve the need of analytics for decentralized applications with AWS Data Lab
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This post is co-written with Dr. Quan Hoang Nguyen, CTO at Fantom Foundation. Here at Fantom Foundation (Fantom), we have developed a high performance, highly scalable, and secure smart contract platform. It’s […]

Build a pseudonymization service on AWS to protect sensitive data: Part 1
According to an article in MIT Sloan Management Review, 9 out of 10 companies believe their industry will be digitally disrupted. In order to fuel the digital disruption, companies are eager to gather as much data as possible. Given the importance of this new asset, lawmakers are keen to protect the privacy of individuals and […]

Audit AWS service events with Amazon EventBridge and Amazon Kinesis Data Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon EventBridge is a serverless event bus that makes it easy to build event-driven applications at scale using events generated from your applications, integrated software as a service (SaaS) applications, and AWS […]

Doing more with less: Moving from transactional to stateful batch processing
Amazon processes hundreds of millions of financial transactions each day, including accounts receivable, accounts payable, royalties, amortizations, and remittances, from over a hundred different business entities. All of this data is sent to the eCommerce Financial Integration (eCFI) systems, where they are recorded in the subledger. Ensuring complete financial reconciliation at this scale is critical […]

Unify log aggregation and analytics across compute platforms
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Our customers want to make sure their users have the best experience running their application on AWS. To make this happen, you need to monitor and fix software problems as quickly as […]
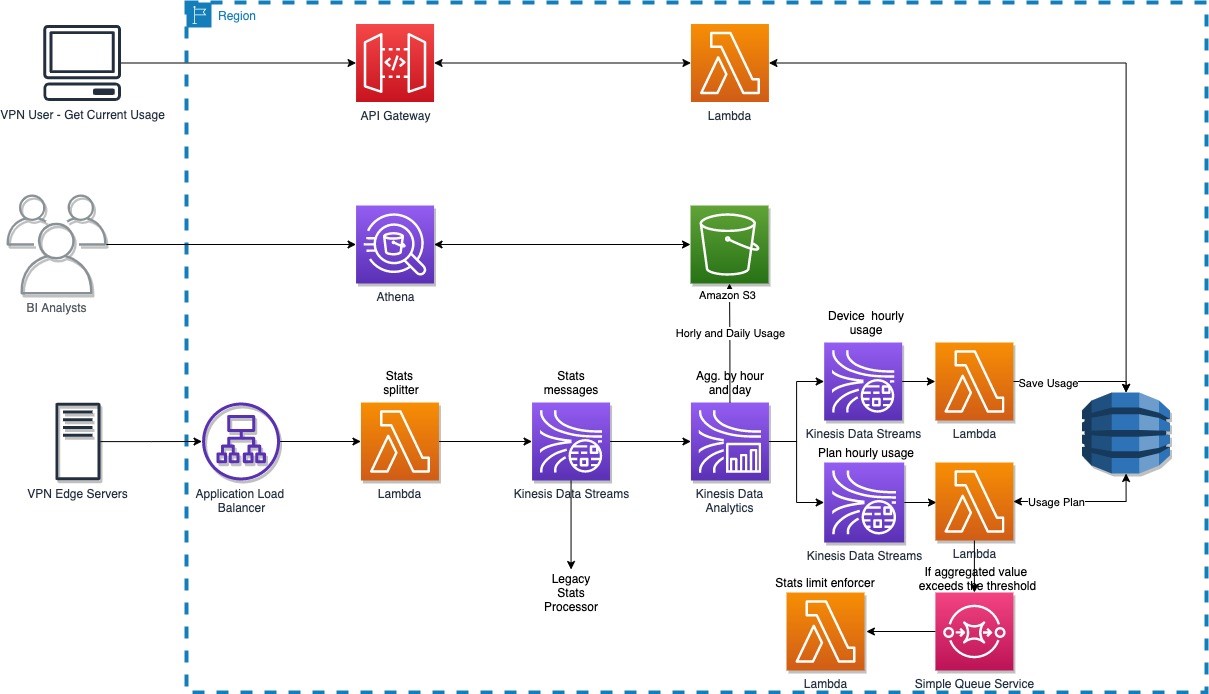
How NortonLifelock built a serverless architecture for real-time analysis of their VPN usage metrics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This post presents a reference architecture and optimization strategies for building serverless data analytics solutions on AWS using Amazon Kinesis Data Analytics. In addition, this post shows […]

Query SAP HANA using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use SAP HANA as your transactional data store, you may need to join the data in your data lake with SAP HANA in the cloud, SAP HANA […]

Query a Teradata database using Amazon Athena Federated Query and join with data in your Amazon S3 data lake
If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Teradata as your transactional data store, you may need to join the data in your data lake with Teradata in the cloud, Teradata running on Amazon Elastic Compute Cloud (Amazon EC2), or with an on-premises Teradata database, for example to build […]