AWS Big Data Blog
Category: AWS Lake Formation

Introducing catalog federation for Apache Iceberg tables in the AWS Glue Data Catalog
AWS Glue now supports catalog federation for remote Iceberg tables in the Data Catalog. With catalog federation, you can query remote Iceberg tables, stored in Amazon S3 and cataloged in remote Iceberg catalogs, using AWS analytics engines and without moving or duplicating tables. In this post, we discuss how to get started with catalog federation for Iceberg tables in the Data Catalog.

Implement fine-grained access control for Iceberg tables using Amazon EMR on EKS integrated with AWS Lake Formation
On February 6th 2025, AWS introduced fine-grained access control based on AWS Lake Formation for EMR on EKS from Amazon EMR 7.7 and higher version. You can now significantly enhance your data governance and security frameworks using this feature. In this post, we demonstrate how to implement FGAC on Apache Iceberg tables using EMR on EKS with Lake Formation.

Break down data silos and seamlessly query Iceberg tables in Amazon SageMaker from Snowflake
This blog post discusses how to create a seamless integration between Amazon SageMaker Lakehouse and Snowflake for modern data analytics. It specifically demonstrates how organizations can enable Snowflake to access tables in AWS Glue Data Catalog (stored in S3 buckets) through SageMaker Lakehouse Iceberg REST Catalog, with security managed by AWS Lake Formation. The post provides a detailed technical walkthrough of implementing this integration, including creating IAM roles and policies, configuring Lake Formation access controls, setting up catalog integration in Snowflake, and managing data access permissions. While four different patterns exist for accessing Iceberg tables from Snowflake, the blog focuses on the first pattern using catalog integration with SigV4 authentication and Lake Formation credential vending.

The Amazon SageMaker lakehouse architecture now automates optimization configuration of Apache Iceberg tables on Amazon S3
The Amazon SageMaker lakehouse architecture now automates optimization of Iceberg tables stored in Amazon S3 with catalog-level configuration, optimizing storage in your Iceberg tables and improving query performance. This post demonstrates an end-to-end flow to enable catalog level table optimization setting.
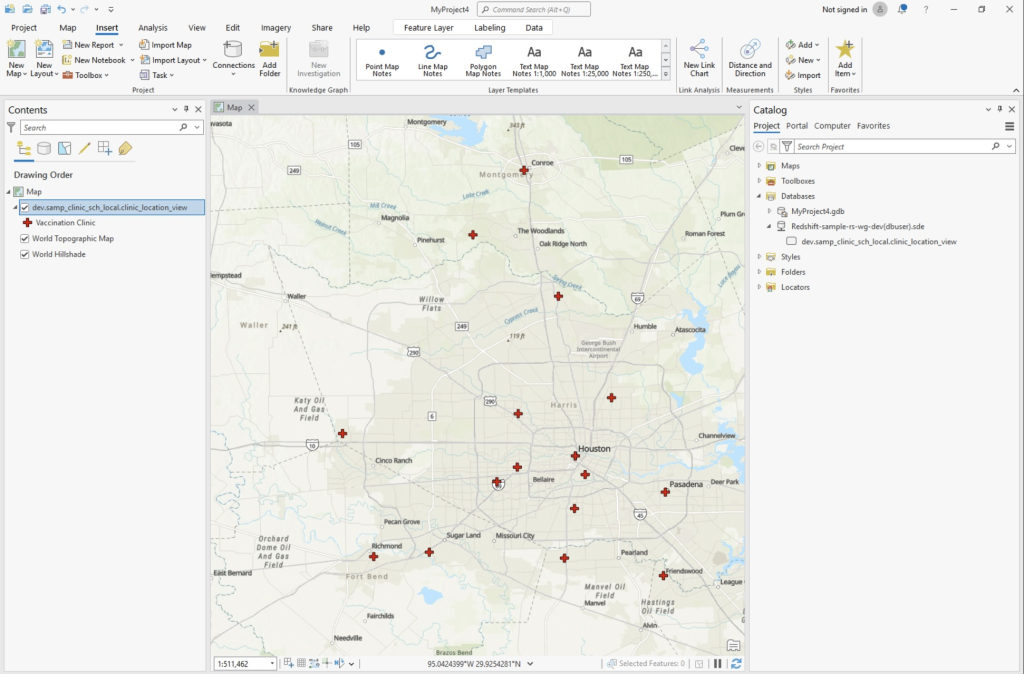
Geospatial data lakes with Amazon Redshift
In this post, we review how to set up Redshift Serverless to use geospatial data contained within a data lake to enhance maps in ArcGIS Pro. This technique helps builders and GIS analysts use available datasets in data lakes and transform it in Amazon Redshift to further enrich the data before presenting it on a map.

How Stifel built a modern data platform using AWS Glue and an event-driven domain architecture
In this post, we show you how Stifel implemented a modern data platform using AWS services and open data standards, building an event-driven architecture for domain data products while centralizing the metadata to facilitate discovery and sharing of data products.

Enforce table level access control on data lake tables using AWS Glue 5.0 with AWS Lake Formation
In this post, we show you how to enforce FTA control on AWS Glue 5.0 through Lake Formation permissions.

Simplify real-time analytics with zero-ETL from Amazon DynamoDB to Amazon SageMaker Lakehouse
At AWS re:Invent 2024, we introduced a no code zero-ETL integration between Amazon DynamoDB and Amazon SageMaker Lakehouse, simplifying how organizations handle data analytics and AI workflows. In this post, we share how to set up this zero-ETL integration from DynamoDB to your SageMaker Lakehouse environment.

Using AWS Glue Data Catalog views with Apache Spark in EMR Serverless and Glue 5.0
In this post, we guide you through the process of creating a Data Catalog view using EMR Serverless, adding the SQL dialect to the view for Athena, sharing it with another account using LF-Tags, and then querying the view in the recipient account using a separate EMR Serverless workspace and AWS Glue 5.0 Spark job and Athena. This demonstration showcases the versatility and cross-account capabilities of Data Catalog views and access through various AWS analytics services.

Configure cross-account access of Amazon SageMaker Lakehouse multi-catalog tables using AWS Glue 5.0 Spark
In this post, we show you how to share an Amazon Redshift table and Amazon S3 based Iceberg table from the account that owns the data to another account that consumes the data. In the recipient account, we run a join query on the shared data lake and data warehouse tables using Spark in AWS Glue 5.0. We walk you through the complete cross-account setup and provide the Spark configuration in a Python notebook.