AWS Big Data Blog
Category: AWS Glue

The Amazon SageMaker lakehouse architecture now automates optimization configuration of Apache Iceberg tables on Amazon S3
The Amazon SageMaker lakehouse architecture now automates optimization of Iceberg tables stored in Amazon S3 with catalog-level configuration, optimizing storage in your Iceberg tables and improving query performance. This post demonstrates an end-to-end flow to enable catalog level table optimization setting.

Automate data lineage in Amazon SageMaker using AWS Glue Crawlers supported data sources
In this post, we explore its real-world impact through the lens of an ecommerce company striving to boost their bottom line. To illustrate this practical application, we walk you through how you can use the prebuilt integration between SageMaker Catalog and AWS Glue crawlers to automatically capture lineage for data assets stored in Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB.

Accelerate your data quality journey for lakehouse architecture with Amazon SageMaker, Apache Iceberg on AWS, Amazon S3 tables, and AWS Glue Data Quality
This post explores how you can use AWS Glue Data Quality to maintain data quality of S3 Tables and Apache Iceberg tables on general purpose S3 buckets. We’ll discuss strategies for verifying the quality of published data and how these integrated technologies can be used to implement effective data quality workflows.

Build an analytics pipeline that is resilient to Avro schema changes using Amazon Athena
This post demonstrates how to build a solution by combining Amazon Simple Storage Service (Amazon S3) for data storage, AWS Glue Data Catalog for schema management, and Amazon Athena for one-time querying. We’ll focus specifically on handling Avro-formatted data in partitioned S3 buckets, where schemas can change frequently while providing consistent query capabilities across all data regardless of schema versions.

Secure generative SQL with Amazon Q
In this post, we discuss the design and security controls in place when using generative SQL and its use in both Amazon SageMaker Unified Studio and Amazon Redshift Query Editor v2.

Scale your AWS Glue for Apache Spark jobs with R type, G.12X, and G.16X workers
This post demonstrates how AWS Glue R type, G.12X, and G.16X workers help you scale up your AWS Glue for Apache Spark jobs.

Introducing Jobs in Amazon SageMaker
This post demonstrates how the new jobs experience works in SageMaker Unified Studio.

Revenue NSW modernises analytics with AWS, enabling unified and scalable data management, processing, and access
Revenue NSW, Australia’s principal revenue management agency, successfully modernized its analytics infrastructure using AWS services. In this blog post, we show how the organization transformed its on-premises data environment into a unified, scalable cloud-based solution using Amazon Redshift, AWS Database Migration Service, Amazon AppFlow, and AWS Glue.
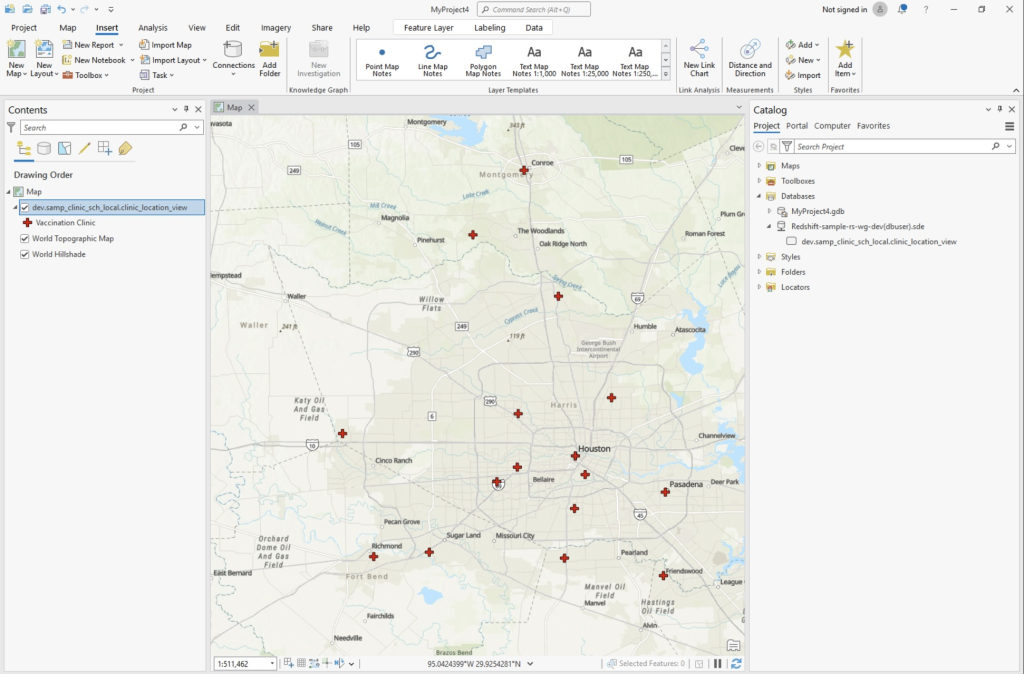
Geospatial data lakes with Amazon Redshift
In this post, we review how to set up Redshift Serverless to use geospatial data contained within a data lake to enhance maps in ArcGIS Pro. This technique helps builders and GIS analysts use available datasets in data lakes and transform it in Amazon Redshift to further enrich the data before presenting it on a map.

How Stifel built a modern data platform using AWS Glue and an event-driven domain architecture
In this post, we show you how Stifel implemented a modern data platform using AWS services and open data standards, building an event-driven architecture for domain data products while centralizing the metadata to facilitate discovery and sharing of data products.