AWS Big Data Blog
Category: Amazon Managed Streaming for Apache Kafka (Amazon MSK)

Build an end-to-end serverless streaming pipeline with Apache Kafka on Amazon MSK using Python
The volume of data generated globally continues to surge, from gaming, retail, and finance, to manufacturing, healthcare, and travel. Organizations are looking for more ways to quickly use the constant inflow of data to innovate for their businesses and customers. They have to reliably capture, process, analyze, and load the data into a myriad of […]

How VMware Tanzu CloudHealth migrated from self-managed Kafka to Amazon MSK
This is a post co-written with Rivlin Pereira & Vaibhav Pandey from Tanzu CloudHealth (VMware by Broadcom). VMware Tanzu CloudHealth is the cloud cost management platform of choice for more than 20,000 organizations worldwide, who rely on it to optimize and govern their largest and most complex multi-cloud environments. In this post, we discuss how […]

Best practices to implement near-real-time analytics using Amazon Redshift Streaming Ingestion with Amazon MSK
Amazon Redshift is a fully managed, scalable cloud data warehouse that accelerates your time to insights with fast, straightforward, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the most widely used cloud data warehouse. You can run […]

Simplify data streaming ingestion for analytics using Amazon MSK and Amazon Redshift
Towards the end of 2022, AWS announced the general availability of real-time streaming ingestion to Amazon Redshift for Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK), eliminating the need to stage streaming data in Amazon Simple Storage Service (Amazon S3) before ingesting it into Amazon Redshift. Streaming ingestion from Amazon […]

Secure connectivity patterns for Amazon MSK Serverless cross-account access
Amazon MSK Serverless is a cluster type of Amazon Managed Streaming for Apache Kafka (Amazon MSK) that makes it straightforward for you to run Apache Kafka without having to manage and scale cluster capacity. MSK Serverless automatically provisions and scales compute and storage resources. With MSK Serverless, you can use Apache Kafka on demand and […]

How Gupshup built their multi-tenant messaging analytics platform on Amazon Redshift
Gupshup is a leading conversational messaging platform, powering over 10 billion messages per month. Across verticals, thousands of large and small businesses in emerging markets use Gupshup to build conversational experiences across marketing, sales, and support. Gupshup’s carrier-grade platform provides a single messaging API for 30+ channels, a rich conversational experience-building tool kit for any […]

Break data silos and stream your CDC data with Amazon Redshift streaming and Amazon MSK
Data loses value over time. We hear from our customers that they’d like to analyze the business transactions in real time. Traditionally, customers used batch-based approaches for data movement from operational systems to analytical systems. Batch load can run once or several times a day. A batch-based approach can introduce latency in data movement and […]

Amazon MSK now provides up to 29% more throughput and up to 24% lower costs with AWS Graviton3 support
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that enables you to build and run applications that use Apache Kafka to process streaming data. Today, we’re excited to bring the benefits of Graviton3 to Kafka workloads, with Amazon MSK now offering M7g instances for new MSK provisioned clusters. AWS Graviton […]

Amazon MSK Serverless now supports Kafka clients written in all programming languages
Amazon MSK Serverless is a cluster type for Amazon Managed Streaming for Apache Kafka (Amazon MSK) that is the most straightforward way to run Apache Kafka clusters without having to manage compute and storage capacity. With MSK Serverless, you can run your applications without having to provision, configure, or optimize clusters, and you pay for […]
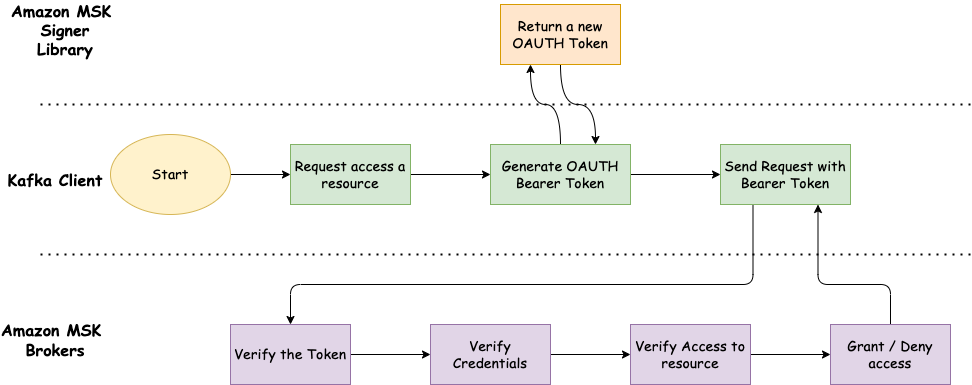
Amazon MSK IAM authentication now supports all programming languages
The AWS Identity and Access Management (IAM) authentication feature in Amazon Managed Streaming for Apache Kafka (Amazon MSK) now supports all programming languages. Administrators can simplify and standardize access control to Kafka resources using IAM. This support is based on SASL/OUATHBEARER, an open standard for authorization and authentication. Both Amazon MSK provisioned and serverless cluster […]