AWS Big Data Blog
Category: Amazon Kinesis

Top 10 Flink SQL queries to try in Amazon Kinesis Data Analytics Studio
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon Kinesis Data Analytics Studio makes it easy to analyze streaming data in real time and build stream processing applications using standard SQL, Python, and Scala. With […]
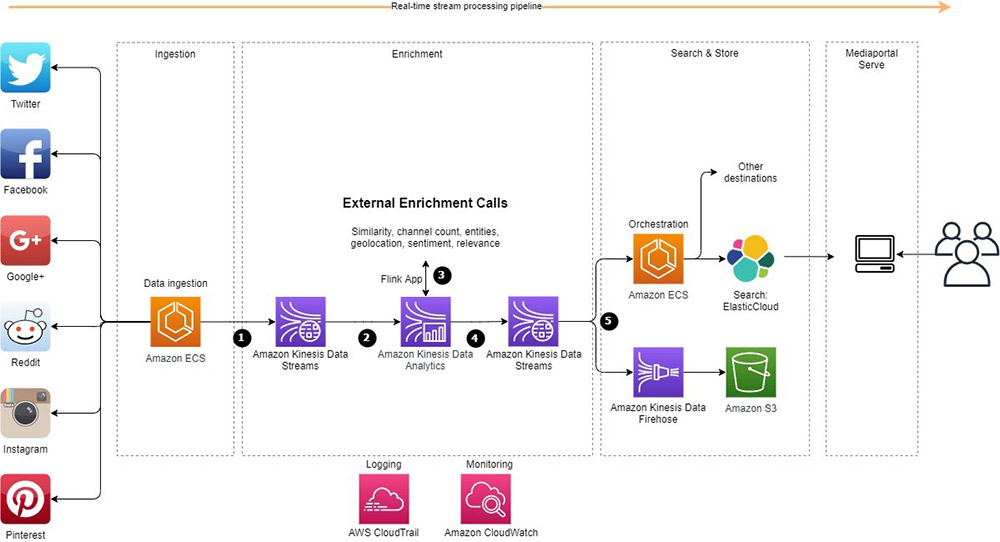
How Optus improves broadband and mobile customer experience using the Network Data Analytics platform on AWS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This is a guest blog post co-written by Rajagopal Mahendran, Development Manager at the Optus IT Innovation Team. Optus is part of The Singtel group, which operates […]

Use Grok patterns in AWS Glue to process streaming data into Amazon Elasticsearch Service
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Recently, we launched AWS Glue custom connectors for Amazon OpenSearch Service, which provides the capability to ingest data into Amazon OpenSearch Service with just a few clicks. You can now use Amazon OpenSearch Service as a data store for your […]

Enrich your data stream asynchronously using Amazon Kinesis Data Analytics for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Streaming data into or out of a data system must be fast. One of the most expensive pieces of any streaming system is the I/O of the […]
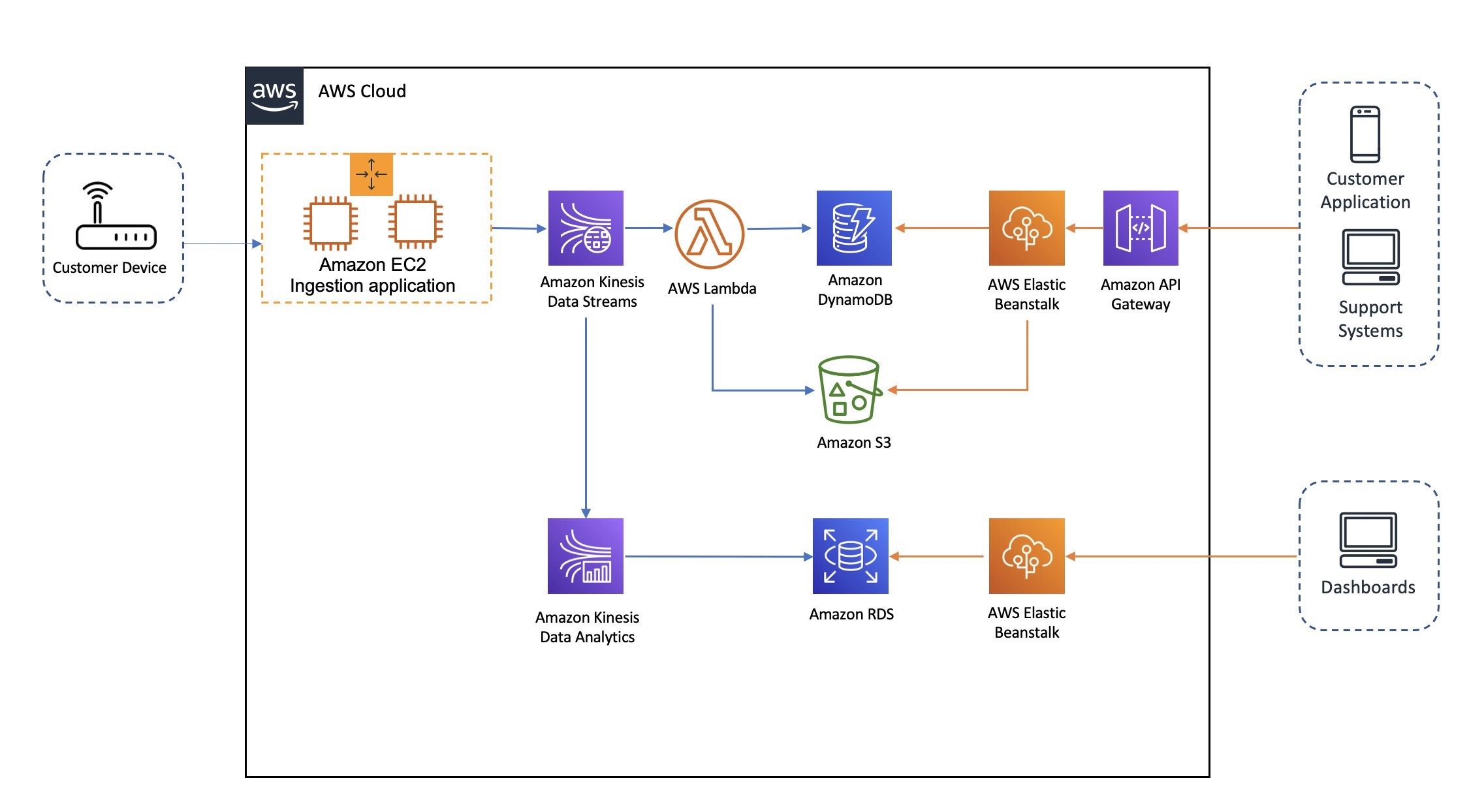
How Isentia improves customer experience by modernizing their real-time media monitoring and intelligence platform with Amazon Kinesis Data Analytics for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This is a blog post co-written by Karl Platz at Isentia. In their own words, “Isentia is the leading media monitoring, intelligence and insights solution provider in […]

Build seamless data streaming pipelines with Amazon Kinesis Data Streams and Amazon Data Firehose for Amazon DynamoDB tables
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. The global wearables market […]

Build a real-time streaming application using Apache Flink Python API with Amazon Kinesis Data Analytics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon Kinesis Data Analytics is now expanding its Apache Flink offering by adding support for Python. This is exciting news for many of our customers who use […]
Build a serverless tracking pixel solution in AWS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Let’s describe the typical use case where a tracking pixel solution, also known as a web beacon, might help you: Analyzing web traffic is critical to understanding […]

Build a data lake using Amazon Kinesis Data Streams for Amazon DynamoDB and Apache Hudi
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. July 2023: This post was reviewed for accuracy. Amazon DynamoDB helps you capture high-velocity data such as clickstream data to form customized user profiles and online order […]
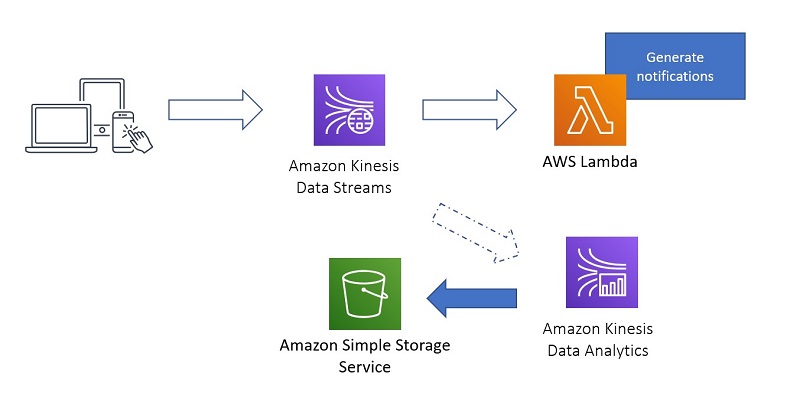
Retaining data streams up to one year with Amazon Kinesis Data Streams
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Streaming data is used extensively for use cases like sharing data between applications, streaming ETL (extract, transform, and load), real-time analytics, processing data from internet of things […]