AWS Big Data Blog
Category: Amazon Athena

How AWS helped Altron Group accelerate their vision for optimized customer engagement
This is a guest post co-authored by Jacques Steyn, Senior Manager Professional Services at Altron Group. Altron is a pioneer of providing data-driven solutions for their customers by combining technical expertise with in-depth customer understanding to provide highly differentiated technology solutions. Alongside their partner AWS, they participated in AWS Data-Driven Everything (D2E) workshops and a […]

Centralize near-real-time governance through alerts on Amazon Redshift data warehouses for sensitive queries
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers. In many organizations, one or multiple Amazon Redshift data warehouses […]

Harmonize data using AWS Glue and AWS Lake Formation FindMatches ML to build a customer 360 view
In today’s digital world, data is generated by a large number of disparate sources and growing at an exponential rate. Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their data lake to derive […]

Enable business users to analyze large datasets in your data lake with Amazon QuickSight
This blog post is co-written with Ori Nakar from Imperva. Imperva Cloud WAF protects hundreds of thousands of websites and blocks billions of security events every day. Events and many other security data types are stored in Imperva’s Threat Research Multi-Region data lake. Imperva harnesses data to improve their business outcomes. To enable this transformation […]

Accelerate data science feature engineering on transactional data lakes using Amazon Athena with Apache Iceberg
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) and data sources residing in AWS, on-premises, or other cloud systems using SQL or Python. Athena is built on open-source Trino and Presto engines, and Apache Spark frameworks, with no provisioning or configuration effort […]

How Cargotec uses metadata replication to enable cross-account data sharing
This is a guest blog post co-written with Sumesh M R from Cargotec and Tero Karttunen from Knowit Finland. Cargotec (Nasdaq Helsinki: CGCBV) is a Finnish company that specializes in cargo handling solutions and services. They are headquartered in Helsinki, Finland, and operates globally in over 100 countries. With its leading cargo handling solutions and […]
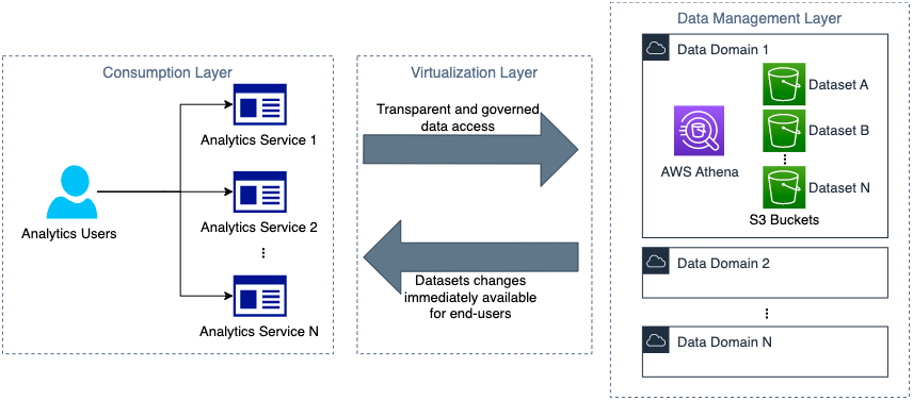
How Novo Nordisk built distributed data governance and control at scale
This is a guest post co-written with Jonatan Selsing and Moses Arthur from Novo Nordisk. This is the second post of a three-part series detailing how Novo Nordisk, a large pharmaceutical enterprise, partnered with AWS Professional Services to build a scalable and secure data and analytics platform. The first post of this series describes the […]

Perform upserts in a data lake using Amazon Athena and Apache Iceberg
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your data lake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable). Apache Iceberg is an open table format for data lakes that manages large collections of files as […]
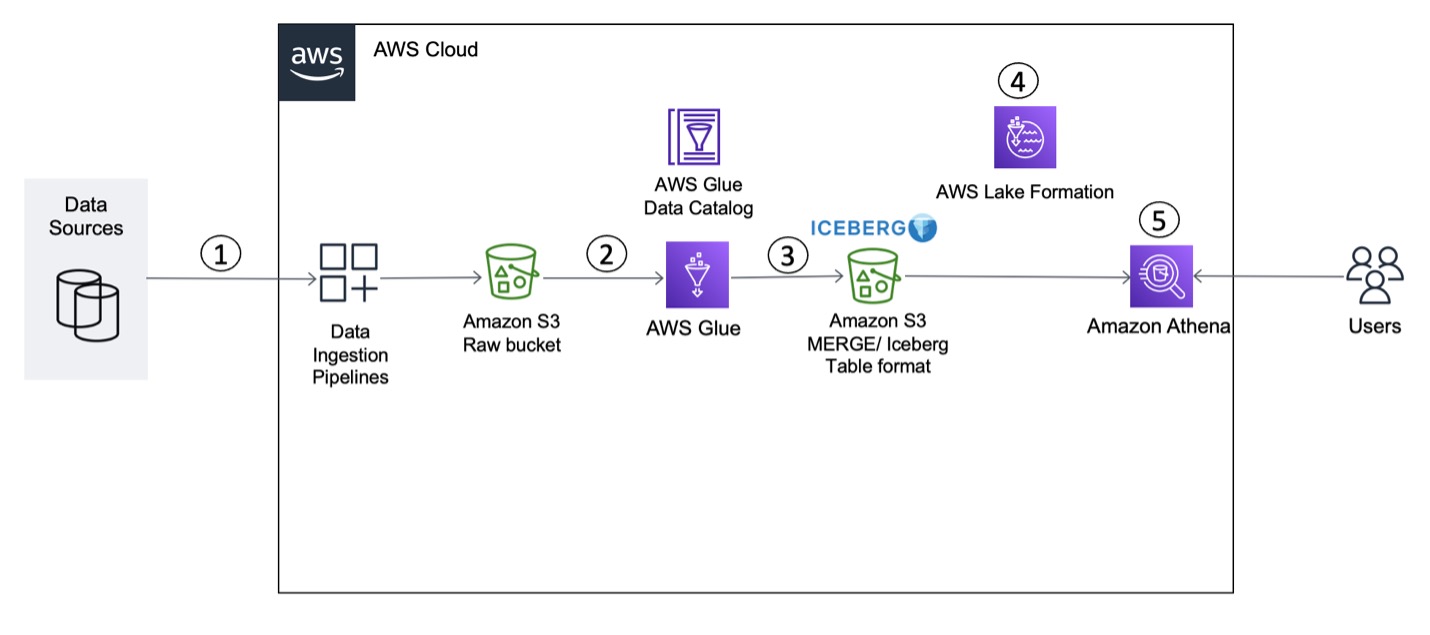
Build a transactional data lake using Apache Iceberg, AWS Glue, and cross-account data shares using AWS Lake Formation and Amazon Athena
Building a data lake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. It allows you to access diverse data sources, build business intelligence dashboards, build AI and machine learning (ML) models to provide customized customer experiences, and accelerate the curation of new datasets for consumption by adopting a modern data […]

Visualize Confluent data in Amazon QuickSight using Amazon Athena
This is a guest post written by Ahmed Saef Zamzam and Geetha Anne from Confluent. Businesses are using real-time data streams to gain insights into their company’s performance and make informed, data-driven decisions faster. As real-time data has become essential for businesses, a growing number of companies are adapting their data strategy to focus on […]