AWS News Blog
New – Using Step Functions to Orchestrate Amazon EMR Workloads

|
AWS Step Functions allows you to add serverless workflow automation to your applications. The steps of your workflow can run anywhere, including in AWS Lambda functions, on Amazon Elastic Compute Cloud (Amazon EC2), or on-premises. To simplify building workflows, Step Functions is directly integrated with multiple AWS Services: Amazon Elastic Container Service (Amazon ECS), AWS Fargate, Amazon DynamoDB, Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS), AWS Batch, AWS Glue, Amazon SageMaker, and (to run nested workflows) with Step Functions itself.
Starting today, Step Functions connects to Amazon EMR, enabling you to create data processing and analysis workflows with minimal code, saving time, and optimizing cluster utilization. For example, building data processing pipelines for machine learning is time consuming and hard. With this new integration, you have a simple way to orchestrate workflow capabilities, including parallel executions and dependencies from the result of a previous step, and handle failures and exceptions when running data processing jobs.
Specifically, a Step Functions state machine can now:
- Create or terminate an EMR cluster, including the possibility to change the cluster termination protection. In this way, you can reuse an existing EMR cluster for your workflow, or create one on-demand during execution of a workflow.
- Add or cancel an EMR step for your cluster. Each EMR step is a unit of work that contains instructions to manipulate data for processing by software installed on the cluster, including tools such as Apache Spark, Hive, or Presto.
- Modify the size of an EMR cluster instance fleet or group, allowing you to manage scaling programmatically depending on the requirements of each step of your workflow. For example, you may increase the size of an instance group before adding a compute-intensive step, and reduce the size just after it has completed.
When you create or terminate a cluster or add an EMR step to a cluster, you can use synchronous integrations to move to the next step of your workflow only when the corresponding activity has completed on the EMR cluster.
Reading the configuration or the state of your EMR clusters is not part of the Step Functions service integration. In case you need that, the EMR List* and Describe* APIs can be accessed using Lambda functions as tasks.
Building a Workflow with EMR and Step Functions
On the Step Functions console, I create a new state machine. The console renders it visually, so that is much easier to understand:

To create the state machine, I use the following definition using the Amazon States Language (ASL):
{
"StartAt": "Should_Create_Cluster",
"States": {
"Should_Create_Cluster": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.CreateCluster",
"BooleanEquals": true,
"Next": "Create_A_Cluster"
},
{
"Variable": "$.CreateCluster",
"BooleanEquals": false,
"Next": "Enable_Termination_Protection"
}
],
"Default": "Create_A_Cluster"
},
"Create_A_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:createCluster.sync",
"Parameters": {
"Name": "WorkflowCluster",
"VisibleToAllUsers": true,
"ReleaseLabel": "emr-5.28.0",
"Applications": [{ "Name": "Hive" }],
"ServiceRole": "EMR_DefaultRole",
"JobFlowRole": "EMR_EC2_DefaultRole",
"LogUri": "s3://aws-logs-123412341234-eu-west-1/elasticmapreduce/",
"Instances": {
"KeepJobFlowAliveWhenNoSteps": true,
"InstanceFleets": [
{
"InstanceFleetType": "MASTER",
"TargetOnDemandCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m4.xlarge"
}
]
},
{
"InstanceFleetType": "CORE",
"TargetOnDemandCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m4.xlarge"
}
]
}
]
}
},
"ResultPath": "$.CreateClusterResult",
"Next": "Merge_Results"
},
"Merge_Results": {
"Type": "Pass",
"Parameters": {
"CreateCluster.$": "$.CreateCluster",
"TerminateCluster.$": "$.TerminateCluster",
"ClusterId.$": "$.CreateClusterResult.ClusterId"
},
"Next": "Enable_Termination_Protection"
},
"Enable_Termination_Protection": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:setClusterTerminationProtection",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"TerminationProtected": true
},
"ResultPath": null,
"Next": "Add_Steps_Parallel"
},
"Add_Steps_Parallel": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Step_One",
"States": {
"Step_One": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The first step",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"hive-script",
"--run-hive-script",
"--args",
"-f",
"s3://eu-west-1.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q",
"-d",
"INPUT=s3://eu-west-1.elasticmapreduce.samples",
"-d",
"OUTPUT=s3://MY-BUCKET/MyHiveQueryResults/"
]
}
}
},
"End": true
}
}
},
{
"StartAt": "Wait_10_Seconds",
"States": {
"Wait_10_Seconds": {
"Type": "Wait",
"Seconds": 10,
"Next": "Step_Two (async)"
},
"Step_Two (async)": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The second step",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"hive-script",
"--run-hive-script",
"--args",
"-f",
"s3://eu-west-1.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q",
"-d",
"INPUT=s3://eu-west-1.elasticmapreduce.samples",
"-d",
"OUTPUT=s3://MY-BUCKET/MyHiveQueryResults/"
]
}
}
},
"ResultPath": "$.AddStepsResult",
"Next": "Wait_Another_10_Seconds"
},
"Wait_Another_10_Seconds": {
"Type": "Wait",
"Seconds": 10,
"Next": "Cancel_Step_Two"
},
"Cancel_Step_Two": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:cancelStep",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"StepId.$": "$.AddStepsResult.StepId"
},
"End": true
}
}
}
],
"ResultPath": null,
"Next": "Step_Three"
},
"Step_Three": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The third step",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"hive-script",
"--run-hive-script",
"--args",
"-f",
"s3://eu-west-1.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q",
"-d",
"INPUT=s3://eu-west-1.elasticmapreduce.samples",
"-d",
"OUTPUT=s3://MY-BUCKET/MyHiveQueryResults/"
]
}
}
},
"ResultPath": null,
"Next": "Disable_Termination_Protection"
},
"Disable_Termination_Protection": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:setClusterTerminationProtection",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"TerminationProtected": false
},
"ResultPath": null,
"Next": "Should_Terminate_Cluster"
},
"Should_Terminate_Cluster": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.TerminateCluster",
"BooleanEquals": true,
"Next": "Terminate_Cluster"
},
{
"Variable": "$.TerminateCluster",
"BooleanEquals": false,
"Next": "Wrapping_Up"
}
],
"Default": "Wrapping_Up"
},
"Terminate_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:terminateCluster.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId"
},
"Next": "Wrapping_Up"
},
"Wrapping_Up": {
"Type": "Pass",
"End": true
}
}
}
I let the Step Functions console create a new AWS Identity and Access Management (IAM) role for the executions of this state machine. The role automatically includes all permissions required to access EMR.
This state machine can either use an existing EMR cluster, or create a new one. I can use the following input to create a new cluster that is terminated at the end of the workflow:
{
"CreateCluster": true,
"TerminateCluster": true
}
To use an existing cluster, I need to provide input in the cluster ID, using this syntax:
{
"CreateCluster": false,
"TerminateCluster": false,
"ClusterId": "j-..."
}
Let’s see how that works. As the workflow starts, the Should_Create_Cluster Choice state looks into the input to decide if it should enter the Create_A_Cluster state or not. There, I use a synchronous call (elasticmapreduce:createCluster.sync) to wait for the new EMR cluster to reach the WAITING state before progressing to the next workflow state. The AWS Step Functions console shows the resource that is being created with a link to the EMR console:

After that, the Merge_Results Pass state merges the input state with the cluster ID of the newly created cluster to pass it to the next step in the workflow.
Before starting to process any data, I use the Enable_Termination_Protection state (elasticmapreduce:setClusterTerminationProtection) to help ensure that the EC2 instances in my EMR cluster are not shut down by an accident or error.
Now I am ready to do something with the EMR cluster. I have three EMR steps in the workflow. For the sake of simplicity, these steps are all based on this Hive tutorial. For each step, I use Hive’s SQL-like interface to run a query on some sample CloudFront logs and write the results to Amazon Simple Storage Service (Amazon S3). In a production use case, you’d probably have a combination of EMR tools processing and analyzing your data in parallel (two or more steps running at the same time) or with some dependencies (the output of one step is required by another step). Let’s try to do something similar.
First I execute Step_One and Step_Two inside a Parallel state:
- Step_One is running the EMR step synchronously as a job (
elasticmapreduce:addStep.sync). That means that the execution waits for the EMR step to be completed (or cancelled) before moving on to the next step in the workflow. You can optionally add a timeout to monitor that the execution of the EMR step happens within an expected time frame. - Step_Two is adding an EMR step asynchronously (
elasticmapreduce:addStep). In this case, the workflow moves to the next step as soon as EMR replies that the request has been received. After a few seconds, to try another integration, I cancel Step_Two (elasticmapreduce:cancelStep). This integration can be really useful in production use cases. For example, you can cancel an EMR step if you get an error from another step running in parallel that would make it useless to continue with the execution of this step.
After those two steps have both completed and produce their results, I execute Step_Three as a job, similarly to what I did for Step_One. When Step_Three has completed, I enter the Disable_Termination_Protection step, because I am done using the cluster for this workflow.
Depending on the input state, the Should_Terminate_Cluster Choice state is going to enter the Terminate_Cluster state (elasticmapreduce:terminateCluster.sync) and wait for the EMR cluster to terminate, or go straight to the Wrapping_Up state and leave the cluster running.
Finally I have a state for Wrapping_Up. I am not doing much in this final state actually, but you can’t end a workflow from a Choice state.
In the EMR console I see the status of my cluster and of the EMR steps:
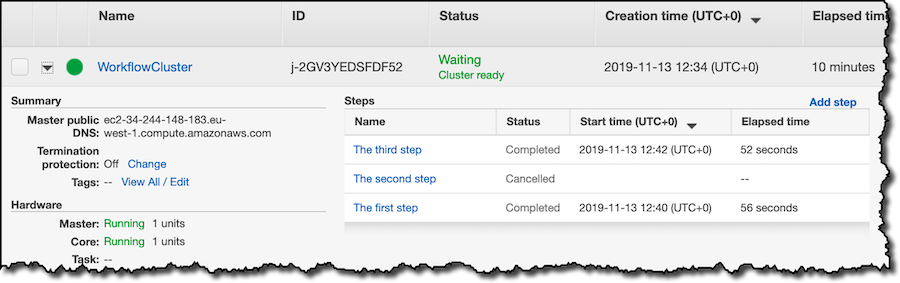
Using the AWS Command Line Interface (AWS CLI), I find the results of my query in the Amazon S3 bucket configured as output for the EMR steps:
aws s3 ls s3://MY-BUCKET/MyHiveQueryResults/
...
Based on my input, the EMR cluster is still running at the end of this workflow execution. I follow the resource link in the Create_A_Cluster step to go to the EMR console and terminate it. In case you are following along with this demo, be careful to not leave your EMR cluster running if you don’t need it.
Available Now
Step Functions integration with EMR is available in all regions. There is no additional cost for using this feature on top of the usual Step Functions and EMR pricing.
You can now use Step Functions to quickly build complex workflows for executing EMR jobs. A workflow can include parallel executions, dependencies, and exception handling. Step Functions makes it easy to retry failed jobs and terminate workflows after critical errors, because you can specify what happens when something goes wrong. Let me know what are you going to use this feature for!
— Danilo