AWS Architecture Blog
Field Notes: Building an automated scene detection pipeline for Autonomous Driving – ADAS Workflow
This Field Notes blog post in 2020 explains how to build an Autonomous Driving Data Lake using this Reference Architecture. Many organizations face the challenge of ingesting, transforming, labeling, and cataloging massive amounts of data to develop automated driving systems. In this re:Invent session, we explored an architecture to solve this problem using Amazon EMR, Amazon S3, Amazon SageMaker Ground Truth, and more. You learn how BMW Group collects 1 billion+ km of anonymized perception data from its worldwide connected fleet of customer vehicles to develop safe and performant automated driving systems.
Architecture Overview
The objective of this post is to describe how to design and build an end-to-end Scene Detection pipeline which:
- ingests ROS bag files using Amazon Elastic Container Service (ECS), AWS Fargate, Amazon S3 and Amazon Elastic File System (EFS)
- performs scene analytics like synchronization of ROS bag topics and object lane assignment using Spark on Amazon EMR
- exposes Scene Metadata to downstream consumers via Amazon S3 and Amazon DynamoDB
This architecture integrates an event-driven ROS bag ingestion pipeline running Docker containers on Elastic Container Service (ECS). This includes a scalable batch processing pipeline based on Amazon EMR and Spark. The solution also leverages AWS Fargate, Spot Instances, Elastic File System, AWS Glue, S3, and Amazon Athena.
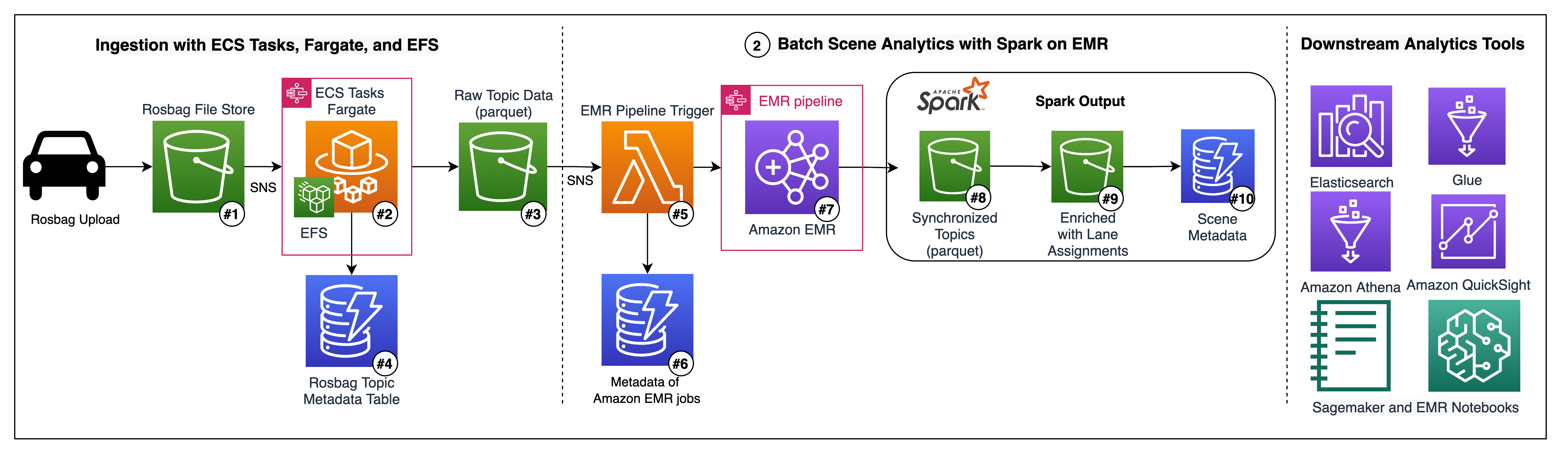
Figure 1 – Architecture Showing how to build an automated scene detection pipeline for Autonomous Driving
The data included in this demo was produced by one vehicle across four different drives in the United States. As the ROS bag files produced by the vehicle’s on-board software contains very complex data, such as Lidar Point Clouds, the files are usually very large (1+TB files are not uncommon).
These files usually need to be split into smaller chunks before being processed, as is the case in this demo. These files also may need to have post-processing algorithms applied to them, like lane detection or object detection.
In our case, the ROS bag files are split into approximately 10GB chunks and include topics for post-processed lane detections before they land in our S3 bucket. Our scene detection algorithm assumes the post processing has already been completed. The bag files include object detections with bounding boxes, and lane points representing the detected outline of the lanes.
Prerequisites
This post uses an AWS Cloud Development Kit (CDK) stack written in Python. You should follow the instructions in the AWS CDK Getting Started guide to set up your environment so you are ready to begin.
You can also use the config.json to customize the names of your infrastructure items, to set the sizing of your EMR cluster, and to customize the ROS bag topics to be extracted.
You will also need to be authenticated into an AWS account with permissions to deploy resources before executing the deploy script.
Deployment
The full pipeline can be deployed with one command: * `bash deploy.sh deploy true` . The progress of the deployment can be followed on the command line, but also in the CloudFormation section of the AWS console. Once deployed, the user must upload 2 or more bag files to the rosbag-ingest bucket to initiate the pipeline.
The default configuration requires two bag files to be processed before an EMR Pipeline is initiated. You would also have to manually initiate the AWS Glue Crawler to be able to explore the parquet data with tools like Athena or Quicksight.
ROS bag ingestion with ECS Tasks, Fargate, and EFS
This solution provides an end-to-end scene detection pipeline for ROS bag files, ingesting the ROS bag files from S3, and transforming the topic data to perform scene detection in PySpark on EMR. This then exposes scene descriptions via DynamoDB to downstream consumers.
The pipeline starts with an S3 bucket (Figure 1 – #1) where incoming ROS bag files can be uploaded from local copy stations as needed. We recommend, using Amazon Direct Connect for a private, high-throughout connection to the cloud.
This ingestion bucket is configured to initiate S3 notifications each time an object ending in the prefix “.bag” is created. An AWS Lambda function then initiates a Step Function for orchestrating the ECS Task. This passes the bucket and bag file prefix to the ECS task as environment variables in the container.
The ECS Task (Figure 1 – #2) runs serverless leveraging Fargate as the capacity provider, This avoids the need to provision and autoscale EC2 instances in the ECS cluster. Each ECS Task processes exactly one bag file. We use Elastic FileStore to provide virtually unlimited file storage to the container, in order to easily work with larger bag files. The container uses the open-source bagpy python library to extract structured topic data (for example, GPS, detections, inertial measurement data,). The topic data is uploaded as parquet files to S3, partitioned by topic and source bag file. The application writes metadata about each file, such as the topic names found in the file and the number of messages per topic, to a DynamoDB table (Figure 1 – #4).
This module deploys an AWS Glue Crawler configured to crawl this bucket of topic parquet files. These files populate the AWS Glue Catalog with the schemas of each topic table and make this data accessible in Athena, Glue jobs, Quicksight, and Spark on EMR. We use the AWS Glue Catalog (Figure 1 – #5) as a permanent Hive Metastore.
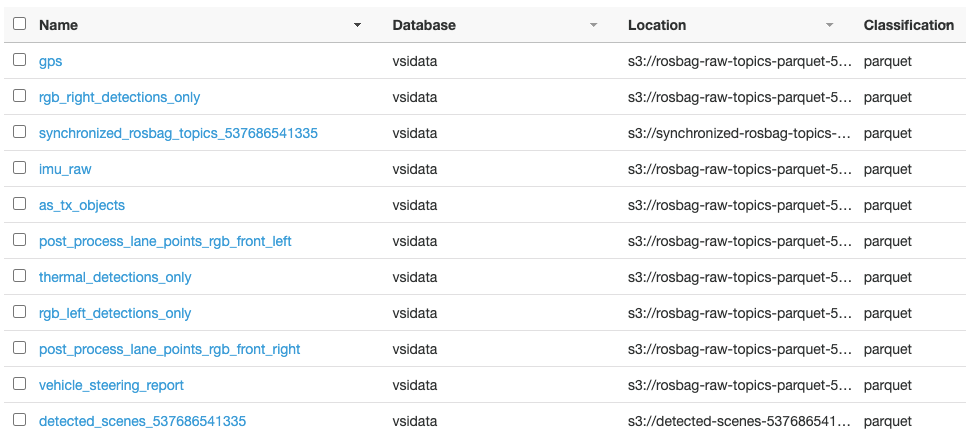
Figure 2 – Glue Data Catalog of parquet datasets on S3
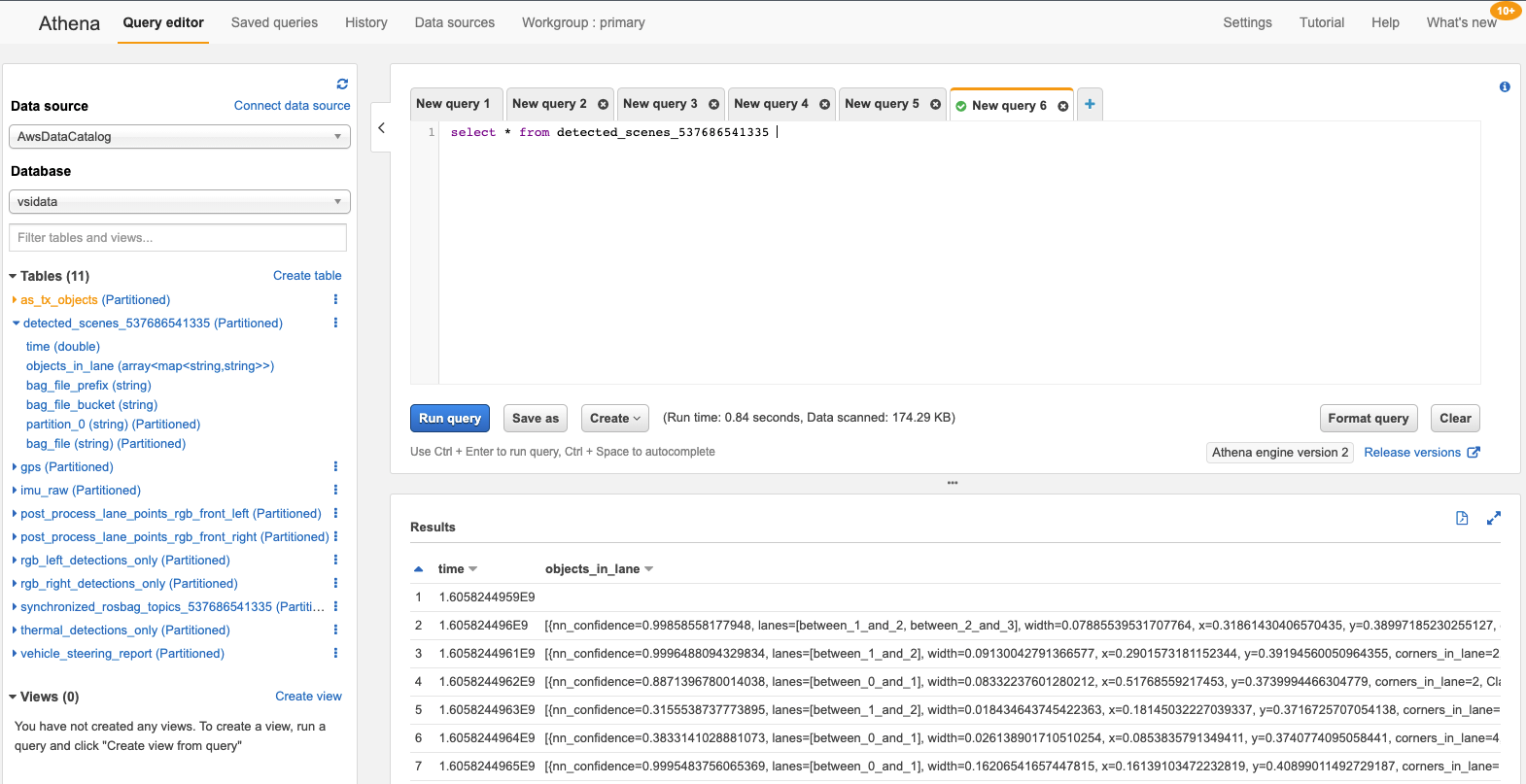
Figure 3 – Run ad-hoc queries against the Glue tables using Amazon Athena
The topic parquet bucket also has an S3 Notification configured for all newly created objects, which is consumed by an EMR-Trigger Lambda (Figure 1 – #5). This Lambda function is responsible for keeping track of bag files and their respective parquet files in DynamoDB (Figure 1 – #6). Once in DynamoDB, bag files are assigned to batches, initiating the EMR batch processing step function. Metadata is stored about each batch including the step function execution ARN in DynamoDB.
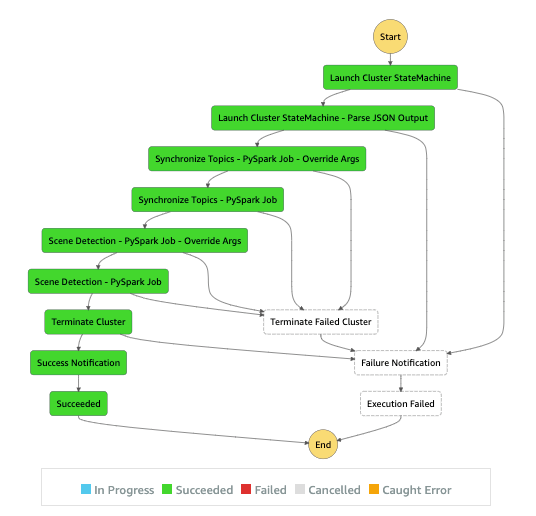
Figure 4 – EMR pipeline orchestration with AWS Step Functions
The EMR batch processing step function (Figure 1 – #7) orchestrates the entire EMR pipeline, from provisioning an EMR cluster using the open-source EMR-Launch CDK library to submitting Pyspark steps to the cluster, to terminating the cluster and handling failures.
Batch Scene Analytics with Spark on EMR
There are two PySpark applications running on our cluster. The first performs synchronization of ROS bag topics for each bagfile. As the various sensors in the vehicle have different frequencies, we synchronize the various frequencies to a uniform frequency of 1 signal per 100 ms per sensor. This makes it easier to work with the data.
We compute the minimum and maximum timestamp in each bag file, and construct a unified timeline. For each 100 ms we take the most recent signal per sensor and assign it to the 100 ms timestamp. After this is performed, the data looks more like a normal relational table and is easier to query and analyze.
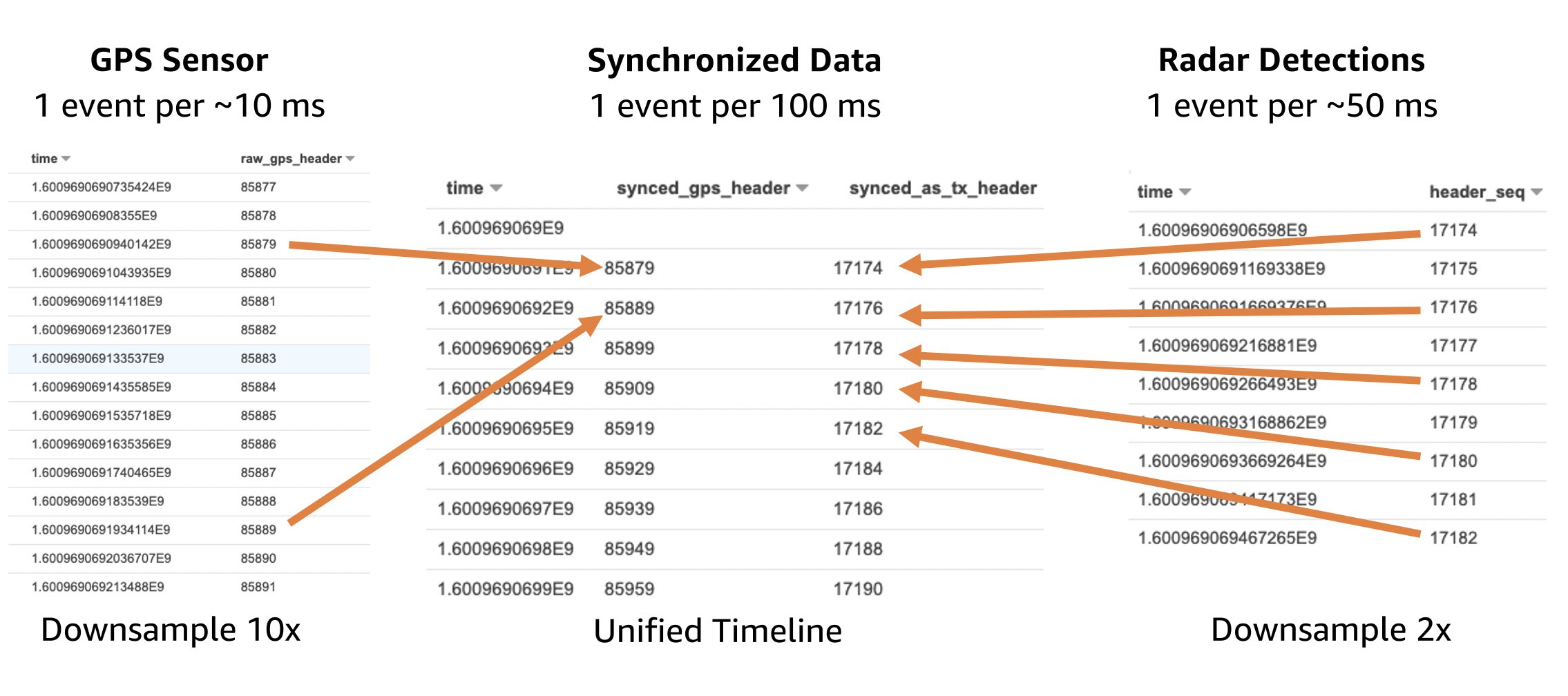
Figure 5 – Batch Scene Analytics with Spark on EMR
Scene Detection and Labeling in PySpark
The second spark application enriches the synchronized topic dataset (Figure 1 – #8), analyzing the detected lane points and the object detections. The goal is to perform a simple lane assignment algorithm for objects detected by the on-board ML models and to save this enriched dataset (Figure 1 – #9) back to S3 for easy-access by analysts and data scientists.

Figure 9 – Object Lane Assignment example
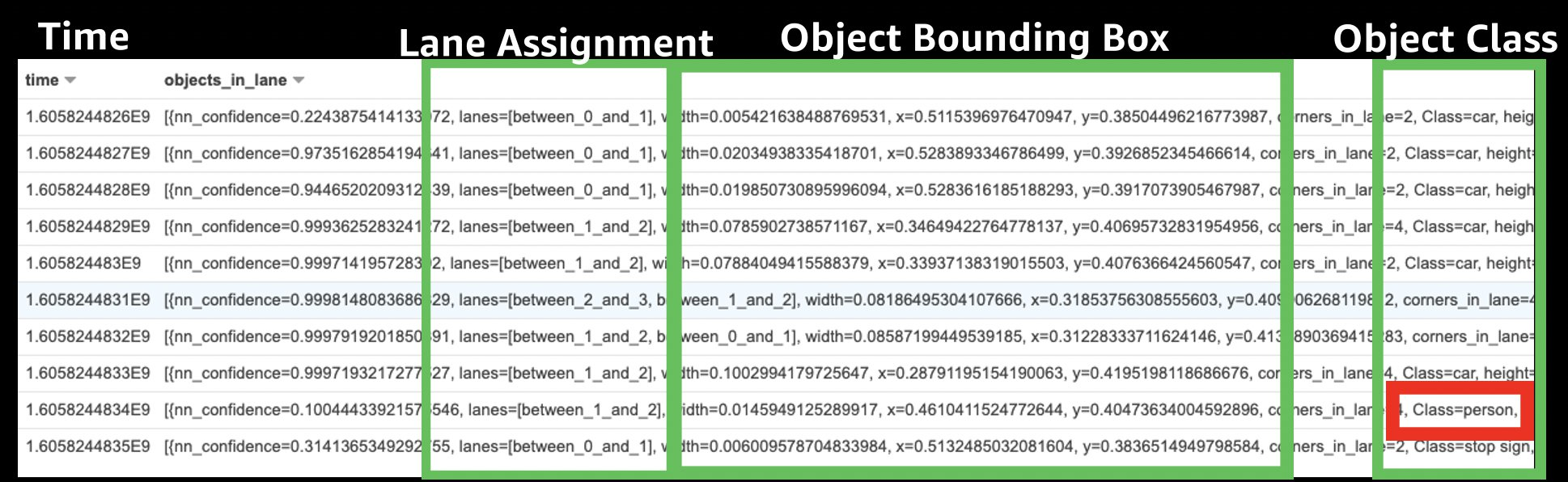
Figure 9 – Synchronized topics enriched with object lane assignments
Finally, the last step takes this enriched dataset (Figure 1 – #9) to summarize specific scenes or sequences where a person was identified as being in a lane. The output of this pipeline includes two new tables as parquet files on S3 – the synchronized topic dataset (Figure 1 – #8) and the synchronized topic dataset enriched with object lane assignments (Figure 1 – #9), as well as a DynamoDB table with scene metadata for all person-in-lane scenarios (Figure 1 – #10).
Scene Metadata
The Scene Metadata DynamoDB table (Figure 1 – #10) can be queried directly to find sequences of events, as will be covered in a follow up post for visually debugging scene detection algorithms using WebViz/RViz. Using WebViz, we were able to detect that the on-board object detection model labels Crosswalks and Walking Signs as “person” even when a person is not crossing the street, for example:

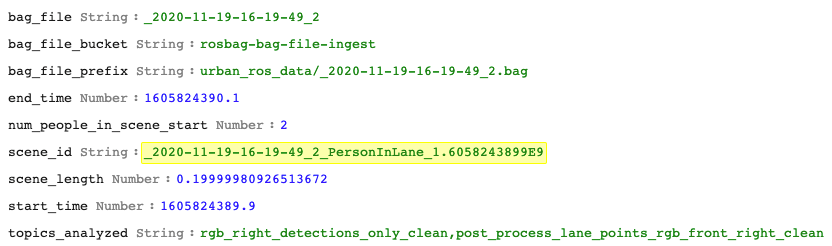
Figure 10 – Example DynamoDB item from the Scene Metadata table
These scene descriptions can also be converted to Open Scenario format and pushed to an ElasticSearch cluster to support more complex scenario-based searches. For example, downstream simulation use cases or for visualization in QuickSight. An example of syncing DynamoDB tables to ElasticSearch using DynamoDB streams and Lambda can be found here (https://thinkwithwp.com/blogs/compute/indexing-amazon-dynamodb-content-with-amazon-elasticsearch-service-using-aws-lambda/). As DynamoDB is a NoSQL data store, we can enrich the Scene Metadata table with scene parameters. For example, we can identify the maximum or minimum speed of the car during the identified event sequence, without worrying about breaking schema changes. It is also straightforward to save a dataframe from PySpark to DynamoDB using open-source libraries.
As a final note, the modules are built to be exactly that, modular. The three modules that are easily isolated are:
- the ECS Task pipeline for extracting ROS bag topic data to parquet files
- the EMR Trigger Lambda for tracking incoming files, creating batches, and initiating a batch processing step function
- the EMR Pipeline for running PySpark applications leveraging Step Functions and EMR Launch
Clean Up
To clean up the deployment, you can run bash deploy.sh destroy false. Some resources like S3 buckets and DynamoDB tables may have to be manually emptied and deleted via the console to be fully removed.
Limitations
The bagpy library used in this pipeline does not yet support complex or non-structured data types like images or LIDAR data. Therefore its usage is limited to data that can be stored in a tabular csv format before being converted to parquet.
Conclusion
In this post, we showed how to build an end-to-end Scene Detection pipeline at scale on AWS to perform scene analytics and scenario detection with Spark on EMR from raw vehicle sensor data. In a subsequent blog post, we will cover how how to extract and catalog images from ROS bag files, create a labelling job with SageMaker GroundTruth and then train a Machine Learning Model to detect cars.
Recommended Reading: Field Notes: Building an Autonomous Driving and ADAS Data Lake on AWS