AWS Open Source Blog
Disaster Recovery When Using Crossplane for Infrastructure Provisioning on AWS
We would like to acknowledge the help and support Vikram Sethi, Isaac Mosquera, and Carlos Santana provided to make this blog post better. Thank you!
In our previous blog posts [1,2,3], we have discussed a growing trend towards our customers adopting GitOps and Kubernetes native tooling to provision infrastructure resources. AWS customers are choosing open source tools such as Argo CD and Flux CD for rollout and Crossplane or Amazon Controllers for Kubernetes (ACK) for creating infrastructure resources.
In our conversation with some of our customers and partners, including Autodesk, Deutsche Kreditbank, Nike, and Upbound, we identified that, while there is a significant body of work at AWS on how to utilize multi-region and multiple availability zone (multi-AZ) architectures to enable disaster recovery (DR), DR in the context of GitOps and Kubernetes-native infrastructure rollout has not been explored as extensively. To address this issue and to bring attention to some of the key considerations, we’ve worked with engineers and architects from these companies to come up with failure scenarios and related solutions when managing AWS resources with Crossplane.
In this blog post, we discuss different backup considerations when employing GitOps and the use of Kubernetes-native infrastructure provisioning tools on Amazon Elastic Kubernetes Service (Amazon EKS). To provide Kubernetes clusters with capabilities to backup and recover Kubernetes objects, we use Velero. Velero is a popular open source solution which allows you to backup and restore Kubernetes objects to external storage backends such as Amazon Simple Storage Service (Amazon S3). For brevity, in this writing we focus on using Velero for DR when using Crossplane as the infrastructure provisioning tool, but the approach should be equally applicable to ACK as well. In particular, we will answer questions related to the following scenarios:
- What should you do if the Kubernetes control plane fails and a new cluster needs to be brought up to manage AWS resources?
- How can you bring AWS resources into another region when using Crossplane?
- What should you do if one of the resources managed by Crossplane fails?
In this post, we will not go into the details of how to configure individual AWS services to guard against failures. If you are interested in learning more about disaster recovery strategies for specific AWS services, please refer to strategies and documentation available at AWS Elastic Disaster Recovery.
Managed Entities and Failure Scenarios
Crossplane makes use of the Kubernetes Resource Model (KRM) to represent the resources it manages as instances of Custom Resource Definitions (CRDs). These custom resource instances are held within the same Kubernetes Cluster as the Crossplane Controllers.
For example, to create an Amazon S3 bucket, you should deploy a Crossplane CRD of type Bucket to the cluster and also a corresponding Kubernetes object with the kind Bucket that instantiates the CRD and represents the underlying Amazon S3 Bucket resource. Therefore, for any infrastructure resource managed by Crossplane, there are two separate but interrelated entities that you need to look into when doing backups:
- The underlying AWS resource, e.g. for the bucket discussed above, you must have a plan in place to back up its content.
- The corresponding Kubernetes object and its managing Amazon EKS cluster that keep the actual state of the AWS resource in sync with its expected state as deployed to the Kubernetes cluster. This object is called the Managed Resource (MR).

In addition, it is possible to group multiple MRs into one Kubernetes object. Such objects are called Composite Resources (CRs) and they are responsible for gluing sub resources together and are defined by Composition and Composite Resource Definition objects. CRs can also include other CRs as one of their sub resources. Furthermore, it is possible to create CRs that contain MRs from different providers. For example, it is possible to create CRs which contain MRs from AWS and Helm providers.
Therefore, it is critical for these objects to maintain their relationships with other objects when restoring them from backups.
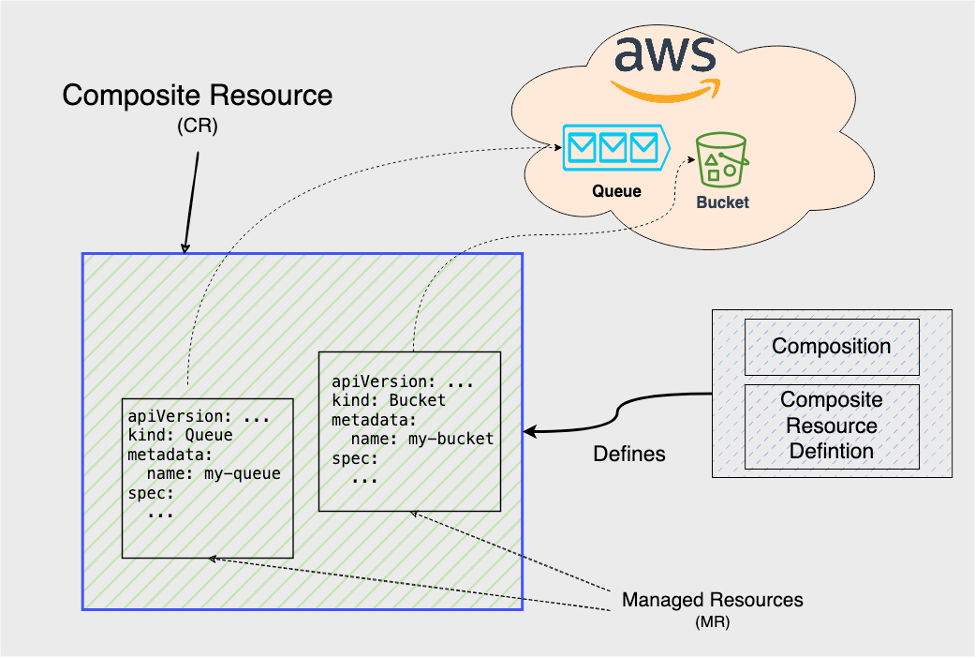
In this blog post we particularly focus on failure recovery scenarios for the managing Kubernetes cluster, the Crossplane controller that runs in this cluster, and the individual Kubernetes resources representing infrastructure resources. For the AWS infrastructure resource managed by Crossplane, we discuss the traditional disaster recovery scenario where a region becomes completely unavailable.
Scenario 1: Kubernetes Cluster Failure
For the first scenario we are going to look into cases where the managing cluster running the Crossplane controller unexpectedly fails and the management cluster is disconnected from the actual infrastructure resources it manages. While this does not impact the data plane (e.g., your Amazon S3 bucket from the earlier example will continue to operate as it used to), it prevents any change to the infrastructure resources via the management cluster.
A common mechanism to recover from a failed cluster is to copy the state of the failed cluster into a new and healthy cluster. This can be done by regularly backing up the Kubernetes etcd datastore of an existing cluster, so that it can be restored into a new cluster if things fail. While there are several solutions for backing up resources in Kubernetes, Velero is one of the more popular ones. Velero allows you to safely backup and restore Kubernetes objects. This can be done for the entire set of resources, or it can be done selectively and by using Kubernetes resource and label selectors. The following figure depicts how an Amazon RDS resource provisioned by Crossplane in a now failed cluster (left) can be restored and managed by Velero into a new cluster with an existing Crossplane controller (right).
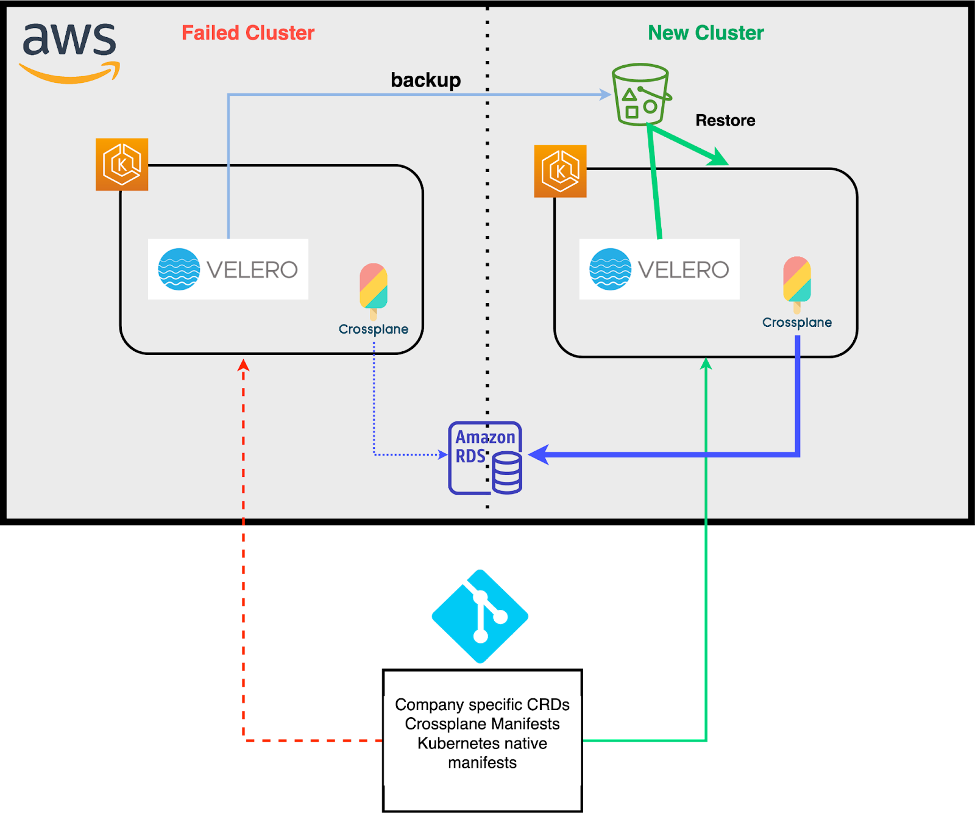
As part of the recovery process, it is important to ensure that Kubernetes resources restored by Velero get into a stable state when reconciled by the Crossplane controller on the healthy cluster. For example, consider a scenario where Crossplane resources are backed up from a Kubernetes cluster which has an older version of Crossplane’s AWS provider. When Velero restores these resources into a new Kubernetes cluster which has a newer version of Crossplane’s AWS providers, Velero replicates the same old copy of the resource in the new cluster. If for arbitrary reasons (e.g. regressions, bugs, etc.) the new Crossplane AWS provider acts on the restored resources differently than the old provider, then Velero and the new Crossplane AWS provider may get into a race overriding the state of the resource on the cluster, in which case the external resource could end up flapping between a desired state and a non-desired state, hence not becoming fully stable.
Similarly, if the manifests representing your Crossplane resources are applied to your Kubernetes cluster using GitOps or similar automation, you should make sure to disable it before restoring the backup. Otherwise, once your backup is restored, any Kubernetes resources it contains could be overwritten by their representations from git. This could cause your restore to become inconsistent or worse, you could introduce skew with the underlying cloud provider resources. By disabling your GitOps workflows or any automation delivering your Crossplane manifests, you can ensure that the only manifests applied are those restored from backup.
When backups are made with Velero, they should contain objects managed by Crossplane and its providers, including composite resources, their sub resources, and managed resources. For a successful recovery, it is important for backed up objects to include all the dependencies. This includes, e.g., ProviderConfig objects and corresponding secrets. ProviderConfig objects are responsible for providing configuration including credentials for providers to connect to service providers such as AWS. Without importing the full chain of object dependencies, migrated crossplane resources have no way of getting reconciled correctly. In addition, to ensure resources are in-sync with Git, they need to be imported into your GitOps tooling. This is specific to the GitOps tooling used, which can become complex to manage. We intend to cover the intricacies of synchronizing restored resources and the corresponding Git counterparts in another blog post.
In general, a regular backup process before a cluster failure involves the following steps:
- Scale down the AWS provider deployment to zero to prevent this instance of the provider from attempting to reconcile AWS resources.
- Back up the required resources.
- Repeat at a reasonable interval.
When restoring into a new cluster:
- Install Velero and configure it to use the backup data source.
- Ensure your AWS Auth ConfigMap setup does not get overwritten by Velero after you initiate the restore process, or else you will lose access to the new cluster.
- Restore the backed up resources to the new cluster.
- Scale up the AWS provider deployment to one in the new cluster.
During the backup and restoration process Velero preserves owner references, resource states, and external names of managed resources. Therefore from here on, the Kubernetes reconciliation process should kick in and proceed as if there were no changes.
Scenario 2: Failure in Crossplane Controller Upgrades
Upgrading the Crossplane controller for a given provider should not require treating failures as a full case of disaster recovery. When you install a new version of a provider, a ProviderRevision object is created that owns the new version of managed resources and transfers ownership from the old providers. In case the new revision of the provider fails, recovery should be as easy as rolling back to the old revision of the provider where ownership of the previous revision is reinstated.
However, it could be that due to other complications (see here for an example), a rollback from a failed provider upgrade would not help with recovering from a failure. In this case, a full cluster migration might be the fastest solution to bring things back on track.
In case of cluster migration, you can safely use Velero, similar to how it was discussed previously to back up resources and restore them to a new cluster. The new cluster does not need to be in the same region either, since the region in which managed AWS resources reside does not change. An example of such a migration can be found here.
Scenario 3: Region Impairment
Region impairment results in more complex scenarios to recover from, given how Kubernetes objects are connected to external AWS service entities.
For example, you may have an EKS cluster with Crossplane in the us-west-2 region. Let us assume that this cluster manages AWS resources in us-west-2 and us-east-1 regions. If it happens that connectivity to the us-west-2 region is impaired and you need to migrate resources to another region, you need to carefully assess your recovery strategy.
You may have a Velero backup of objects from the managing Crossplane cluster in us-west-2 and you can restore them for Global AWS resources such as Route53 records and IAM roles, but you cannot simply restore regional resources to the new cluster in a different region. One reason for this is that all resources managed by the Crossplane AWS provider have “region” as a required configuration field (see the below Amazon Virtual Private Cloud (Amazon VPC) instance for example).

This field determines in which region Crossplane-managed AWS resources should be deployed. When you take a backup of the managed resources in the original cluster, these objects have the region specified in the resources. In our example, these resources may have the us-west-2 or us-east-1 region specified. Because of this, when you attempt to restore them into another cluster in another region, Crossplane will attempt to provision resources into the region that no longer exists. You will need to update your Kubernetes manifests to reflect region changes. Also, your stateful resources such as databases likely need to be restored from a snapshot. You may also have a hot replica in another region that your application can use. In either case, during the restoration process you still need a way to tell Crossplane which backup you want to restore from and update applications to point to the new database, preferably in an automated way.
You will also need to consider AWS regional differences and ensure compositions work in different regions. For example, the us-west-2 region has 4 availability zones, while the us-east-1 region has 6 availability zones. To accommodate this, you may need to create different compositions for each region to ensure availability requirements are met.
Because of these reasons, it’s likely you need to change manifests in your source of truth or use a mutation webhook to dynamically update the region field, instead of relying on a Kubernetes backup solution. You need to perform the restoration process using the continuous delivery (CD) tool of your choice. A rough process is depicted in the figure below and would look like this:
- Create a new Kubernetes cluster with Crossplane in another region if one doesn’t exist.
- Determine which region you want to restore to.
- Determine which snapshots you want to restore from.
- Make changes to your manifests to reflect information determined in the previous steps (preferably with automation such as a mutating webhook).
- Let your CD tooling deploy resources.

Key Considerations
Based on the discussions here, we highly recommend that you start designing to guard against failure from the ground up to ensure uninterrupted operation of your applications.
In order to have a less hectic recovery process, here are some additional key considerations:
- Automate the rollout of your infrastructure and application resources. This ensures that when disaster hits, you can more quickly respond by redirecting your rollout practices to an alternative solution.
- Parameterize your deployments. Make regions, availability zones, instance types, replica counts, etc. configurable so you can change them to alternatives where necessary. This, combined with proper automation, allows you to quickly choose alternative targets for deploying infrastructure and application resources.
- Make sure you can tag and specify which snapshot you want to restore for your backed up data stores. In Crossplane compositions, this can and needs to be defined when you are restoring your data into a new managing cluster.
- Consider full migrations to alternative regions as a last resort. Failures happen a lot less frequently to an entire region. When recovering from failures, consider rollback options available natively by Crossplane. This involves rolling back to an older revision of the provider, or restoring a failed AWS service instance to remain in sync with the Crossplane counterpart.
- Do not ignore full migrations to alternative regions. While rare, you would occasionally need to do a full migration to an entirely different region. Have it be part of your recovery planning. Do not ignore or postpone it!
- Practice failure recovery scenarios a priori. We have seen examples like Chaos Monkey and other tools imitating a case of failure for deployments in order to prepare and practice a recovery process. Crossplane is no different. Ensure you practice failure recovery frequently to be prepared for an actual case of recovery when needed.
Conclusions
Managing AWS resources using a Kubernetes control plane has its own challenges when you need strategies to backup and restore resources. If you are simply migrating from one managing cluster to another, backup solutions such as Velero work nicely because no modifications to the source of truth are required.
If you are preparing for disaster recovery scenarios, things are more nuanced and may require modifications to your source of truth. Many AWS managed services offer easy ways to backup and restore your data to another region. Your Crossplane compositions need to be able to take advantage of these features according to your recovery objectives. Using templating and overlaying mechanisms, you can easily embed these objectives into Crossplane compositions. This means all AWS resources managed by Crossplane adhere to your recovery point objective. In the end, it is important to understand where you draw boundaries in your recovery process in what is possible via Kubernetes tooling and the control plane, and what needs to be taken care of out of band and using traditional failure recovery practices.
If you want to learn more about building shared services platforms (SSP) on EKS with Crossplane, you can schedule time with our experts.
References:
- https://thinkwithwp.com/blogs/opensource/comparing-aws-cloud-development-kit-and-aws-controllers-for-kubernetes/
- https://thinkwithwp.com/blogs/opensource/declarative-provisioning-of-aws-resources-with-spinnaker-and-crossplane/
- https://thinkwithwp.com/blogs/opensource/introducing-aws-blueprints-for-crossplane/