Front-End Web & Mobile
Query Heterogeneous Data Sources through AWS AppSync GraphQL APIs
AWS AppSync and Amazon API Gateway are managed API services designed to provide a unified endpoint enabling front end clients to access resources stored in various data sources. This article underscores the advantages of employing AppSync as the API solution for external clients to access your data sources via GraphQL.
Introduction
GraphQL, an API protocol, empowers the client to make precise requests while preserving access control on the server side. AppSync offers managed integrations for common use cases such as Amazon DynamoDB, Amazon OpenSearch, Amazon Aurora, AWS Lambda, Amazon EventBridge and HTTP resolvers. To configure data sources beyond these natively supported use cases, you can use Lambda as a proxy and implement integration logic yourself. This article will present architectural patterns and best practices for integrating an AppSync GraphQL API with heterogeneous data sources (such as static, compressed object storage, internal services, and external APIs) for querying purposes.
Do I need a REST or GraphQL API?
API Gateway, a serverless service managed by AWS, provides API management as a means for accessing proprietary Business Logic and Data. The most popular protocol used in API Gateway APIs is the Representational State Transfer (REST) protocol, which was introduced more than two decades ago. REST organizes multiple data types and processes by URL path into “Resources” (hence the phrase Uniform Resource Identifier (URI)) upon which clients can perform HTTP / HTTPS Request Methods (GET, PUT, POST, DELETE, etc) to perform their desired intent.
A drawback of the REST protocol occurs when API calls return data uniformly per URI. When invoking a REST API, the response generally includes all attributes of the data model (a pre-defined data structure). A model could signify any entity in an application, and generally are coupled with the underlying Database Schema. When querying a resource and providing the entire model in response, the client may receive more data fields than they need. Additionally, RESTful API Resources are invoked independently, which results in multiple HTTP/S requests when the client needs data spanning multiple resources. This “overfetching” and “underfetching” of data is self-evident when investigating the number of API invocations per page load and identifying the data attributes on the data models that go unused in the client application.
When managing a full stack infrastructure, the goal is to efficiently integrate front-end clients with backend resources through an API. GraphQL is a protocol that solves the over and under-fetching challenge, by enabling front-end clients to explicitly specify which models/fields are relevant for a specific action (Query/Mutation/Subscription) before the API responds. AWS AppSync is a managed, serverless GraphQL offering that can both improve performance and costs (infrastructure & management) compared to self-hosting a GraphQL API Server. At the API Layer, you model all the data types, their relationships, and actions you can perform in a GraphQL Schema, and then AppSync becomes the integration hub that connects front-end clients to disparate backend services.
This blog post demonstrates how to query heterogeneous secure data sources while solving for over/under fetching in a hypothetical scenario with fictitious data. The advanced relationship capabilities of GraphQL implementation are beyond the scope of this post.
Scenario
This article presents a fictitious scenario to illustrate solution architecture patterns for a GraphQL API and its resolvers.
As a fullstack developer for a historical weather application, you enable users to retrieve historical weather records through an API and then present the data queried on the client-side. The current architecture diagram is presented below. Your Weather Records database table is populated through an ETL (Extract, Transform, Load) process where you retrieve data from an external weather API provider, converting units from metric (C, km/h) to imperial (F, mph), then store the transformed records into your data store (DynamoDB).
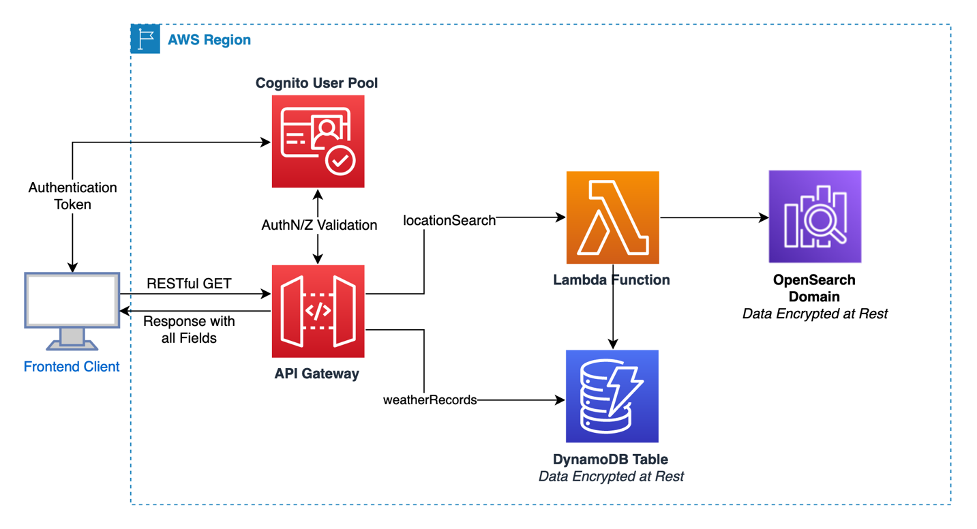
Scenario: An API serves weather data through a RESTful format
The current API Gateway endpoints have the following RESTful structure:
- GET
<api gateway>/locationsearch?text_input=Austin+Texas+78705
returns{city, state, zip, locationId, longitude, latitude} - GET
<api gateway>/weatherrecords/<locationId>?year=2023&month=06&day=01&hour=12
returns{locationId, YYYY#MM#DD#HH, temperature, humidity, wind speed, ...}
The DynamoDB Table was designed to use LocationID as the Partition Key, and DateHour (YYYY#MM#DD#HH) as the Sort Key. Efficient queries from DynamoDB to retrieve Hourly Weather Records for adjacent records per partition are easy through this design. The use of OpenSearch enables users to input Free Form Text in a search, instead of knowing the actual locationId before submitting a weather history query.
In the current design, users can retrieve data through API Gateway, but your research has proven that users want more flexibility when searching for non-adjacent Weather Records (e.g. they want to know the temperature at midnight each day in a month for one location). To provide this capability with your API Gateway Design, multiple REST calls are required, and users receive an excess of data fields they do not need (e.g. wind, humidity). Additionally, a colleague has just completed a beta release of a weather forecasting service that they host in Amazon EC2 with private-only networking.
Given these changes, you must now determine if it’s logical to rearchitect and adopt GraphQL as your API Protocol.
Upon profiling the data, it’s clear that it is static (unchanging), can be aggregated and compressed, and requires minimal transformations during ETL from your external data source provider (simple unit conversion). Additionally, users frequently need only a subset of the weather records’ data fields.
To ensure the security of your data, all user data stored in DynamoDB is automatically encrypted at rest and you can choose the type of encryption key to encrypt your table. To ensure the security of your API, you have configured an Amazon Cognito User Pool for authenticating clients and governing who can access your API Gateway API.
Solution Architectures
With GraphQL, you have significant flexibility for rearchitecting the backend implementation without exposing that complexity to your clients. Each solution architecture outlined below addresses a single component of the above scenario for simplicity. The flexibility of AppSync enables a combination of these backend architectures into a single GraphQL API endpoint, fostering a flexible, robust API that connects disparate data sources while maintaining consistent API integration for front-end developers.
Architecture 1: Move the Static Data into Amazon S3 and Encrypt
Given that historical weather data is static and unchanging, a significant reduction in data storage costs could be achieved by moving this data to Amazon S3. Comparing raw storage costs in the N. Virginia AWS region, DynamoDB charges $.25/GB whereas S3 charges $.023/GB for standard tier storage, potentially leading to a reduction of more than 90% in data archive storage costs. As depicted in the diagram below, S3 can replace the use of DynamoDB for data persistence. Additionally, you can leverage S3 lifecycle policies to allow older, infrequently accessed weather records to transition to more cost-efficient storage classes while still maintaining their availability. Both S3 and DynamoDB offer encryption at rest. Any new objects uploaded to S3 will automatically be encrypted with S3 server-side encryption. You can also specify a different default encryption key behavior if desired.
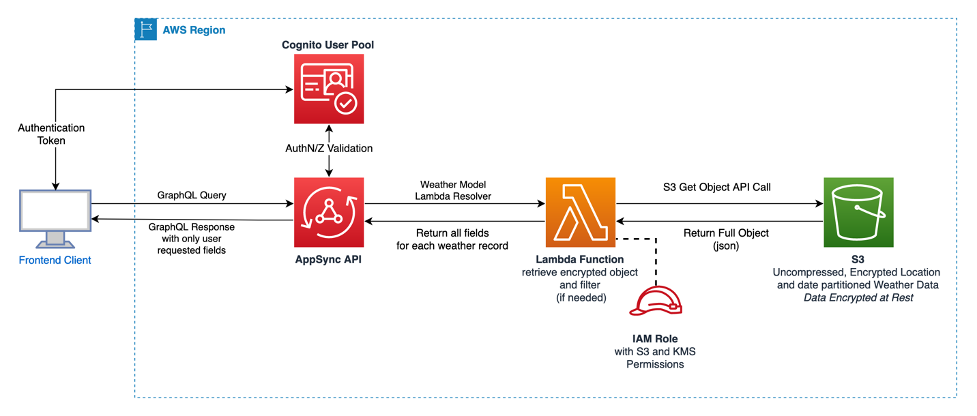
Architecture 1: Diagram illustrating how to return static data from S3 via AppSync. Users are authorized via Cognito User Pools.
The weather records are uniquely identified by a combination of locationId, date, and hour. This makes it convenient to partition the DyanmoDB weather data using S3 Prefixing in the key name. You can store the data following this S3 URI scheme, which partitions based on Date, and each S3 JSON object would contain 24 hourly records.
S3://<bucket>/weatherrecords/<locationId>/<YYYY</<MM>/<DD>.json
This setup offers the flexibility to add new features, like allowing users to request sunrise and sunset hourly temperature records (6:00 AM and 7:00 PM for instance). With GraphQL, you can fetch all of the required data in a single API call, thereby addressing the over-fetching and under-fetching problems associated with the RESTful API. The following pseudocode illustrates how you can implement this.
# GraphQL Schema
type hourlyWeatherRecord {
locationId: String!
year: String!
month: String!
day: String!
hour: String!
temperature: Float!
humidity: Float!
windSpeed: Float!
}
type Query {
listLocationWeatherRecordsByDay(locationId: string!, year: string!, month: string!, day: string!) : [hourlyWeatherRecord]
listLocationWeatherRecordsForSpecificHours(locationId: string!, year: string!, month: string!, day: string!, hours: [string!]) : [hourlyWeatherRecord]
}# Query performed by Front-end Client
query getSunriseSunsetWeatherRecordsFor123 {
listLocationWeatherRecordsForSpecificHours(locationId: “123”, year: “2023”, month: “06”, day: “01”, hours: [“06”, “19”]) {
items {
hour
temperature
}
}
}In this context, the role of the Lambda function as a resolver for these queries is to fetch the necessary data from S3 and select the relevant records. The function does not need to filter the fields within the model itself, such as isolating just the temperature values. This is because AppSync/GraphQL allows clients to specify precisely which fields they require in the response, as previously discussed.
Architecture 2: Aggregate and Compress the Static Data into S3
In this solution architecture, the aim is to benefit from compression while migrating data from DynamoDB to S3. Unlike Architecture 1, which straightforwardly moves data between environments, Architecture 2 leverages the infrequent access pattern of historical data to aggregate the data. By consolidating data into fewer, larger partitions and compressing objects before moving them to S3, storage costs can be minimized. When an API is invoked, Lambda can decompress the necessary files as needed.
DynamoDB weather data records can be grouped into monthly partitions utilizing S3 Prefixing in the Key name. The subsequent data can then be stored following this S3 URI scheme:
s3://<bucket>/compressedweatherrecords/<locationId>/<YYYY>/<MM>.json.gz
Assuming this S3 bucket is populated each month after a partition becomes full, each S3 JSON object would contain 24 hourly records times the number of days in that month (28-31). Given the larger size of these monthly partitions (especially for data containing numerous fields), compressing the .json files using a method such as gzip can reduce the storage size.
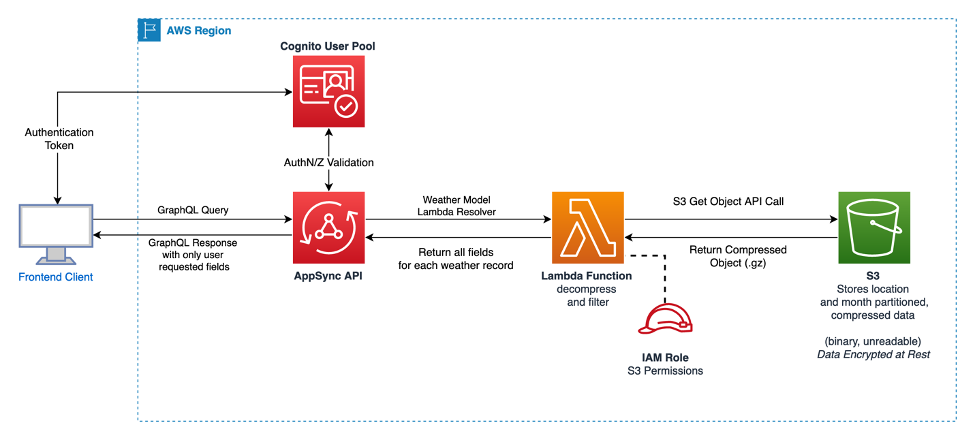
Architecture 2: Diagram illustrating how to return static compressed data from S3 via AppSync.
The schema doesn’t require modification; however, the Lambda Resolver logic should be adjusted so it identifies which S3 Objects to fetch and decompress upon invocation. A new query can be added to the schema, enabling users to retrieve specific hours from an entire month’s worth of data. In this scenario, all records in S3 are compressed and partitioned by month.
Suppose a user is interested in querying the hourly humidity levels at noon for each day of a specific month. With GraphQL, the exact needed data can be retrieved in a single API call, thus resolving the over-fetching or under-fetching issue typical with RESTful APIs. The provided pseudocode offers an example of how this can be implemented:
# GraphQL Schema
# previous hourlyWeatherRecord data model
type hourlyWeatherRecord {
locationId: String!
year: String!
month: String!
day: String!
hour: String!
temperature: Float!
humidity: Float!
windSpeed: Float!
}
type Query {
# previous query options
listLocationWeatherRecordsByDay(locationId: string!, year: string!, month: string!, day: string!) : [hourlyWeatherRecord]
listLocationWeatherRecordsForSpecificHours(locationId: string!, year: string!, month: string!, day: string!, hours: [string!]) : [hourlyWeatherRecord]
# new Query option; can use the same Lambda Resolver function
listLocationWeatherRecordsByMonthForSpecificHours(locationId: string!, year: string!, month: string!, hours: [string!]) : [hourlyWeatherRecord]
}# Query performed by Front-end Client
query getNoonWeatherRecordsFor123 {
listLocationWeatherRecordsByMonthForSpecificHours(locationId: “123”, year: “2023”, month: “06”, hours: [“12”]) {
items {
day
humidity
}
}
}The role of the Lambda Function resolver in these Queries is to extract the necessary data from S3 and select the pertinent records. However, it should be noted that Lambda does not undertake the task of filtering the fields on the model — that functionality is handled by AppSync.
An intriguing aspect of this approach is that the Lambda Event carries details about the AppSync Query Invocation, such as the running query and the parameters supplied by the client. This data informs the logic regarding the custom backend integration. In this instance, the /compressedweatherrecords prefix in S3 is the target, where all historical weather records are partitioned by month and compressed to conserve storage.
Decompressing on the fly in Lambda offers a simpler, more cost-effective solution when access to historical archive of data is infrequent. It allows access to all data while avoiding the challenge of predicting which locationIds and which historical months will be queried.
Architecture 3: Access New Internal Service
Once the integration (including Authentication/Authorization configuration) between the front-end and the AppSync API is established, it becomes straightforward to incorporate additional backend resolvers and data sources into the existing API. The front-end does not need to be aware of the intricate details of the data source or service provider’s implementation.
As mentioned in the above scenario, a colleague has developed a new beta microservice for weather forecasting in Amazon EC2 using private networking. The goal is to now allow secure and simple invocation of this service in a query/read only fashion. By using the existing AppSync API, this new feature can be integrated without introducing unnecessary complexity. The fact that this microservice utilizes a RESTful API does not pose a concern, as it does not add complexity on the client side.
The Internal Service operates within an Isolated Virtual Private Cloud (VPC) with no Internet access (i.e., no Internet Gateway), relying solely on private Subnets. As such, the Lambda Function will need to be configured as a VPC Lambda Function. This configuration permits it to access the internal subnets. The following diagram illustrates the interrelation of these services, demonstrating how the VPC Lambda Function can access resources within the VPC through its hyperplane elastic network interface (ENI). In this sense, the API is the only “front door” to this proprietary internal service, and caching can be implemented on the API as well if desired.
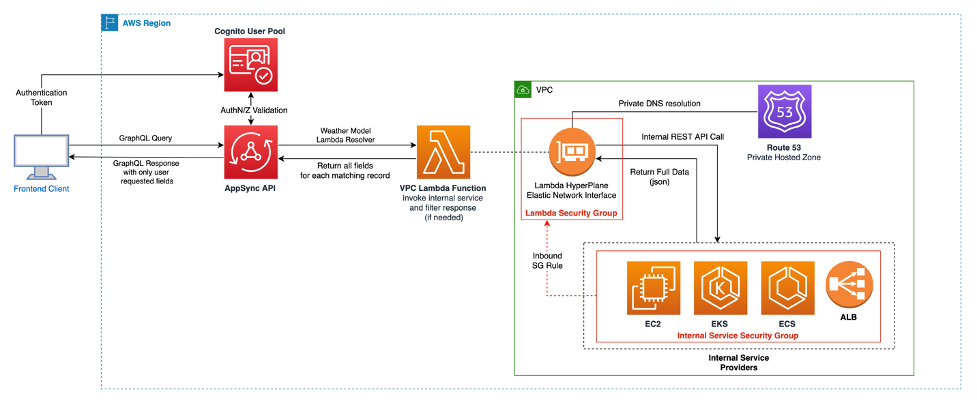
Architecture 3: Diagram illustrating how to retrieve data from an internal service via AppSync.
The AppSync Schema can now accommodate the newly integrated internal forecasting service.
# GraphQL Schema
# previous hourlyWeatherRecord data model
type hourlyWeatherRecord {
locationId: String!
year: String!
month: String!
day: String!
hour: String!
temperature: Float!
humidity: Float!
windSpeed: Float!
}
type Query {
# previous query options
listLocationWeatherRecordsByDay(locationId: string!, year: string!, month: string!, day: string!) : [hourlyWeatherRecord]
listLocationWeatherRecordsForSpecificHours(locationId: string!, year: string!, month: string!, day: string!, hours: [string!]) : [hourlyWeatherRecord]
listLocationWeatherRecordsByMonthForSpecificHours(locationId: string!, year: string!, month: string!, hours: [string!]) : [hourlyWeatherRecord]
# new internal service query option
listForecastedWeatherRecordsForLocation(locationId: string!) : [hourlyWeatherRecord]
}# Query performed by Front-end Client
query listForecastedTemperatureWeatherRecordsFor123 {
listForecastedWeatherRecordsForLocation(locationId: “123”, year: “2023”, month: “06”, hours: [“12”]) {
items {
year
month
day
hour
temperature
}
}
}The role of the Lambda Function resolver in these queries is to fetch the necessary data from the internal service and relay the parameters provided by the client. It’s important to reiterate that there is no need for the Lambda function to filter the fields on the model; all the hourlyWeatherRecord fields/interface are returned by the RESTful Internal Service. Given that this is a VPC Lambda Function, this resolver will be separate from the ones connecting to S3. Because this Lambda function mounts a HyperPlane ENI inside the VPC, it can resolve internal DNS from the Route53 Private Hosted Zone.
Architecture 4: Transform the vendors’ API data structure on the fly
Providing a GraphQL interface that you govern doesn’t necessarily imply that you must host the data being served. The query language can be harnessed to select desired fields and control integration complexity for the backend. In this scenario, the weather data provider utilizes the metric system, but your client expects data in the imperial system.
A new Lambda Function Resolver can be configured with the authorization required to invoke the vendor’s API, then subsequently transform the data to appropriate interfaces the client needs. This approach aids in cost optimization as there’s no need to store the transformed data, eliminating data redundancy. The following outlines the architecture for how these elements might integrate.
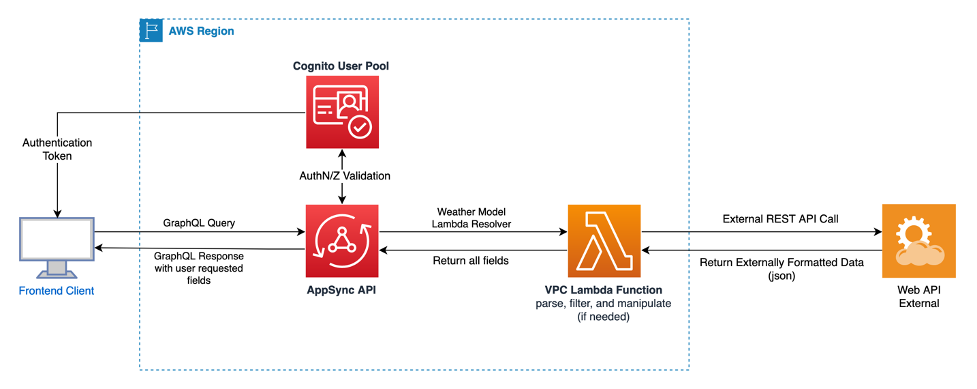
Architecture 4: Diagram illustrating how to transform data returned by AppSync on the fly.
Additional flexibility can be created to accommodate users who request specific fields and filter based on certain identifiers (like records at 12 pm). With GraphQL, precise data can be fetched in a single API call, thereby resolving the over/under-fetching issue in RESTful APIs, all while maintaining control over the interface from the front-end client to the API. The following pseudocode provides an expansion on this concept.
# GraphQL Schema
# previous hourlyWeatherRecord data model
type hourlyWeatherRecord {
locationId: String!
year: String!
month: String!
day: String!
hour: String!
temperature: Float!
humidity: Float!
windSpeed: Float!
}
type Query {
listLocationWeatherRecordsByDay(locationId: string!, year: string!, month: string!, day: string!) : [hourlyWeatherRecord]
listLocationWeatherRecordsForSpecificHours(locationId: string!, year: string!, month: string!, day: string!, hours: [string!]) : [hourlyWeatherRecord]
}If a decision is made to change the API provider, the front-end client won’t need to comprehend how this integration transpires, thereby requiring no updates since all this integration occurs in backend resolvers.
# Query performed by Front-end Client
query getNoonTemperatureRecordsFor123 {
listLocationWeatherRecordsForSpecificHours(locationId: “123”, year: “2023”, month: “06”, day: “01”, hours: ["12"]) {
items {
year
month
day
hour
temperature
}
}
}In this setup, the Lambda Function resolver for these queries fetches the necessary data from the original API Data Source Provider, filters the response to include only the appropriate records, then performs the metric to imperial unit conversion. It’s important to note that the Lambda Function does not filter fields on the model (to return temperature values and not wind values), as this functionality is executed by AppSync.
Conclusion
There are multiple solutions that you can utilize when re-architecting how you provide access to your data and proprietary services. In this blog post, several alternatives to the original design were assessed to improve client query functionality while potentially reducing costs by matching the solution architecture to the data access patterns.
A benefit of leveraging AppSync and GraphQL in the DynamoDB architecture at inception is the persistence layer could have been shifted from DynamoDB to S3 (Solutions 1 & 2) without any knowledge of the frontend client, as the data model’s schema remained the same.
As your evaluate whether to parallel any of the above architectures in your own environment, two essential questions to consider are:
- What degree of query customization do you want to offer your front end developers/users?
- Do users typically request data by numerous patterns? (ex: weather by month/week/day, weather by city, weather by ZIP code, etc.)
- If so, you might use a combination of the above architectures.
- More diverse access patterns add complexity and cost if preprocessing data for all access patterns (architectures 1 and 2)
- Do you expect your users will need new ways to interact with the same data set?
- If so, you might need to add more back-end integrations with storage layers (architectures 1 and 2), compute layers (architecture 3), or proxy layers (architecture 4).
- Do users typically request data by numerous patterns? (ex: weather by month/week/day, weather by city, weather by ZIP code, etc.)
- How much data processing do you want to perform during API invocation?
- If the access pattern is common, it likely makes sense to preprocess the data and optimize the storage layer (architectures 1 and 2).
- When most of your customers want the data presented in a specific format (e.g. Fahrenheit/Imperial)
- If the data access is uncommon, you may want to transform data on the fly during invocation (see architecture 4)
- Preprocessing and Storing data that is not accessed becomes an underutilized investment. Processing instead during invocation would result in Lambda Function Execution costing less than storage costs.
- When a small set of your customers want the data presented in a specific format (Celsius)
- If the access pattern is common, it likely makes sense to preprocess the data and optimize the storage layer (architectures 1 and 2).
In essence, your decision rests on two key pivots: the level of customization you want to offer and how much intermediary handling you find acceptable. As you understand your data access patterns and user requirements, align with the architecture that mirrors the experience you aim to deliver. Remember, the aim is to have a seamless, efficient, and cost-effective solution that serves your business needs while enhancing dev/user experience.
Next Steps
Consider applying these architectural approaches to the workloads you manage. Is there a benefit in having a well-defined GraphQL interface between your front-end clients and your backend API to avoid over/under fetching and create nested relations across data types? If so, AppSync may be a powerful alternative to RESTful APIs to leverage GraphQL functionality.
Please see AppSync Security to learn more about authorization and authentication. Additionally, we recommend you read GraphQL API Security with AWS AppSync and Amplify to learn more about GraphQL governance capabilities. With these security / governance features, you can control which users have permissions to mutate/query specific models or even fields.
To gain hands on experience using GraphQL and AppSync, check out the AWS AppSync Core Workshop. To build a sample application that uses AppSync, check out the AWS Serverless Web Application with AppSync Workshop with sample code.