AWS for M&E Blog
Back to basics: Mechanisms used behind the scenes in video compression
Video encoding
In this blog, we’re going to explain the fundamentals of the video encoding process (compression) in simple terms.
The main purpose of compression/encoding is reducing the volume of data that are needed to capture, store, and transmit video. This leads to reductions in storage hardware, data transmission time, and required delivery bandwidth.
While many different algorithms exist to encode video (such as MPEG-2, H.264/AVC, H.265/HEVC, VP9, AV1, etc), most of the popular codecs in use today follow a common set of principles which are introduced in this blog post.
Joint Photographic Experts Group or JPEG compression
Let’s start with one of the most commonly used algorithms to compress digital images: The Joint Photographic Experts Group, or JPEG compression, which works on a single picture/frame. You may be familiar with the .JPEG (or .JPG) file extension when saving an image file, adding an image to a presentation, or emailing a photo.
Imagine we took a photograph of a scene with a person on a bicycle, with a tree in the background:

JPEG algorithms compress the image by discarding elements that are less noticed by the human eye, such as some colour information (because we aren’t as sensitive to it – changes in brightness are more important for human perception rather than changes in colour) as well as some details in the more complex parts of the picture (low-frequency light changes are more important for us than high-frequency changes).
All data that we remove could potentially influence the quality of the resulting picture depending on the selected compression rate. That’s why JPEG is referred to as a lossy compression method, meaning that some original image information is lost and cannot be restored, possibly affecting image quality.
The appropriate level of compression will depend on the image use case. For example, a still image for online only use can be further compressed than one printed in a large format. When files are overly compressed for the intended application, the image appears pixelated and of poor quality.
For more information, there are many excellent articles on the internet about JPEG compression (see some more detailed materials here). But what is important to understand is that JPEG is an intra-frame coding compression algorithm. Intra means that all the information needed to display that image can be found within itself.
Motion JPEG
Now imagine we record a video of this same scene with the cyclist moving:

The camera actually captures a sequence of still images:

and the JPEG algorithms can be applied to each frame to compress them:

This is called Motion JPEG and it was one of the first widely used video compression techniques. It effectively compresses video by excluding spatial redundancy (more detailed explanation what this is can be found here), but it does not take into account the parts of the image that are common between frames, such as the background, the tree, …:

This common data is called temporal redundancy and can be removed from video to get better compression rates.
Moving Picture Experts Group codecs (MPEG).
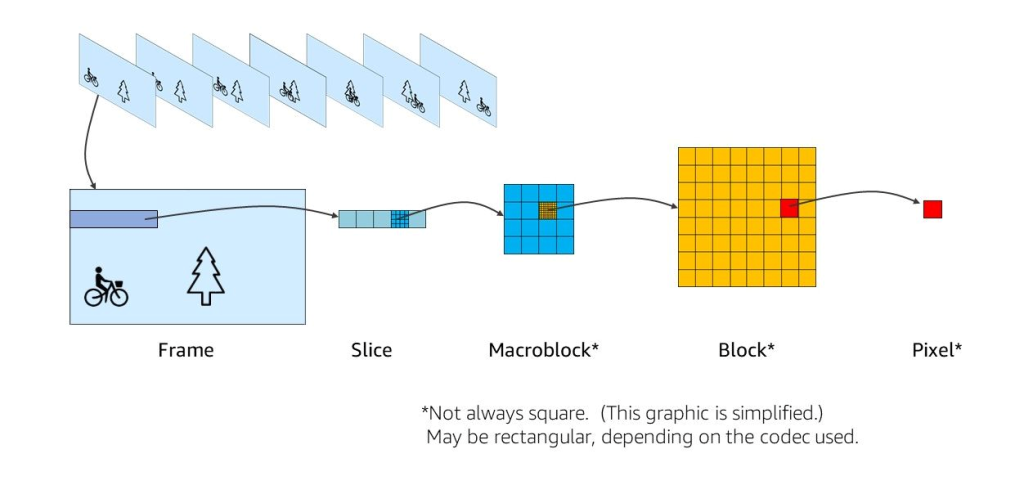
To eliminate temporal redundancy, inter-frame compression techniques were invented (inter meaning between or among). The most popular of these are MPEG. Like JPEG, MPEG encoding is done in basic units called “macroblocks”.
The frame is divided into slices, which are composed of macroblocks. Macroblocks are composed of blocks of pixels, which are the smallest controllable element in an image. Macroblocks are used as a basic object in the video encoding process:
I, B, P frames
Let’s take a high level look at how it works.
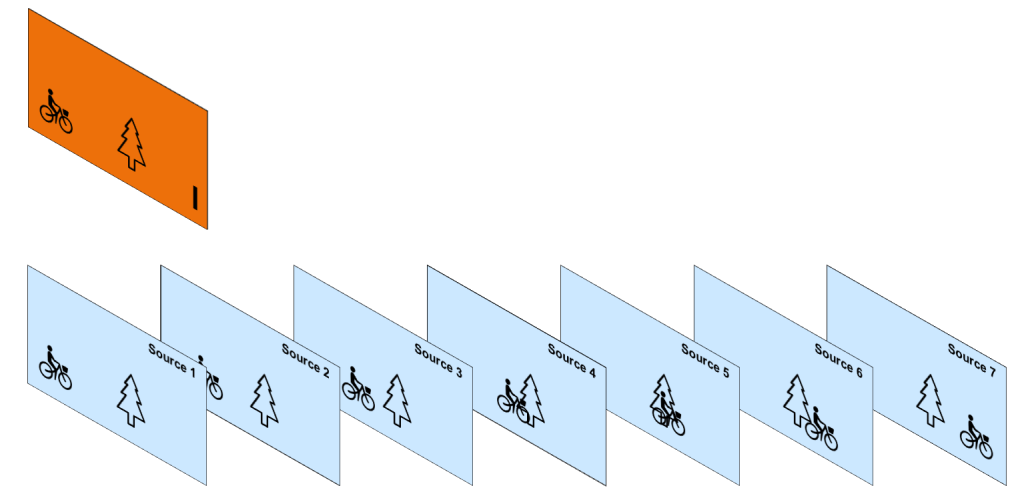
The encoder caches a certain number of frames and applies an intra frame algorithm to the first frame. This frame, denoted as intra-coded frame or information frame (I-frame), is split into macroblocks and then encoded in a JPEG-like manner:
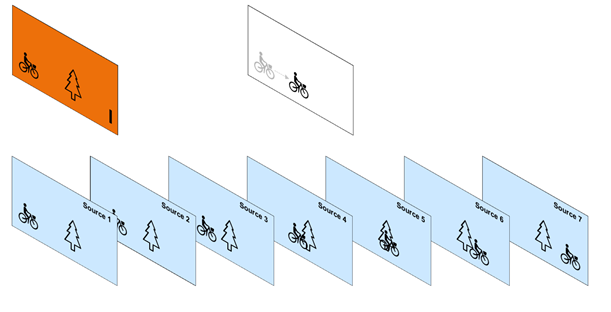
Looking at the subsequent frames, one would notice that there is a lot of redundant information. For instance, the tree is still present in all the frames and the bicycle is represented as a translation from one frame to the next. In order to take advantage of the temporal redundancy that is inherent in video, MPEG has defined new types of frames called Predicted-Frame (P-Frame) and Bi-predictive Frame (B-Frame).
How do P-frames get encoded? Consider a second frame somewhere further in the sequence and use the first I-frame as a reference:

MPEG algorithms employ a technique called motion estimation to figure out translation of macroblocks between these frames. Using this information, it forms a frame that is called motion-compensated frame that basically translates the macroblocks from the first frame according to the motion estimation results. Then it takes the difference between the selected frame and its motion-compensated counterpart and encodes that difference using techniques that are similar to JPEG:
Each macroblock in this frame can be encoded either as an I-macroblock or as a P-macroblock. An I-macroblock is encoded just like a macroblock in an I-frame. A P-macroblock is encoded as an area of the past reference picture, plus an error term (the difference between two macroblocks). So, the pixels that didn’t change are not created again, but are referenced from the I-frame (see below):
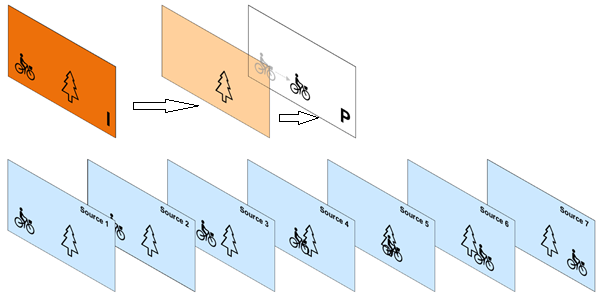
P-frames offer better compression than I-frames because they take advantage of temporal and spatial compression and use fewer bits within a video stream.
Next, the encoder chooses a frame that’s between the I-frame and a first P-frame:
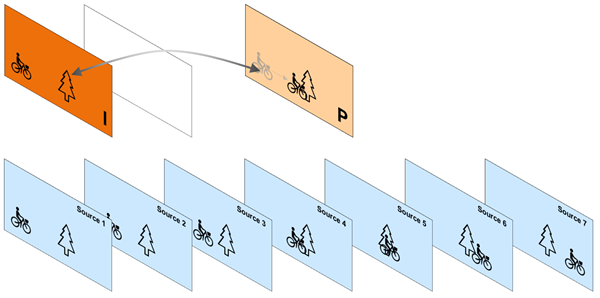
Like P-frames, this frame is expressed as motion vectors and transform coefficients. But the motion analysis is done bi-directionally looking at the preceding I-frame and the following P- frame. All of the other processing is similar to what we described for P-frames:

This type of frame is called a bi-directional predictive frame or B-frame. B‑frames can use both previous and forward frames for data reference to get the highest amount of data compression.
Moving further into the sequence. The encoder creates another predictive frame, and in this case, it may get information from the preceding P-frame and the I-frame.
And the process is repeated to fill out the sequence with P and B frames until every frame is encoded:

Presentation time stamp (PTS) and decoding time stamp (DTS)
Now the frames need to be presented to the viewer and the order they were shot. To ensure this ordering, a presentation timestamp is assigned to each frame:

But the frames need to be reconstructed or decoded in the order they were encoded. First the I-frame was built, then the P-frame were built. Then the B-frames could be built to keep track of this order a decode time stamp is applied to each frame to carry this data:
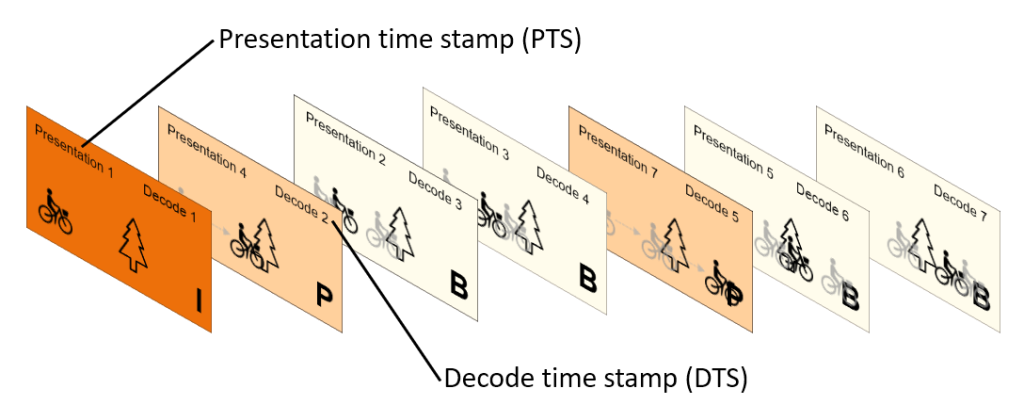
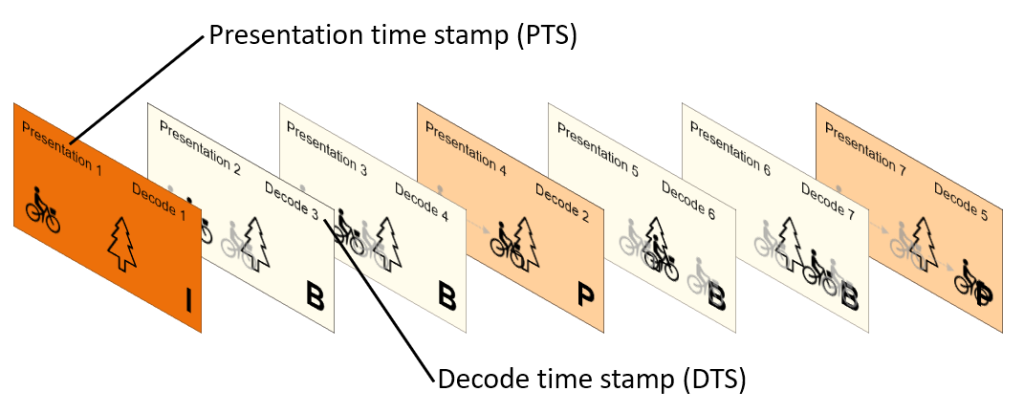
Thus, the decoder will reconstruct the frames in the decode order, and then display them to the viewer in the presentation order for video watching:
Group of Pictures (GOP)
For several reasons (for details please read this blog here), the above sequence of B and P frames can’t be infinite. At some point, an I-frame should be inserted again.
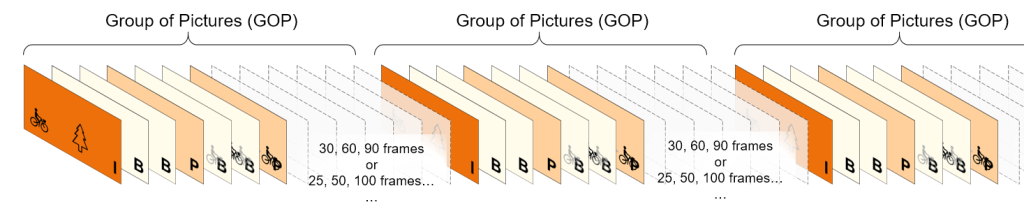
Group of Pictures, or GOP structure, specifies the order in which intra- and inter-frames are arranged. Usually an I-frame indicates the beginning of a GOP.
GOP length/size is the distance between two key frames, measured in the number of frames, or the amount of time between key frames (I-frames).
Ideal GOP length depends on application, but typical group of picture or GOP sizes between I-frames might be 30, 60 or 90 frames or 25, 50 or 100 frames depending on region.
The GOP runs from an I-frame to the last frame before the next I-frame, then the process is repeated.
Conclusion
We hope that you have a better understanding now of how common compression algorithms work, along with key concepts such as group of pictures, different frame types, PTS, and DTS.
Now that you have a better understanding of how video is encoded and why, we encourage you to explore building your own video workflows with Amazon Web Services (AWS). Purpose-built AWS Media Services like AWS Elemental MediaLive and AWS Elemental MediaConvert are a great place to start.
You can also check out this free one-hour foundational video that breaks down important video technology concepts to help you further understand the processes involved in getting content from its source to the viewer’s screen.