Artificial Intelligence
Process and add additional file formats to your Amazon Kendra Index
If you have a corpus of internal documents that you frequently search through, Amazon Kendra can help you find your content faster and easier. These documents can be in different locations and repositories, and can be structured or unstructured. Amazon Kendra is a fully managed service backed by machine learning (ML). You don’t need to provision or maintain any servers and you don’t need to worry about ML models on the backend.
One of the popular features in Amazon Kendra is natural language question answering. You can query Amazon Kendra in natural language and it returns an answer from within your documents.
As of September 2021, Amazon Kendra accepts the following document types:
- Plaintext
- HTML
- Microsoft PowerPoint
- Microsoft Word
In this post, we show how to add other formats, including RTF and markdown, to your Amazon Kendra indexes. In addition, we demonstrate how you can add additional file formats to your Amazon Kendra cluster.
Solution overview
The following diagram illustrates our architecture.

Our solution has an event-driven serverless architecture with the following steps:
- You place your RTF or markdown files in your Amazon Simple Storage Service (Amazon S3) bucket. This event through AWS CloudTrail invokes Amazon EventBridge.
- EventBridge generates messages and places them in an Amazon Simple Queue Service (Amazon SQS) queue. Using EventBridge along with Amazon SQS provides high availability and fault tolerance, ensuring all the newly placed files in the S3 bucket are processed and added to Amazon Kendra.
- EventBridge also invokes an AWS Lambda function, which in turn starts AWS Step Functions. Step Functions provides serverless orchestration to our solution, which further enhances our high availability and fault tolerance architecture.
- Step Functions makes sure that each newly placed file in Amazon S3 is processed. Step Functions calls Lambda functions to triage and process the files residing in Amazon S3. At this step, we first triage the files based on their extensions and then process each file in a Lambda function. This architecture lets you add support for additional file formats.
- The processing Lambda functions (RTF Lambda and MD Lambda) extract the text from each file, store the extracted text files in Amazon S3, and update the Amazon Kendra cluster.
- After all the files are processed and the SQS queue is empty, all services, except Amazon S3 and Amazon Kendra, shut down.
Customize and enhance the solution
You can easily process additional file types by creating new Lambda functions and adding them to the processing list. All you need to do is change the code slightly for the triage function to include your new file type and create corresponding Lambda functions to process those files.
The following is the code for the triage Lambda function:
Deploy the solution
To deploy the solution, we use an AWS CloudFormation template. Complete the following steps:
- Choose Launch Stack:

- For Stack Name, enter a unique name.
- For LoggingLevel, enter your desired logging level (
DEBUG,INFO, orWARNING). - For Prefix, enter your desired S3 bucket prefix.
We append the AWS account ID to avoid global S3 bucket name collisions.
- For KendraIndex, enter the
IndexId(not the index name) for an existing Amazon Kendra index in your account and Region.
You should use Amazon Kendra Enterprise Edition for production workloads.
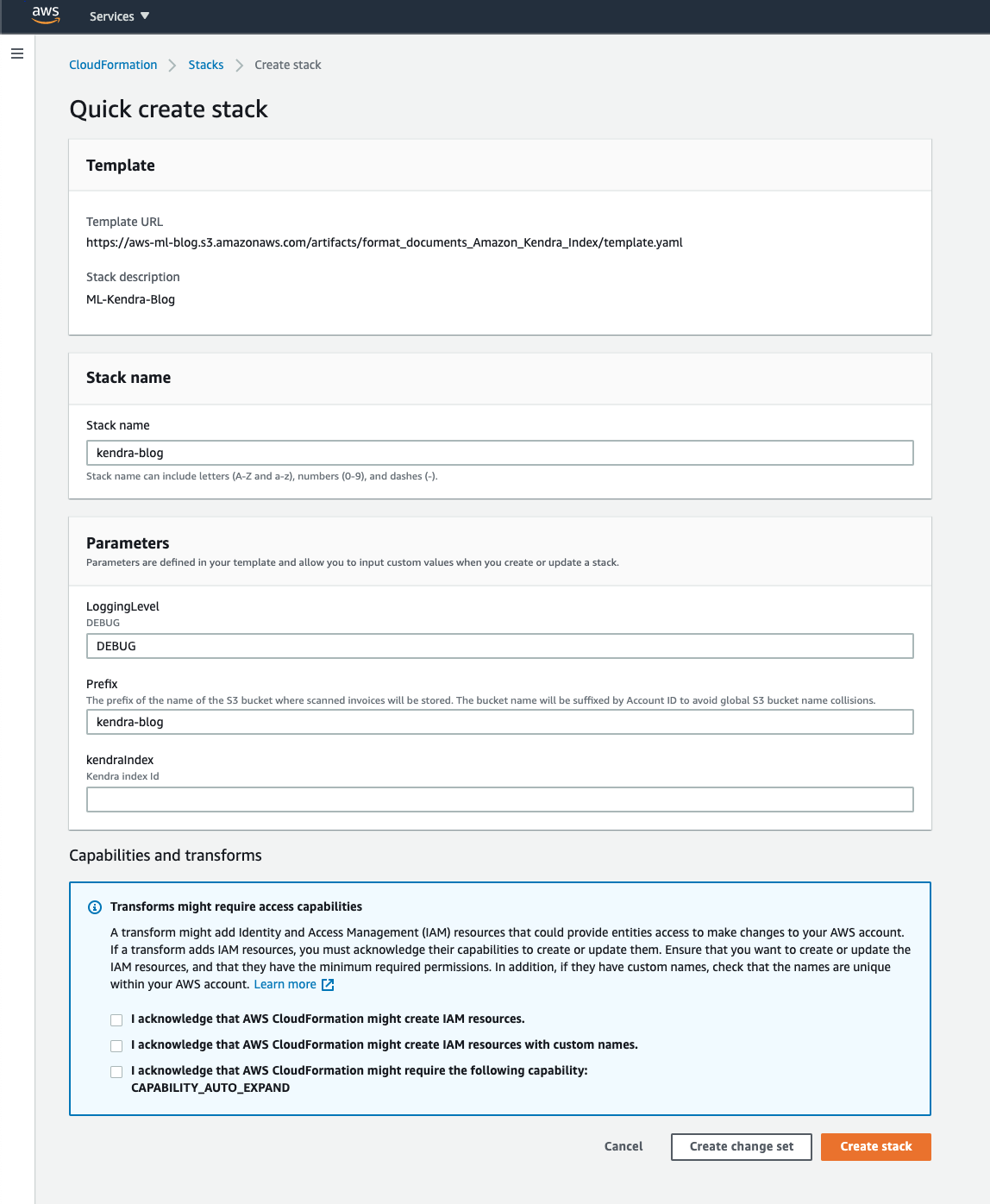
- Select the acknowledgement check boxes, and choose Create Stack.
Excluding the S3 buckets and Amazon Kendra cluster, the AWS CloudFormation stack creates the rest of our resources and gets our solution up and running. You’re now ready to add RTF and markdown files to your Amazon Kendra cluster.
Clean up
To avoid incurring unnecessary charges, you can use the AWS CloudFormation console to delete the stack that you deployed. This removes all the resources you created when deploying the solution. However, the data that resides in Amazon S3 and your Amazon Kendra cluster will not be deleted.
Conclusion
In this post, we presented a highly available fault-tolerant serverless solution to add additional file formats to your Amazon Kendra index. We implemented this solution for RTF and markdown files and provided guidance on how to expand this solution to other similar file formats.
You can use this solution as a starting point for your own solution. For expert assistance, Amazon ML Solutions Lab, AWS Professional Services, and partners are ready to help you in your journey. To learn more about how Amazon Kendra can help your business, visit the website. Learn more about the Amazon ML Solutions Lab and how they can help your business. Contact us today!
About the Authors
 Gaurav Rele is a Data Scientist at the Amazon ML Solution Lab, where he works with AWS customers across different verticals to accelerate their use of machine learning and AWS Cloud services to solve their business challenges.
Gaurav Rele is a Data Scientist at the Amazon ML Solution Lab, where he works with AWS customers across different verticals to accelerate their use of machine learning and AWS Cloud services to solve their business challenges.
 Sia Gholami is a Senior Data Scientist at the Amazon ML Solutions Lab, where he builds AI/ML solutions for customers across various industries. He is passionate about natural language processing (NLP) and deep learning. Outside of work, Sia enjoys spending time in nature and playing tennis.
Sia Gholami is a Senior Data Scientist at the Amazon ML Solutions Lab, where he builds AI/ML solutions for customers across various industries. He is passionate about natural language processing (NLP) and deep learning. Outside of work, Sia enjoys spending time in nature and playing tennis.